The NVIDIA Turing GPU Architecture Deep Dive: Prelude to GeForce RTX
by Nate Oh on September 14, 2018 12:30 PM ESTRay Tracing 101: What It Is & Why NVIDIA Is Betting On It
Because one of the two cornerstone technologies of the Turing architecture is NVIDIA’s ray tracing RT cores, before we dive too much into the Turing architecture, it’s perhaps best to start with a discussion on just what ray tracing is. And equally important, why NVIDIA is betting so much silicon on it.
Ray tracing, in short, is a rendering process that emulates how light behaves in the real world. From a fundamental (but not quite quantum physics) level, light can be considered to behave like a ray. This is because photons, outside other influences, will travel in a straight line until they hit something. At which point various interactions (reflection, refraction, etc) occur between photons and the object.

The catch with ray tracing is that it’s expensive. Incredibly expensive. The scale of the problem means that if you take a naïve approach and try to calculate all of the rays of photons emitting from every light source in a scene, you’re going to be tracing an uncountable, near-infinite number of rays bouncing around a scene. It is essentially modeling all of the physical interactions of light within a bounded space, and that’s an incredible number of interactions.
As a result there have been a number of optimizations developed for ray tracing over the years. Perhaps the most important of which is sort of turning the naïve concept on its head, and instead of tracing rays starting from light sources, you instead go backwards. You trace rays starting from the point of the observer – essentially casting them out into a scene – so that you only end up calculating the light rays that actually reach the camera.
Such “reverse” ray tracing cuts down on the problem space significantly. It also means that conceptually, ray tracing can be thought of as a pixel-based method; the goal is to figure out what each pixel should be.
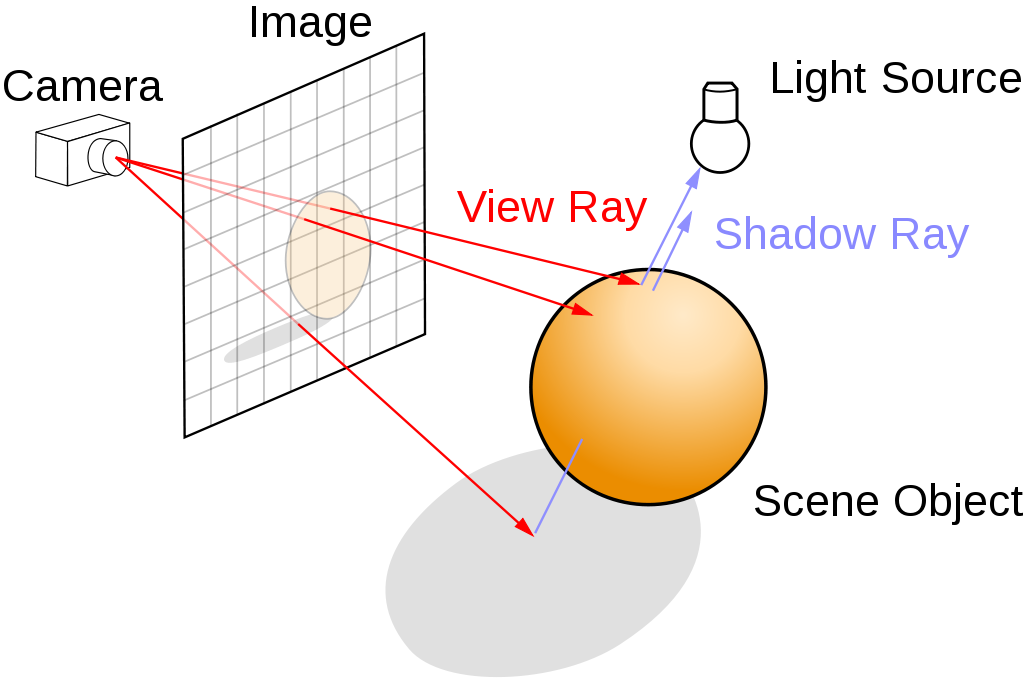
Ray Tracing Diagram (Henrik / CC BY-SA 4.0)
However even with this optimization and others, ray tracing is still very expensive. These techniques make ray tracing cheap enough that it can be done on a computer in a reasonable amount of time, where “reasonable” is measured in minutes or hours, depending on the scene and just how precise and clean you want the rendered frame to be. As a result, anything other than the cheapest, grainiest ray tracing has been beyond the reach of real-time rendering.
In practical terms then, up until now ray tracing has been reserved purely for “offline” scenarios, particularly 3D graphics in movies. The quality of ray tracing makes it second to none – it’s emulating how light actually works, after all – as it can accurately calculate reflections, shadows, light diffusion, and other effects to a degree of accuracy that no other method can. But doing all of this comes at a heavy cost.

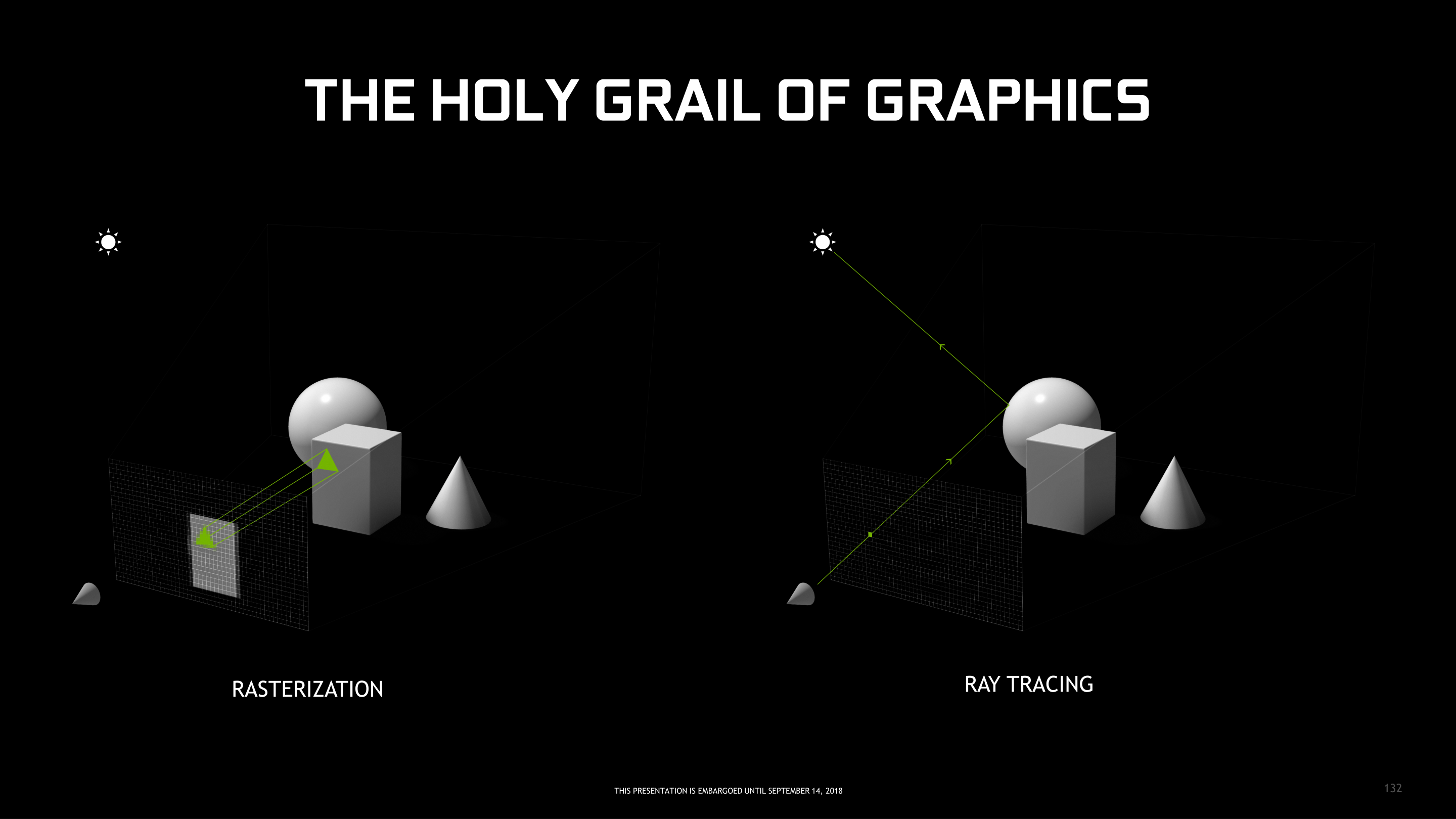
Enter Rasterization: The World’s Greatest Hack
The high computational cost of ray tracing means that it hasn’t been viable for real-time graphics. Instead, since the earliest of days, the computing industry has turned to rasterization.
If ray tracing is a pixel-based approach, then rasterization would be called a polygon-centric approach to 3D rendering. But more than that, rasterization is a hack – a glorious hack to get around the fact that computers aren’t (or at least, weren’t) fast enough to do real-time ray tracing. Rasterization takes a number of shortcuts and makes a number of assumptions about how light, objects, and materials work in order to reduce the computational workload for rendering a scene down to something that can be done in real time.
Rasterization at its most basic level is the process of taking the polygons in a scene and mapping them to a 2D plane, the pixel grid. This means polygons are sorted and tested to see which polygons are actually visible, and then in various stages, these polygons are textured, shaded, and otherwise processed to determine their final color. And admittedly this is a gross simplification of a process that was already a simplification – I’m completely ignoring all the math that goes into transforming 3D objects into a 2D representation – but in an amusing twist of fate, the hack that is rasterization is in some ways more complex than the natural process of ray tracing.
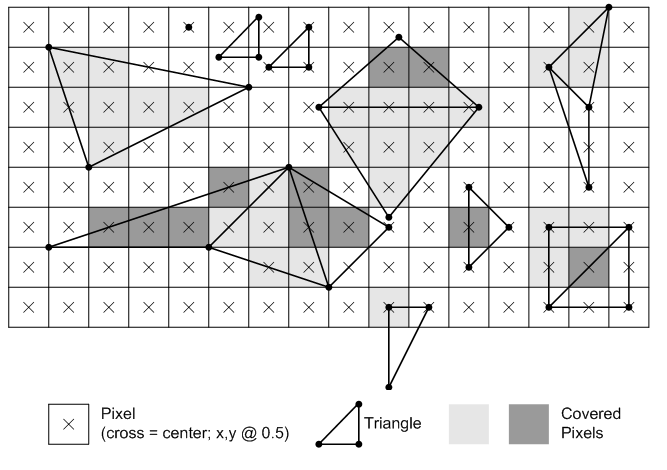
The key point to rasterization is not so much how it works, but rather that it doesn’t use rays, and therefore it’s cheap. Very cheap. And better still, it can be done in parallel. As a result GPUs have arisen as incredible matrix multiplication machines, and are capable of testing hundreds of millions of polygons every second and coloring billions of pixels. With a few exceptions, rasterization is nice and orderly, allowing computational techniques like Single Instruction Multiple Data/Thread (SIMD/SIMT) to do the necessary processing with incredible efficiency.
The catch to rasterization is that because it’s a hack – however glorious it is – at the end of the day there are limitations to how well it can fake how vision and light work in the real world. Past basic polygon projection and texturing, pixel shading is where most of the work is done these days to actually determine what color a pixel needs to be. It’s in pixel shaders that the various forms of lighting (shadows, reflection, refraction, etc) are emulated, where distortion effects are calculated, etc. And pixel shaders, while powerful in their own right, are not capable of emulating real light to a high degree, at least not in a performant manner.
It’s these limitations that lead to the well-publicized drawbacks in rasterization. The unnatural light, the limited reflections, the low resolution shadows, etc. Now conceptually, it is by no means impossible to resolve these issues with rasterization. However the computational cost of doing so is very high, as the nature of rasterization is such that it’s difficult to bolt on such high accuracy methods on to what’s at its core a hack. Rasterization is meant to be quick & dirty, not accurate.
Ray Tracing Returns – Hybridization
Coming full-circle then, we reach the obvious question: if rasterization is so inaccurate, how are games meant to further improve their image quality? Certainly it’s possible to continue going down the road of rasterization, and even if the problem gets harder, image quality will get better. But keeping in mind that rasterization is a hack, it’s good to periodically look at what that hack is trying to achieve and whether that hack is worth the trade-offs.
Or to put this another way: if you’re going to put in this much effort just to cheat, maybe it would be better to put that effort into accurately rendering a scene to begin with?
Now in 2018, the computing industry as a whole is starting to ask just that question. Ray tracing is still expensive, but then so are highly accurate rasterization methods. So at some point it may make more sense to just do ray tracing at certain points rather than to hack it. And it’s this train of thought that NVIDIA is pursuing with great gusto for Turing.
For NVIDIA, the path forward is no longer pure rasterization. Instead their world view is one of hybrid rendering: combining the best parts of rasterization and compute with the best parts of ray tracing. Just what those parts are and where they should be done is a question ultimately up to developers, but at a high level, the idea NVIDIA is putting forth is to use ray tracing where it makes sense – for lighting, shadows, and everything else involving the interaction of light – and then using traditional rasterization-based methods for everything else.

This means that rather than immediately jumping from rasterization to ray tracing and losing all of the performance benefits of the former, developers can enjoy the best of both worlds, choosing how they want to balance the performance of rasterization with the quality of ray tracing. The examples NVIDIA and its partners have pitched thus far have been the low-hanging fruit – accurate real-time reflections, improved transparency, and better global illumination – but the use cases conceivably be extended to any kind of lighting-related operation. And perhaps, for the John Carmacks and Tim Sweeneys of the world, possibly something a lot more unorthodox.
With all of that said however, just because hybrid rasterization and ray tracing looks like a good idea on paper, that doesn’t mean it’s guaranteed to work well in practice. Certainly this initiative spans far more than just NVIDIA – Microsoft’s DXR API is a cornerstone that everyone can build from – however to call this the early days would be an overstatement. NVIDIA, Microsoft, and other companies are going to have to build an ecosystem essentially from scratch. And they’re not only going to have to sell developers on the merits of ray tracing, but they’re going to have to teach developers on how to implement it in an efficient manner. Neither of these are easy tasks. After all, ray tracing is not the only way forward, it’s merely one way forward. And, if you agree with NVIDIA, the most promising way forward.
But for today, let’s table the discussion of the merits of ray tracing. NVIDIA has made their move, and indeed the decisions that lead to Turing would have happened years ago. So instead, let’s take a look at how NVIDIA is going to transform their goals into reality by building hardware units specifically for ray tracing.








{kind=link}
111 Comments
View All Comments
BurntMyBacon - Monday, September 17, 2018 - link
Good article. I would have been nice to get more information as to exactly what nVidia is doing with the RT cores to optimize ray tracing, but I can understand why they would want to keep that a secret at this point. One oversight in an otherwise excellent article:@Nate Oh (article): "The net result is that with nearly every generation, the amount of memory bandwidth available per FLOP, per texture lookup, and per pixel blend has continued to drop. ... Turing, in turn, is a bit of an interesting swerve in this pattern thanks to its heavy focus on ray tracing and neural network inferencing. If we're looking at memory bandwidth merely per CUDA core FLOP, then bandwidth per FLOP has actually gone up, since RTX 2080 doesn't deliver a significant increase in (on-paper) CUDA core throughput relative to GTX 1080."
The trend has certainly been downward, but I was curious as to why the GTX 780 wasn't listed. When I checked it out, I found that it is another "swerve" in the pattern similar to the RTX2080. The specifications for the NVIDIA Memory Bandwidth per FLOP (In Bits) chart are:
GTX 780 - 0.58 bits | 3.977 TFLOPS | 288GB/sec
This is easily found information and its omission is pretty noticeable (at least to me), so I assume it got overlooked (easy to do in an article this large). While it doesn't match your initial always downward observation, it also clearly doesn't change the trend. It just means the trend is not strictly monotonic.
nboelter - Tuesday, September 18, 2018 - link
I had to solve the problem of “random memory accesses from the graphics card memory are the main bottleneck for the performance of the molecular dynamics simulation” when i did some physics on CUDA, and got great results with Hilbert space-filling curves (there is a fabulous german paper from 1891 about this newfangled technology) to - essentially - construct BVHs. Only difference really is that i had grains of sand instead of photons. Now i really wonder if these RT cores could be used for physics simulations!webdoctors - Tuesday, September 18, 2018 - link
This will likely get lost in the 100 comments, but this is really huge and getting ignored by the pricing.I've often wondered and complained for years to my friends why we keep going to higher resolutions from 720p to 4K rather than actually improving the graphics. Look at a movie on DVD from 20 yrs ago at 480p resolution, and the graphics are so much more REALISTSIC than the 4K stuff you see in games today because its either real ppl on film or if CG raytraced offline with full lighting. Imagine getting REAL TIME renders that look like real life video, that's a huge breakthrough. Sure we've raytracing for decades, but never real time on non-datacenter size clusters.
Rasterization 4K or 8K content will never look as REAL as 1080p raytraced content. It might look nicer, but it won't look REAL. Its great we'll have hardware where we can choose whether we want to use the fake rasterization cartoony path or the REAL path.
A 2080TI that costs $1200 will be $120 in 10 years, but it won't change the fact that now you're getting REAL vs fake. 2 years ago, you didn't have the option, you couldn't say I'll pay you $5k to give me the ray traced option in the game, now we'll get (hopefully) developer support and see this mainstream. Probably can use AWS to gamestream this instead of buying a video card and than get the raytrace now too.
If you're happy with non-ray tracing, just buy a 1070 and stick to playing games in 1080p. You'll never be perf limited for any games and move on.
eddman - Wednesday, September 19, 2018 - link
You are not getting REAL with 20 series, not even close.MadManMark - Wednesday, September 19, 2018 - link
His point is that we are getting CLOSER to "real," not that it is CLOSE or IS real. Would have thought that was obvious, but guess ti isn't to everyone.eddman - Thursday, September 20, 2018 - link
It seems you are the one who misread. From his comment: "it won't change the fact that now you're getting REAL vs fake"So, yes, he does think with 20 series you get the REAL thing.
sudz - Wednesday, September 19, 2018 - link
"as opposed Pascal’s 2 partition setup with two dispatch ports per sub-core warp scheduler."So in conclusion: RTX has more warp cores.
Engage!
ajp_anton - Friday, September 21, 2018 - link
This comment is a bit late, but your math for memory efficiency is wrong.If bandwidth+compression gives a 50% increase, and bandwidth alone is a 27% increase, you can't just subtract them to get the compression increase. In this example, compression increase is 1.5/1.27 = 1,18, or 18%. Not the 23% that you get by subtracting.
This also means you have to re-write the text where you think it's weird how this is higher than the last generation increase, because it no longer is higher.
Overmind - Thursday, September 27, 2018 - link
There are many inconsistencies in the article.Overmind - Thursday, September 27, 2018 - link
If the 102 with 12 complete functional modules has 72 RTCs (RTX-ops) how can the 2080 Ti with 11 functional modules has 78 RTCs ? The correct value is clearly 68.