The Intel 9th Gen Review: Core i9-9900K, Core i7-9700K and Core i5-9600K Tested
by Ian Cutress on October 19, 2018 9:00 AM EST- Posted in
- CPUs
- Intel
- Coffee Lake
- 14++
- Core 9th Gen
- Core-S
- i9-9900K
- i7-9700K
- i5-9600K
CPU Performance: Office Tests
The Office test suite is designed to focus around more industry standard tests that focus on office workflows, system meetings, some synthetics, but we also bundle compiler performance in with this section. For users that have to evaluate hardware in general, these are usually the benchmarks that most consider.
All of our benchmark results can also be found in our benchmark engine, Bench.
PCMark 10: Industry Standard System Profiler
Futuremark, now known as UL, has developed benchmarks that have become industry standards for around two decades. The latest complete system test suite is PCMark 10, upgrading over PCMark 8 with updated tests and more OpenCL invested into use cases such as video streaming.
PCMark splits its scores into about 14 different areas, including application startup, web, spreadsheets, photo editing, rendering, video conferencing, and physics. We post all of these numbers in our benchmark database, Bench, however the key metric for the review is the overall score.

As a general mix of a lot of tests, the new processors from Intel take the top three spots, in order. Even the i5-9600K goes ahead of the i7-8086K.
Chromium Compile: Windows VC++ Compile of Chrome 56
A large number of AnandTech readers are software engineers, looking at how the hardware they use performs. While compiling a Linux kernel is ‘standard’ for the reviewers who often compile, our test is a little more varied – we are using the windows instructions to compile Chrome, specifically a Chrome 56 build from March 2017, as that was when we built the test. Google quite handily gives instructions on how to compile with Windows, along with a 400k file download for the repo.
In our test, using Google’s instructions, we use the MSVC compiler and ninja developer tools to manage the compile. As you may expect, the benchmark is variably threaded, with a mix of DRAM requirements that benefit from faster caches. Data procured in our test is the time taken for the compile, which we convert into compiles per day.
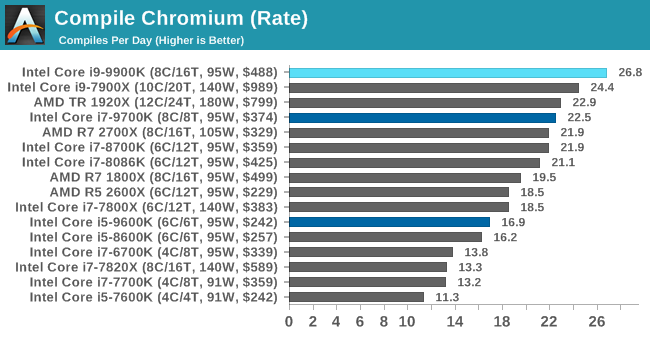
Pushing the raw frequency of the all-core turbo seems to work well in our compile test.
3DMark Physics: In-Game Physics Compute
Alongside PCMark is 3DMark, Futuremark’s (UL’s) gaming test suite. Each gaming tests consists of one or two GPU heavy scenes, along with a physics test that is indicative of when the test was written and the platform it is aimed at. The main overriding tests, in order of complexity, are Ice Storm, Cloud Gate, Sky Diver, Fire Strike, and Time Spy.
Some of the subtests offer variants, such as Ice Storm Unlimited, which is aimed at mobile platforms with an off-screen rendering, or Fire Strike Ultra which is aimed at high-end 4K systems with lots of the added features turned on. Time Spy also currently has an AVX-512 mode (which we may be using in the future).
For our tests, we report in Bench the results from every physics test, but for the sake of the review we keep it to the most demanding of each scene: Ice Storm Unlimited, Cloud Gate, Sky Diver, Fire Strike Ultra, and Time Spy.
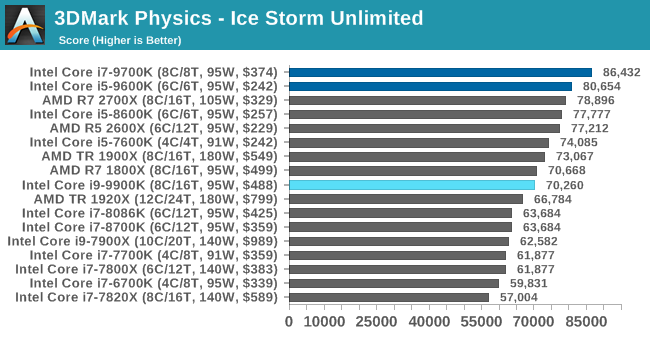
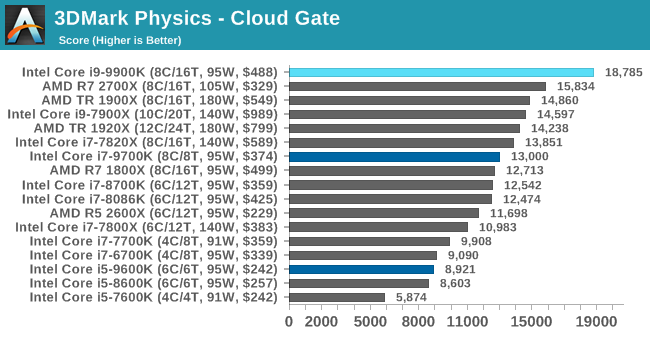
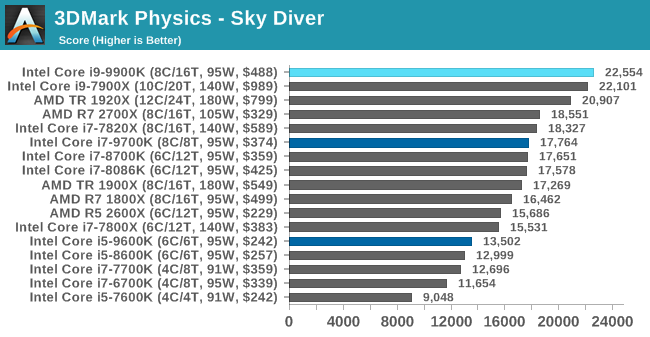

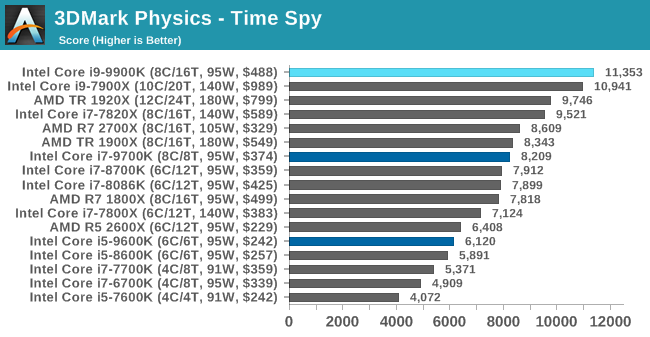
The older Ice Storm test didn't much like the Core i9-9900K, pushing it back behind the R7 1800X. For the more modern tests focused on PCs, the 9900K wins out. The lack of HT is hurting the other two parts.
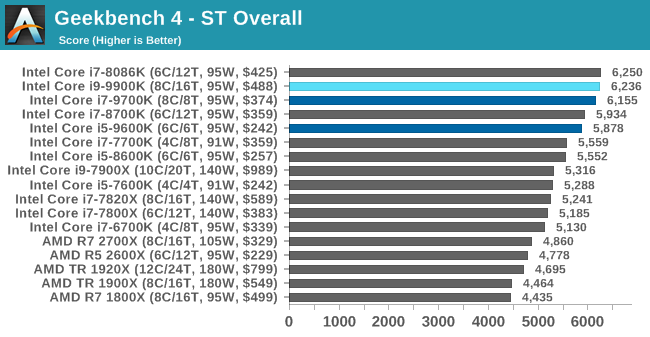
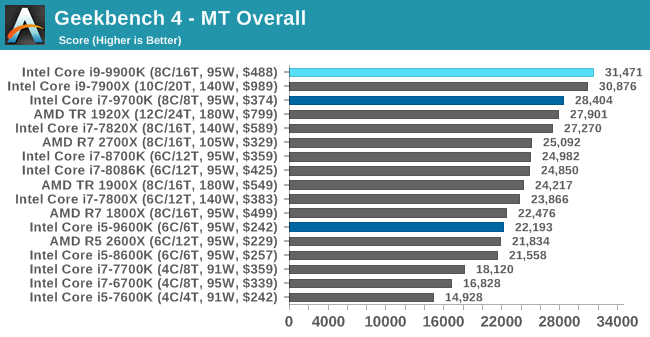
GeekBench4: Synthetics
A common tool for cross-platform testing between mobile, PC, and Mac, GeekBench 4 is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers).
We record the main subtest scores (Crypto, Integer, Floating Point, Memory) in our benchmark database, but for the review we post the overall single and multi-threaded results.








274 Comments
View All Comments
Total Meltdowner - Sunday, October 21, 2018 - link
Those typoes.."Good, F U foreigners who want our superior tech."
muziqaz - Monday, October 22, 2018 - link
Same to you, who still thinks that Intel CPUs are made purely in USA :DHifihedgehog - Friday, October 19, 2018 - link
What do I think? That it is a deliberate act of desperation. It looks like it may draw more power than a 32-Core ThreadRipper per your own charts.https://i.redd.it/iq1mz5bfi5t11.jpg
AutomaticTaco - Saturday, October 20, 2018 - link
Revisedhttps://www.anandtech.com/show/13400/intel-9th-gen...
The motherboard in question was using an insane 1.47v
https://twitter.com/IanCutress/status/105342741705...
https://twitter.com/IanCutress/status/105339755111...
edzieba - Friday, October 19, 2018 - link
For the last decade, you've had the choice between "I want really fast cores!" and "I want lots of cores!". This is the 'now you can have both' CPU, and it's surprisingly not in the HEDT realm.evernessince - Saturday, October 20, 2018 - link
It's priced like HEDT though. It's priced well into HEDT. FYI, you could have had both of those when the 1800X dropped.mapesdhs - Sunday, October 21, 2018 - link
I noticed initially in the UK the pricing of the 9900K was very close to the 7820X, but now pricing for the latter has often been replaced on retail sites with CALL. Coincidence? It's almost as if Intel is trying to hide that even Intel has better options at this price level.iwod - Friday, October 19, 2018 - link
Nothing unexpected really. 5Ghz with "better" node that is tuned for higher Frequency. The TDP was the real surprise though, I knew the TDP were fake, but 95 > 220W? I am pretty sure in some countries ( um... EU ) people can start suing Intel for misleading customers.For the AVX test, did the program really use AMD's AVX unit? or was it not optimised for AMD 's AVX, given AMD has a slightly different ( I say saner ) implementation. And if they did, the difference shouldn't be that big.
I continue to believe there is a huge market for iGPU, and I think AMD has the biggest chance to capture it, just looking at those totally playable 1080P frame-rate, if they could double the iGPU die size budget with 7nm Ryzen it would be all good.
Now we are just waiting for Zen 2.
GreenReaper - Friday, October 19, 2018 - link
It's using it. You can see points increased in both cases. But AMD implemented AVX on the cheap. It takes twice the cycles to execute AVX operations involving 256-bit data, because (AFAIK) it's implemented using 128-bit registers, with pairs of units that can only do multiplies or adds, not both.That may be the smart choice; it probably saves significant space and power. It might also work faster with SSE[2/3/4] code, still heavily used (in part because Intel has disabled AVX support on its lower-end chips). But some workloads just won't perform as well vs. Intel's flexible, wider units. The same is true for AVX-512, where the workstation chips run away with it.
It's like the difference between using a short bus, a full-sized school bus, and a double decker - or a train. If you can actually fill the train on a regular basis, are going to go a long way on it, and are willing to pay for the track, it works best. Oh, and if developers are optimizing AVX code for *any* CPU, it's almost certainly Intel, at least first. This might change in the future, but don't count on it.
emn13 - Saturday, October 20, 2018 - link
Those AVX numbers look like they're measuing something else; not just AVX512. You'd expect performance to increase (compared to AVX256) by around 50%, give or take quite a margin of error. It should *never* be more than a factor 2 faster. So ignore AMD; their AVX implementation is wonky, sure - but those intel numbers almost have to be wrong. I think the baseline isn't vectorized at all, or something like that - that would explain the huge jump.Of course, AVX512 is fairly complicated, and it's more than just wider - but these results seem extraordinary; and there' just not enough evidence the effect is real, not just some quirk of how the variations were compiled.