896 Xeon Cores in One PC: Microsoft’s New x86 DataCenter Class Machines Running Windows
by Ian Cutress on October 26, 2018 11:00 AM EST- Posted in
- CPUs
- Windows
- Microsoft
- Enterprise CPUs
- Azure

This week Microsoft released a new blog dedicated to the Windows Kernel internals. The purpose of the blog is to dive into the Kernel across a variety of architectures and delve into the elements, such as the evolution of the kernel, the components, the organization, and in this post, the focus was on the scheduler. The goal is to develop the blog over the next few months with insights into what goes on behind the scenes, and the reasons why it does what it does. However, we got a sneak peek into a big system that Microsoft looks like it is working on.
For those that want to read the blog, it’s really good. Take a look here:
https://techcommunity.microsoft.com/t5/Windows-Kernel-Internals/One-Windows-Kernel/ba-p/267142
When discussing the scalability of Windows, the author Hari Pulapaka, Lead Program Manager in the Windows Core Kernel Platform, showcases a screenshot of Task Manager from what he describes as a ‘pre-release Windows DataCenter class machine’ running Windows. Here’s the image:
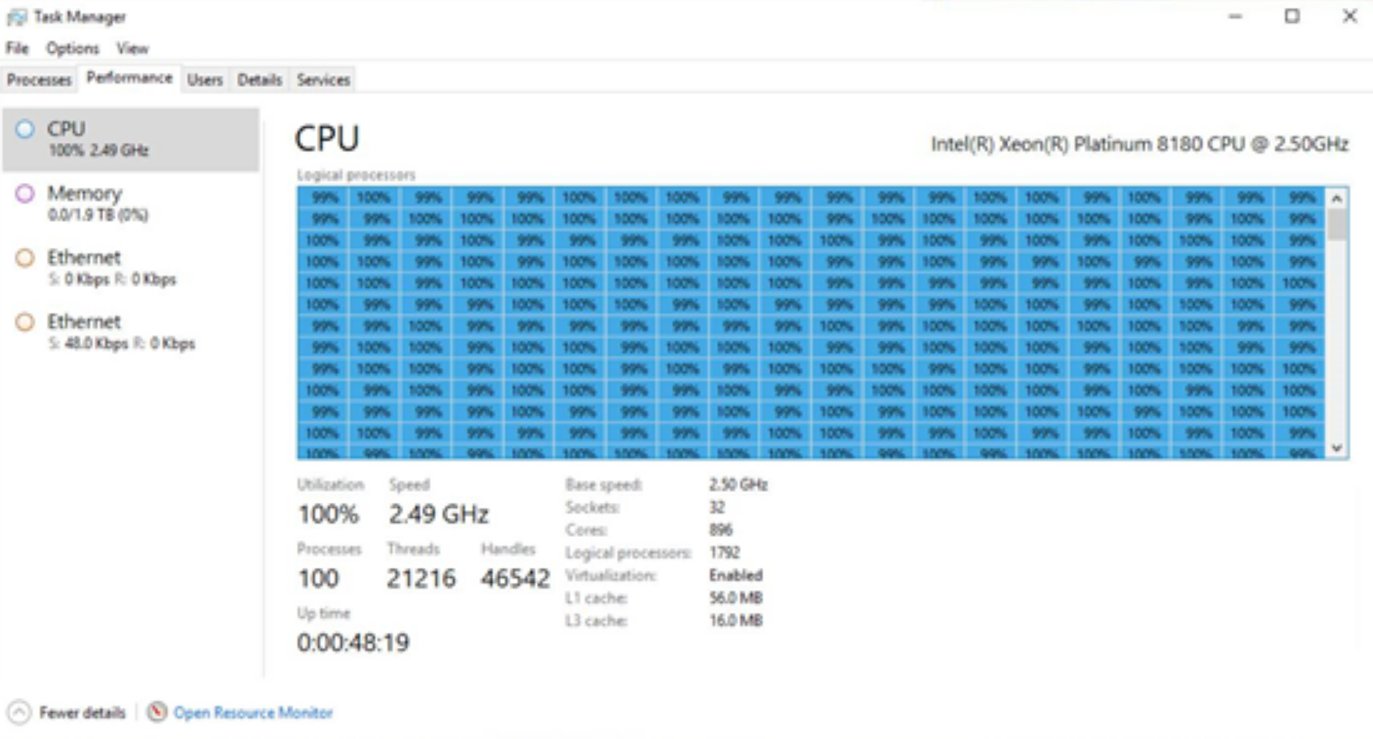
Click to zoom. Unfortunately the original image is low resolution
If you weren’t amazed by the number of threads in task manager, you might notice that on the side there’s a scroll bar. That’s right: 896 cores means 1792 threads when hyperthreading is enabled, which is too much for task manager to show at once, and this new type of ‘DataCenter class machine’ looks like it has access to them all. But what are we really seeing here, aside from every single thread loaded at 100%?
So to start, the CPU listed is a Xeon Platinum 8180, Intel’s highest core count, highest performing Xeon Scalable ‘Skylake-SP’ processor. It has 28 cores and 56 threads, and by math we get a 32 socket system. In fact in the bumf below the threads all running at 100%, it literally says ‘Sockets: 32’. So this is 32 full 28 core processors all acting together under one version of Windows. Again, the question is how?
Normally, Intel only rates Xeon Platinum processors for up to 8 sockets. It does this by using three QPI links per processor to form a dual-box configuration. The Xeon Gold 6100 range does up to four sockets with three QPI links, ensuring each processor is linked to each other processor, and then the rest of the range does single socket or dual socket.
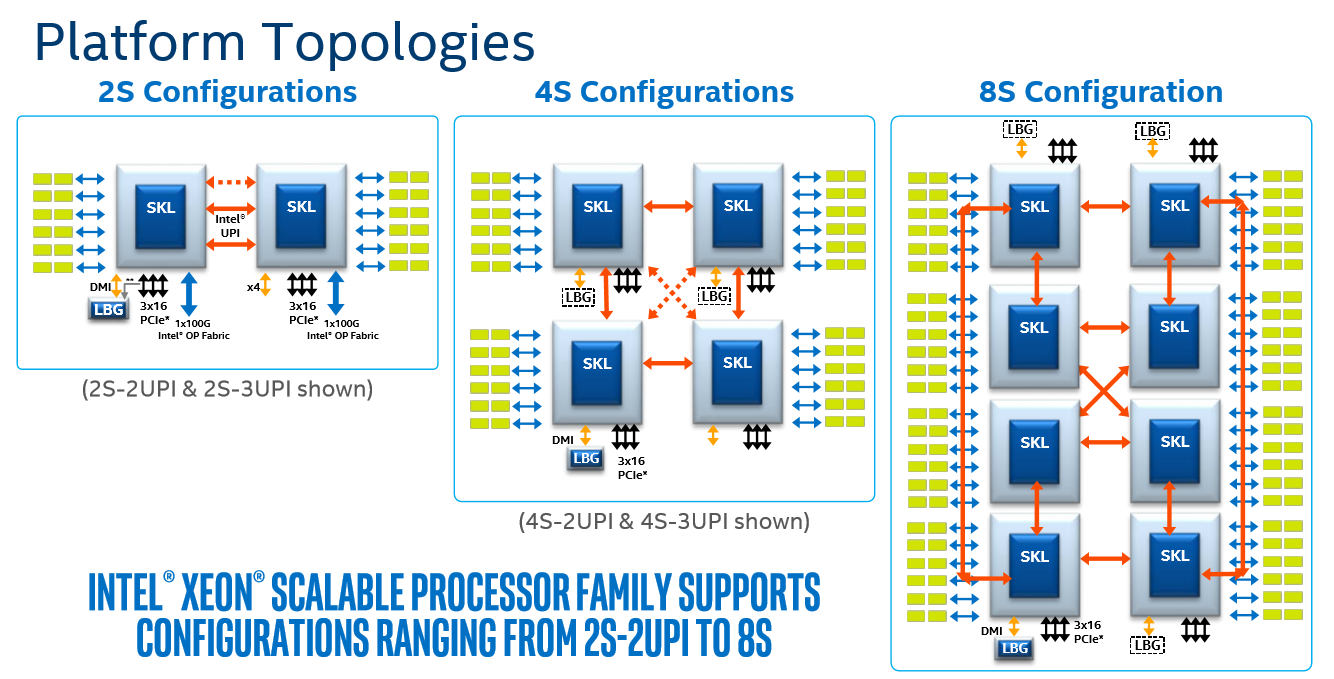
What Intel doesn’t mention is that with an appropriate fabric connecting them, system builders and OEMs can chain together several 4-socket or 8-socket systems into a single, many-socket interface. Aside from the fabric to be used and the messaging, there are other factors in play here, such as latency and memory architecture, which are already present in 2-8 socket platforms but get substantially increased going beyond eight sockets. If one processor needs memory that is two fabric hops and a processor hop is away, to a certain extent having that data in a local SDD might be quicker.
As for the fabric: I’m actually going to use an analogy here. AMD’s EPYC platform goes up to two sockets, but for the interconnect between sockets, it uses 64 PCIe lanes from each processor to host AMD’s Infinity Fabric protocol to act as links, and has the benefit of the combined bandwidth of 128 PCIe lanes. If EPYC had 256 PCIe lanes for example, or cut the number of PCIe lanes down to 32 per link, then we could end up with EPYC servers with more than two sockets built on Infinity Fabric. With Intel CPUs, we’re still using the PCIe lanes, but we’re doing it in one of three ways: control over Omni-Path using PCIe, control over Infiniband using PCIe, or control using custom FPGAs, again over PCIe. This is essentially how modern supercomputers are run, albeit not as one unified system.
Unfortunately this is where we go out of my depth. When I spoke to a large server OEM last year, they said quad socket and eight socket systems are becoming rarer and rarer as each CPU by itself has more cores the need for systems that big just doesn't exist anymore. Back in the days pre-Nehalem, the big eight socket 32-core servers were all the rage, but today not so much, and unless a company is willing to spend $250k+ (before support contracts or DRAM/NAND) on a single 8-socket system, it’s reserved for the big players in town. Today, those are the cloud providers.
In order to get 32 sockets, we’re likely seeing eight quad-socket systems connected in this way in one big blade infrastructure. It likely takes up half a rack, of not a whole one, and your guess is as good as mine on the price, or power consumption. In our screenshot above it does say ‘Virtualization: Enabled’, and given that this is Microsoft we’re talking about, this might be one of their internal planned Azure systems that is either rented to defence-like contractors or partitioned off in instances to others.
I’ve tried reaching out to Hari to get more information on the system this is, and will report back if we get anything. Microsoft may make an official announcement if these large 32-socket systems are going to be 'widespread' (meant in the leanest sense) offerings on Azure.
Note: DataCenter is stylized with a capital C as quoted through Microsoft's blog post.








56 Comments
View All Comments
rahvin - Friday, October 26, 2018 - link
You might be surprised to here this but the majority of companies running machines like this aren't running windows.Shocking I know. This feels a lot like a look what we can do system rather than something anyone but a select few would really want.
kb9fcc - Friday, October 26, 2018 - link
<sarcasm> No, really? </sarcasm> However, besides this CPU behemoth, Microsoft is the central focus of this article.. Can it be done? Sure. But fueled by M$? mehytoledano - Saturday, October 27, 2018 - link
Windows Server 2019 Datacenter costs $6,155 for one 16 core license. 896 cores will cost $344,680vFunct - Saturday, October 27, 2018 - link
At this point you might as well hire 10 Postgres core developers to update postgres for you..Dug - Friday, November 2, 2018 - link
I miss 2012 pricing structureMattZN - Friday, October 26, 2018 - link
It's an accomplishment to be able to connect so many CPUs together and still have a working system. Scaling kernels become more difficult at those core counts due to the fact that even non-contending shared lock latencies start to go through the roof due to the cache ping ponging. (Intel does have their transactional support instructions to help with this, but its a really problematic technology and only works for the simplest bits of code). Plus page table operations for kernel memory itself often winds up having to spam all the cores to synchronize the PTE changes. We've managed to reduce the IPI spamming by two orders of magnitude over the last decade, but having to do it at all creates a real problem on many-cores systems.I agree that it just isn't all that cost effective these days to have more than 2 sockets. The motherboards and form factors are so complex and customized to such a high degree that there just isn't any cost savings to squeeze out beyond 4 sockets. And as we have seen, even 4 sockets has fallen into disfavor as computational power has increased.
I think the future is going to be more an AMD-style chiplet topology, where each cpu 'socket' in the system is actually running a complex of multiple CPU chips inside it, rather than requiring a physical socket for each one. There is no need for motherboards to expand beyond 2 sockets, honestly. Memory and compute density will continue to improve, bandwidth will continue to improve... 4+ socket monsters are just a waste of money when technology is moving this quickly. They are one-off custom jobs that become obsolete literally in less than a year.
-Matt
HStewart - Friday, October 26, 2018 - link
But with AMD designed - it would take a wafer of probably size of 32 in tv to make that happen.Intel has better option for Custom jobs with EMiB - can even hold AMD GPU designed on and HDM2 memory.
MrSpadge - Friday, October 26, 2018 - link
Whatever they do to the scheduler for this beast should also help Epyc with an additional layer of NUMA compared to Intel.mode_13h - Friday, October 26, 2018 - link
What if extending their dual-EPYC scheduler is actually what enabled *this*?Granted, going over OmniPath probably incurs much more latency than talking to another EPYC CPU.
mode_13h - Friday, October 26, 2018 - link
I'd love to hear a good use case for this.As pointed out in the article, the memory latency of accessing data on another blade just doesn't make sense to treat as a single system.