Next Generation Intel Atom Tremont: Potential L3 Cache
by Dr. Ian Cutress on July 15, 2019 8:00 AM EST
Intel has already disclosed that it will have a next generation Atom core, code named Tremont, which is to appear in products such as the Foveros-based hybrid Lakefield, as well as Snow Ridge designed for 5G deployments. In advance of the launch of the core and the product, it is customary for some documentation and tools to be updated to prepare for it; in this case, one of those updates has disclosed that the Tremont core would contain an L3 cache – a first for one of Intel’s Atom designs.

01.org is an Intel website which hosts all of its open source projects. One of those projects is perfmon, a simple performance monitoring tool that can be used by developers to direct where code may be bottlenecked by either throughput, memory latency, memory bandwidth, TLBs, port allocation, or cache hits/misses. In this case, the profiles for Snow Ridge have been uploaded to the platform, and one of the counters provided includes provisions for L3 cache monitoring. This provision is directly listed under the Tremont heading.

Enabling an L3 cache on Atom does two potential things to Intel’s design: it adds power, but also adds performance. By having an L3, it means that data in the L3 is quicker to access than it would be in memory, however there is an idle power hit by having L3 present. Intel can mitigate this by enabling parts of the L3 to be powered on as needed, but there is always a tradeoff. There can also be a hit to die area, so it will be interesting to see how Intel has changed the microarchitecture of it’s Atom design. There is also no indication if the Tremont L3 cache is an inclusive cache, or a non-inclusive cache, or if it can be pre-fetched into, or if it is shared between cores or done on a per-core basis.
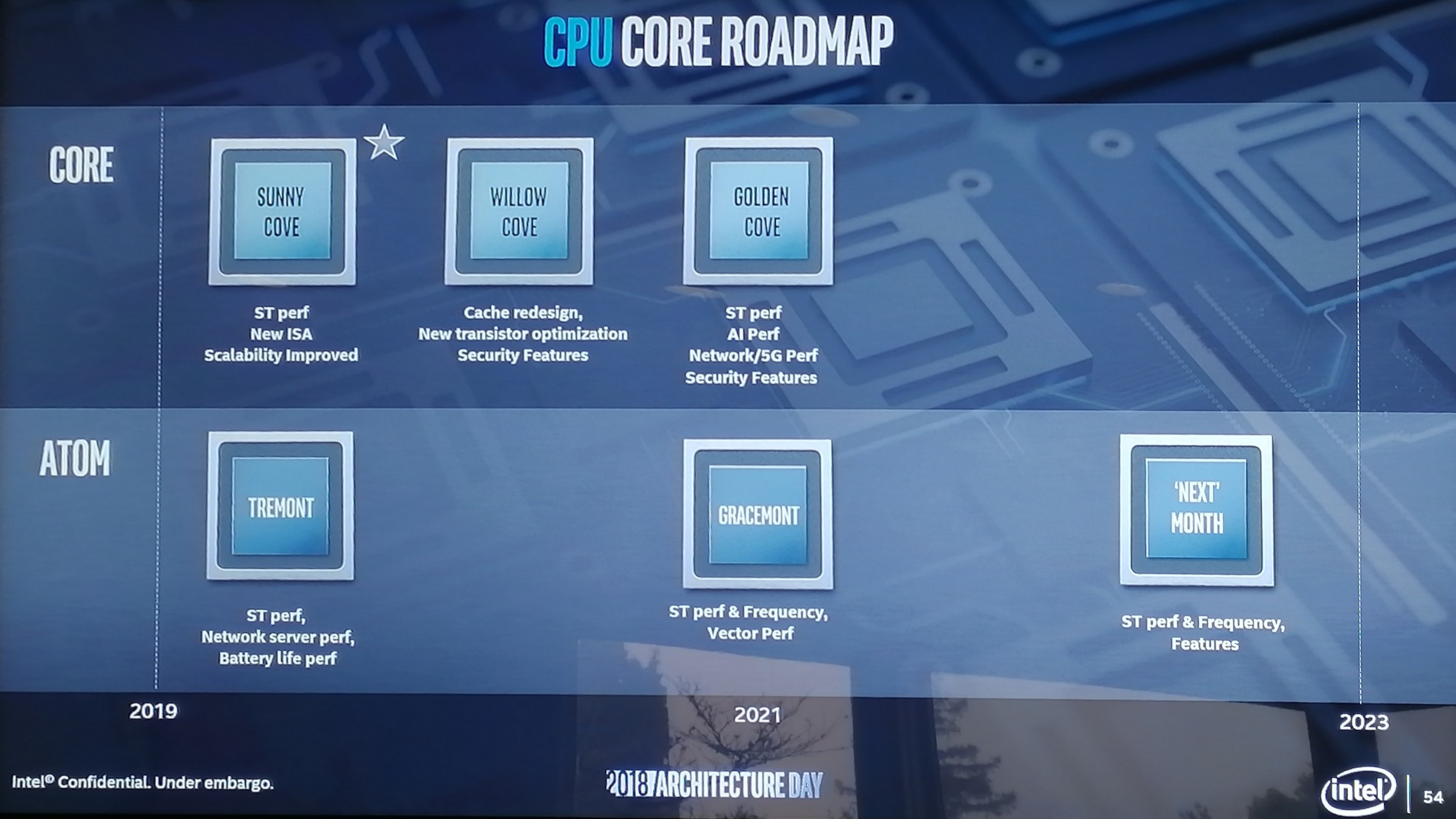
Intel’s Atom roadmap, as disclosed last year at Architecture day, shows that the company is planning several more generations of Atom core, although beyond Tremont we get Gracemont in 2021, and beyond that is ‘increased ST Perf, Frequency, Features’ listed around 2023. In that time, Intel expects to launch Sunny Cove, Willow Cove, and Golden Cove on the Core side.

Lakefield
The first public device with Tremont inside is expected to be the Core/Atom hybrid Lakefield processor, which uses Intel’s new Foveros stacking technology. We know that this design will have one Sunny Cove core and pair it with four Tremont cores. Intel expects chip production of Lakefield for consumer use by the end of the year.
Related Reading
- Intel's Architecture Day 2018: The Future of Core, Intel GPUs, 10nm, and Hybrid x86
- Intel Lists New Atom Core: Tremont to Come After Goldmont Plus
- Intel’s Keynote at CES 2019: 10nm, Ice Lake, Lakefield, Snow Ridge, Cascade Lake
- Intel's Interconnected Future: Combining Chiplets, EMIB, and Foveros
Source: InstLatX64, 01.org








66 Comments
View All Comments
lmcd - Monday, July 15, 2019 - link
It's not "ARM's x86 emulation," it's a Windows-specific technology. Windows uses a HAL for x86 on x86_64, and they added a similar layer for x86 on ARM. The times when the HAL isn't molasses are when it can drop in an ARM binary instead of an x86, and the binary is doing most of the heavy work. In essence, the "emulation" is fast when it's not emulation.Phynaz - Monday, July 15, 2019 - link
Are you high?III-V - Monday, July 15, 2019 - link
>Enabling an L3 cache on Atom does two potential things to Intel’s design: it adds power, but also adds performance. By having an L3, it means that data in the L3 is quicker to access than it would be in memory, however there is an idle power hit by having L3 present.I'm pretty sure it's a net reduction in power consumption, no? The "only" real reason to not include a cache of any level/size is cost -- and cost is a really big deal.
mode_13h - Monday, July 15, 2019 - link
Is L3 usually SRAM? Perhaps making it DRAM would be a way to tackle both the cost & power issues, while sacrificing just a bit of performance.Thunder 57 - Monday, July 15, 2019 - link
That would seriously kill performance.IntelUser2000 - Tuesday, July 16, 2019 - link
L3 is SRAM unless its otherwise indicated.DRAM for CPU caches are called embedded DRAM or "eDRAM" for short.
DRAM has much higher leakage current because the circuitry requires power just for refreshing data, while its unnecessary for SRAM.
SRAM is also much faster. eDRAM is in a handful of CPUs where absolute capacity trumps everything else. Like eDRAM used in Intel's Iris CPUs. Or IBM's Power CPUs where it already uses so much power.
mode_13h - Wednesday, July 17, 2019 - link
Uh, so help me understand...How is it that modern phones have like 4+ GB of DRAM and yet you're saying power would be an issue for embedding like 0.1% of that?
IntelUser2000 - Wednesday, July 17, 2019 - link
You don't just put DRAM on-die and call it done. It doesn't work that way. You have to make a CPU-process specific DRAM and that's why they call it eDRAM. eDRAM also has lot lower density compared to regular DRAM. It's still better than SRAM in density, but not like order of magnitude(and in case its not clear, 1 order of magnitude = 10x) or greater better. Intel's eDRAM for example had a density advantage of just 3x over their SRAM.Yes you have a point about the power compared to system memory but that power is in addition to being quite a bit slower. You are talking slower in both latency and bandwidth. The density increase isn't enough to displace DRAM anyways.
And reducing power in complex systems require tackling it in multiple areas. Just because its in ok in DRAM doesn't make sense to increase it on the CPU.
Don't assume things without doing more research.
mode_13h - Wednesday, July 17, 2019 - link
Thanks for the explanation.> Don't assume things without doing more research.
Well, I wasn't sure so I asked. You didn't have to answer, but I'm glad you did. Thanks.
Santoval - Tuesday, July 16, 2019 - link
L3 cache is always (or practically always) SRAM based. L4 cache is usually DRAM based. SRAM is much more expensive die area wise, but it's also quite faster and more power efficient than DRAM. DRAM is not fast enough for an L3 cache.Perhaps in the future (STT-)MRAM will instead be used for L4 cache, or maybe even L3 cache. MRAM is almost as fast as SRAM but it's much denser (thus much more cache can fit in each mm^2), it's more power efficient and it's also non volatile. I have no idea if CPU cache non volatility can become a useful feature, but I imagine it might.