AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM EST
If you examine the CPU industry and ask where the big money is, you have to look at the server and datacenter market. Ever since the Opteron days, AMD's market share has been rounded to zero percent, and with its first generation of EPYC processors using its new Zen microarchitecture, that number skipped up a small handful of points, but everyone has been waiting with bated breath for the second swing at the ball. AMD's Rome platform solves the concerns that first gen Naples had, plus this CPU family is designed to do many things: a new CPU microarchitecture on 7nm, offer up to 64 cores, offer 128 lanes of PCIe 4.0, offer 8 memory channels, and offer a unified memory architecture based on chiplets. Today marks the launch of Rome, and we have some of our own data to share on its performance.
Review edited by Dr. Ian Cutress
First Boot
Sixty-four cores. Each core with an improved Zen 2 core, offering ~15% better IPC performance than Naples (as tested in our consumer CPU review), and doubled AVX2/FP performance. The chip has a total of 256 MB of L3 cache, and 128 PCIe 4.0 lanes. AMD's second generation EPYC, in this case the EPYC 7742, is a behemoth.
Boot to BIOS, check the node information.
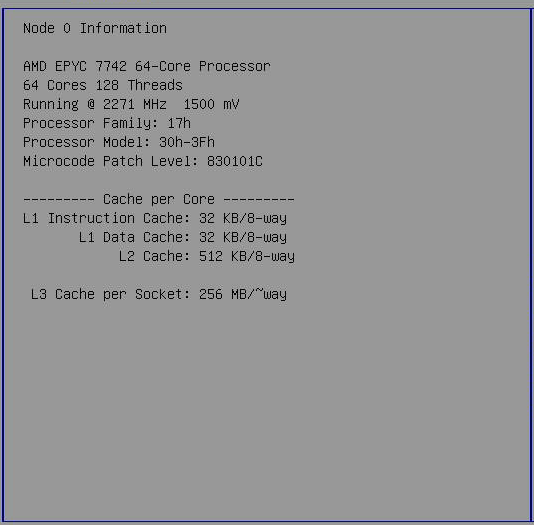
[Note: That 1500 mV reading in the screenshot is the same reading we see on consumer Ryzen platforms; it seems to be the non-DVFS voltage as listed in the firmware, but isn't actually observed]
It is clear that the raw specifications of our new Rome CPU is some of the most impressive on the market. The question then goes to whether or not this is the the new fastest server chip on the market - a claim that AMD is putting all its weight behind. If this is the new fastest CPU on the market, the question then becomes 'by how much?', and 'how much does it cost?'.
I have been covering server CPUs since the launch of the Opteron in 2003, but this is nothing like I have seen before: a competitive core and twice as much of them on a chip than what the competition (Intel, Cavium, even IBM) can offer. To quote AMD's SVP of its Enterprise division, Forrest Norrod:
"We designed this part to compete with Ice Lake, expecting to make some headway on single threaded performance. We did not expect to be facing re-warmed Skylake instead. This is going to be one of the highlights of our careers"
Self-confidence is at all times high at AMD, and on paper it would appear to be warranted. The new Rome server CPUs have improved core IPC, a doubling of the core count at the high end, and it is using a new manufacturing process (7 nm) technology in one swoop. Typically we see a server company do one of those things at a time, not all three. It is indeed a big risk to take, and the potential to be exciting if everything falls into place.

To put this into perspective: promising up to 2x FP performance, 2x cores, and a new process technology would have sounded so odd a few years ago. At the tail end of the Opteron days, just 4-5 years ago, Intel's best CPUs were up to three times faster. At the time, there was little to no reason whatsoever to buy a server with AMD Opterons. Two years ago, EPYC got AMD back into the server market, but although the performance per dollar ratio was a lot better than Intel's, it was not a complete victory. Not only was AMD was still trailing in database performance and AVX/FP performance, but partners and OEMs were also reluctant to partner with the company without a proven product.
So now that AMD has proven its worth with Naples, and AMD promising more than double the deployed designs of Rome with a very quick ramp to customers, we have to compare the old to the new. For the launch of the new hardware, AMD provided us with a dual EPYC 7742 system from Quanta, featuring two 64-core CPUs.








180 Comments
View All Comments
JoeBraga - Wednesday, August 14, 2019 - link
It can happen if Intel uses the new archtecture Sunny Cove and MCM/Chiplet design instead of Monolithic DesignSanX - Thursday, August 15, 2019 - link
7zip is not a legacy test, it is important for anyone who sends big data over always damn slow network. Do you know all those ZIPs, GZs and other zippers which people mostly use, compress with turtle speeds as low as 20 MB/s even on supercomputers ? The 7Zip though parallelizes that nicely. So do not diminish this good test calling it "legacy"imaskar - Friday, August 16, 2019 - link
7zip is a particular program, doing LZMA in parallel, that's why it is faster that lets say gzip. But on server you often do not want to parallel things, because other cores are doing other jobs and switching is costly. There are a lot of compressing algorithms which are better in certain situations. LZMA rarely fits. More often it is it's LZ4 or zstd for "generate once, consume many" or basic gzip (DEFLATE) for "generate once, consume once". Yes, you would be surprised, but the very basic 30 years old DEFLATE is still the king if you care for sum of compress, send, decompress AND your nodes are inside one datacenter (which is most of the times).SanX - Thursday, August 15, 2019 - link
What you can say about Ian's own test he developed to demonstrate avx512 speed boost which shows some crazy up to 3-4x or more speedups ? Does your test of Molecular Dynamics tell that Ian's test mostly irrelevant for such huge improvement of speed of the real life complex programs?imaskar - Friday, August 16, 2019 - link
Probably because you can't use ONLY avx512. You still need regular things like jumps and conditions. And this is only the best case. Usually you also need to process part of the vector differently. For example, your vector has size 20, but your width is 16. You either do another vector pass, or 4 regular computations. Often second thing is faster or just the only option.realbabilu - Sunday, August 18, 2019 - link
Most of finite element software use Intel mkl to get every juice power spec of processor.it works for Intel ones not for amdAmd math kernel not heavily programmed, otnwaa just for Linux.
Other third party like gotoblas openblas still trying hard to detect cache and type for zen2.
I mean for workstation floating point still hard for amd.
peevee - Monday, August 19, 2019 - link
Prices per core-GHz:EPYC 7742 $48.26
EPYC 7702 $50.39
EPYC 7642 $43.25
EPYC 7552 $38.12
EPYC 7542 $36.64
EPYC 7502 $32.50
EPYC 7452 $26.93
EPYC 7402 $26.53
EPYC 7352 $24.46
EPYC 7302 $20.38
EPYC 7282 $14.51
EPYC 7272 $17.96
EPYC 7262 $22.46
EPYC 7252 $19.15
Value in this 7282 is INSANE.
peevee - Tuesday, August 20, 2019 - link
"Even though our testing is not the ideal case for AMD (you would probably choose 8 or even 16 back-ends), the EPYC edges out the Xeon 8176. Using 8 JVMs increases the gap from 1% to 4-5%."1%? 36917 / 27716 = 1.3319...
33%. Without 8 JVMs.
KathyMilligan - Wednesday, August 21, 2019 - link
University of Illinois Urbana-Champaign is very good university. I am too poorly prepared for this level of education. But I'm getting ready. I read a lot of articles and books, communicate with many smart former students of this university. I also buy research papers on site and this gives me a lot of useful information, which is not so easy to find on the Internet.YB1064 - Wednesday, August 28, 2019 - link
Looks like Intel has been outclassed, out-priced and completely out-maneuvered by AMD. What a disaster!