Avantek's Arm Workstation: Ampere eMAG 8180 32-core Arm64 Review
by Andrei Frumusanu on May 22, 2020 8:00 AM ESTThe eMAG 8180: AppliedMicro's Legacy Skylark Core
While you’re reading this in 2020, and the eMAG Workstation had been released in 2019 – the CPU powering the system is actually quite ancient, tracing back its roots in the 2017 defunct AppliedMicro. Originally meant to be called the X-Gene3, the chip had originally been planned for the second half of 2017 before the AppliedMicro had went through several changes of ownership before the IP and designs ended up with Ampere Computing.

In that sense, the eMAG 8180 is more of a legacy design and quite distantly related to Ampere’s newer Altra system processors.
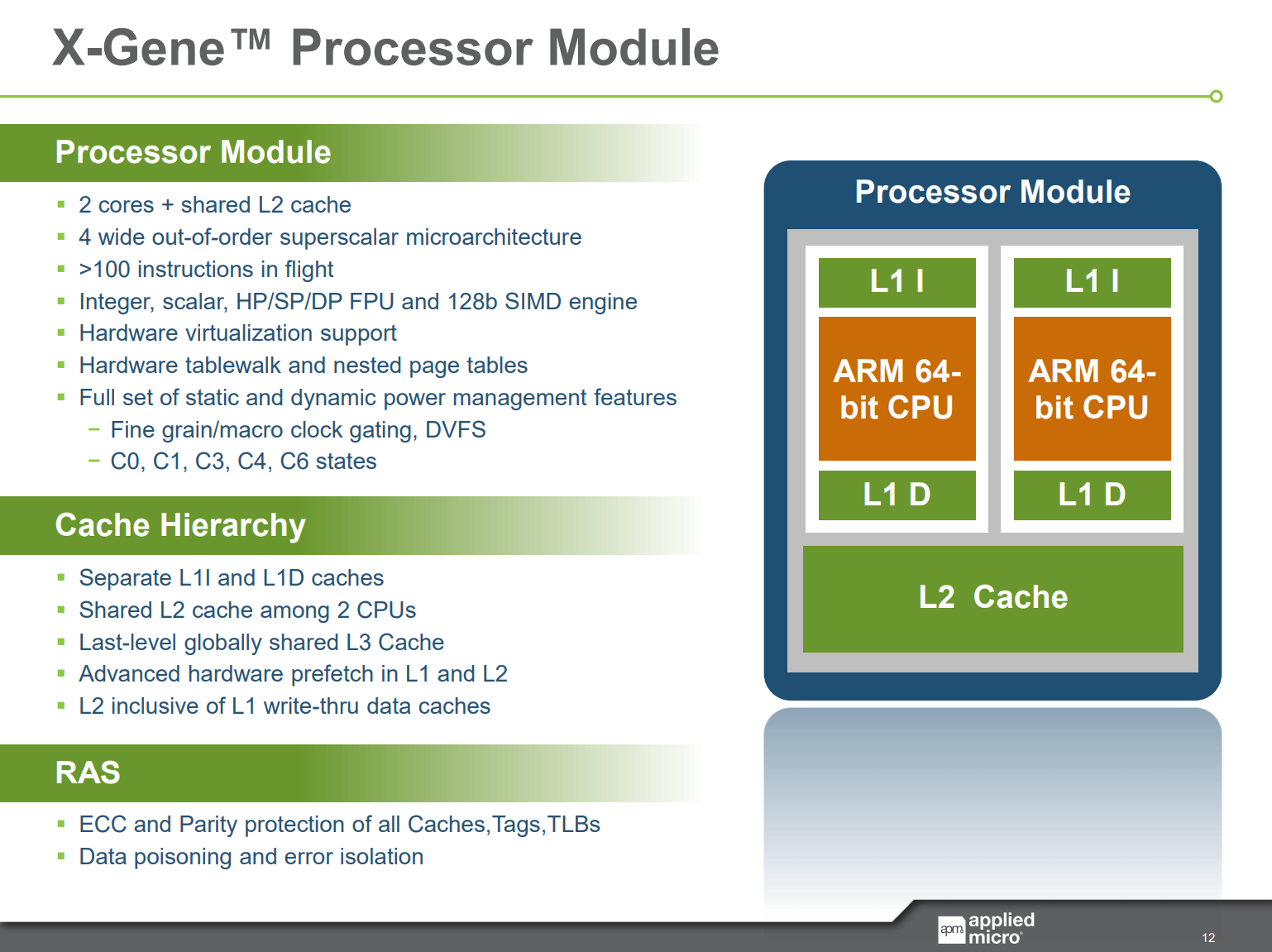
The Skylark cores in the eMAG 8180 are a custom core design having the X-Gene processor pedigree. It’s a 4-wide OOO processor that’s relatively narrow by today’s standards, characterised by quite high operating frequencies up to 3-3.3GHz and quite the unusual cache hierarchy, such as two core pairs sharing the same 256KB L2 cache.
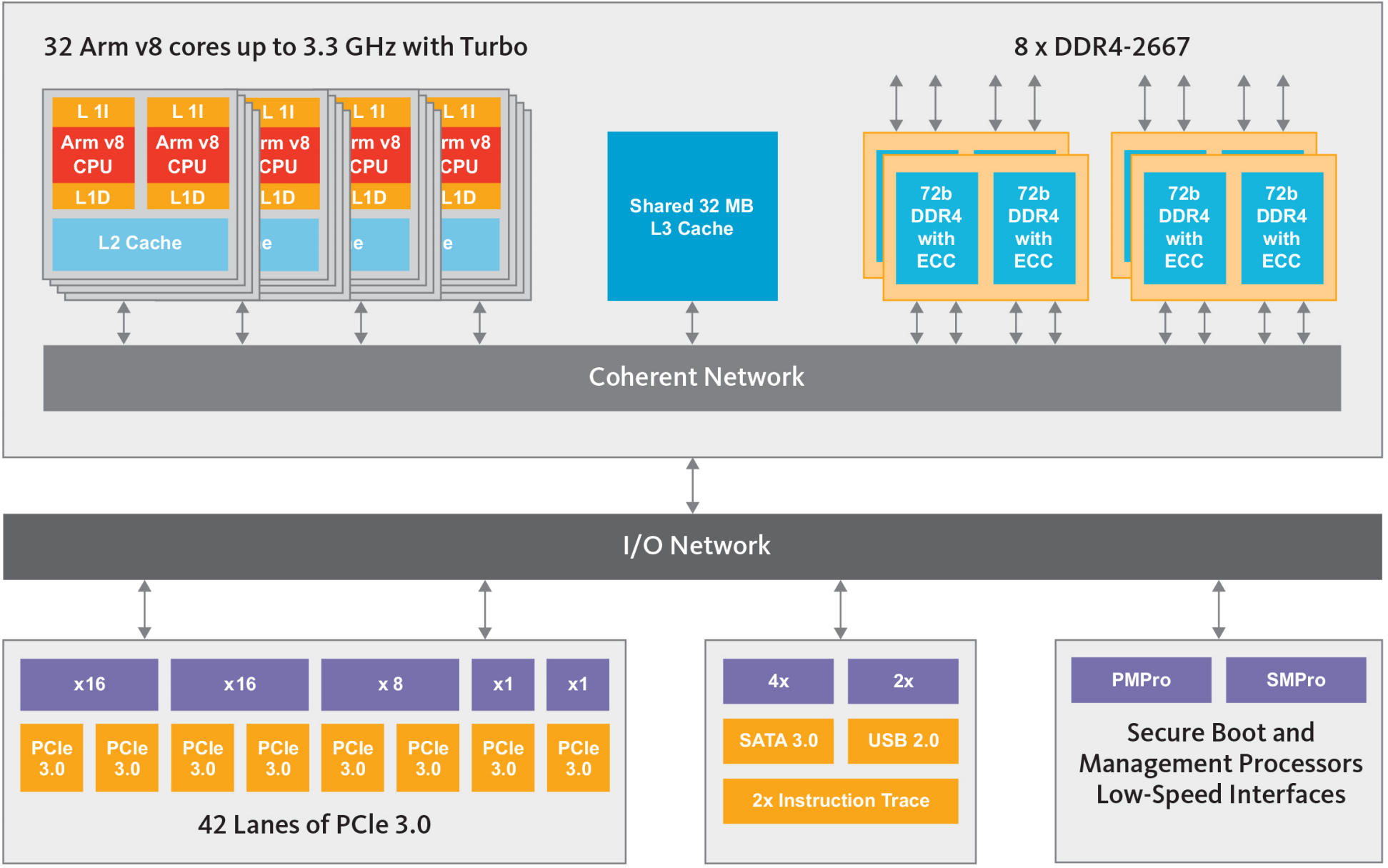
On a chip-level, the CPU is characterised by having a large coherent network tying all the CPU modules, the memory controllers, and a big large 32MB L3 cache together.
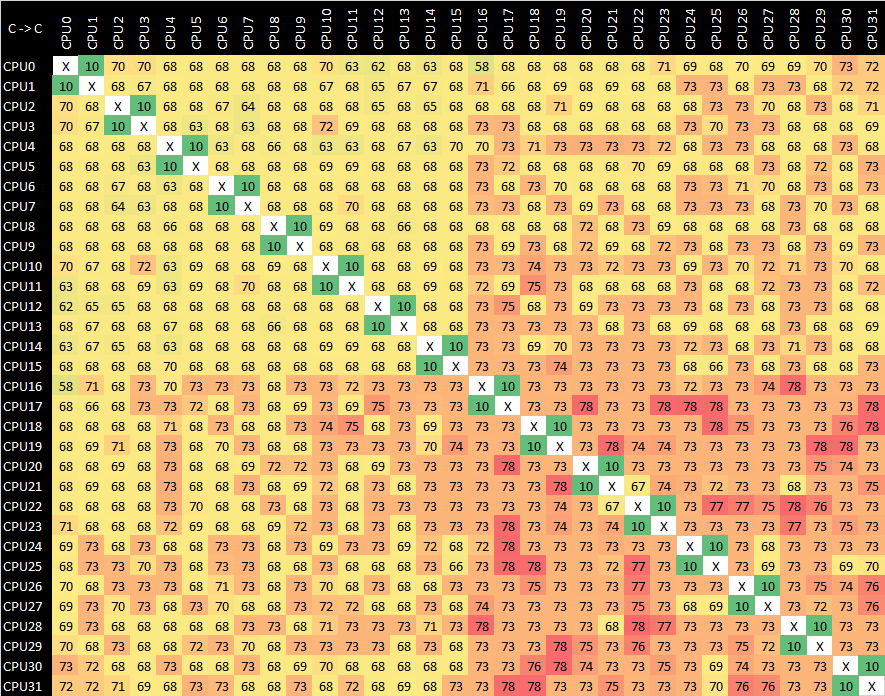
What’s surprising here is that the core-to-core latency across the whole chip isn’t bad at all, ranging from 68-73ns. While this certainly doesn’t keep up with more recent monolithic designs, this is an Arm v8.0 core lacking CAS atomic operations – so the above figures are done via regular sequential exclusive load / exclusive stores which aren’t as fast. The coherency here going over the 32MB L3 cache certainly helps the system punch above its weight for a design of its time.
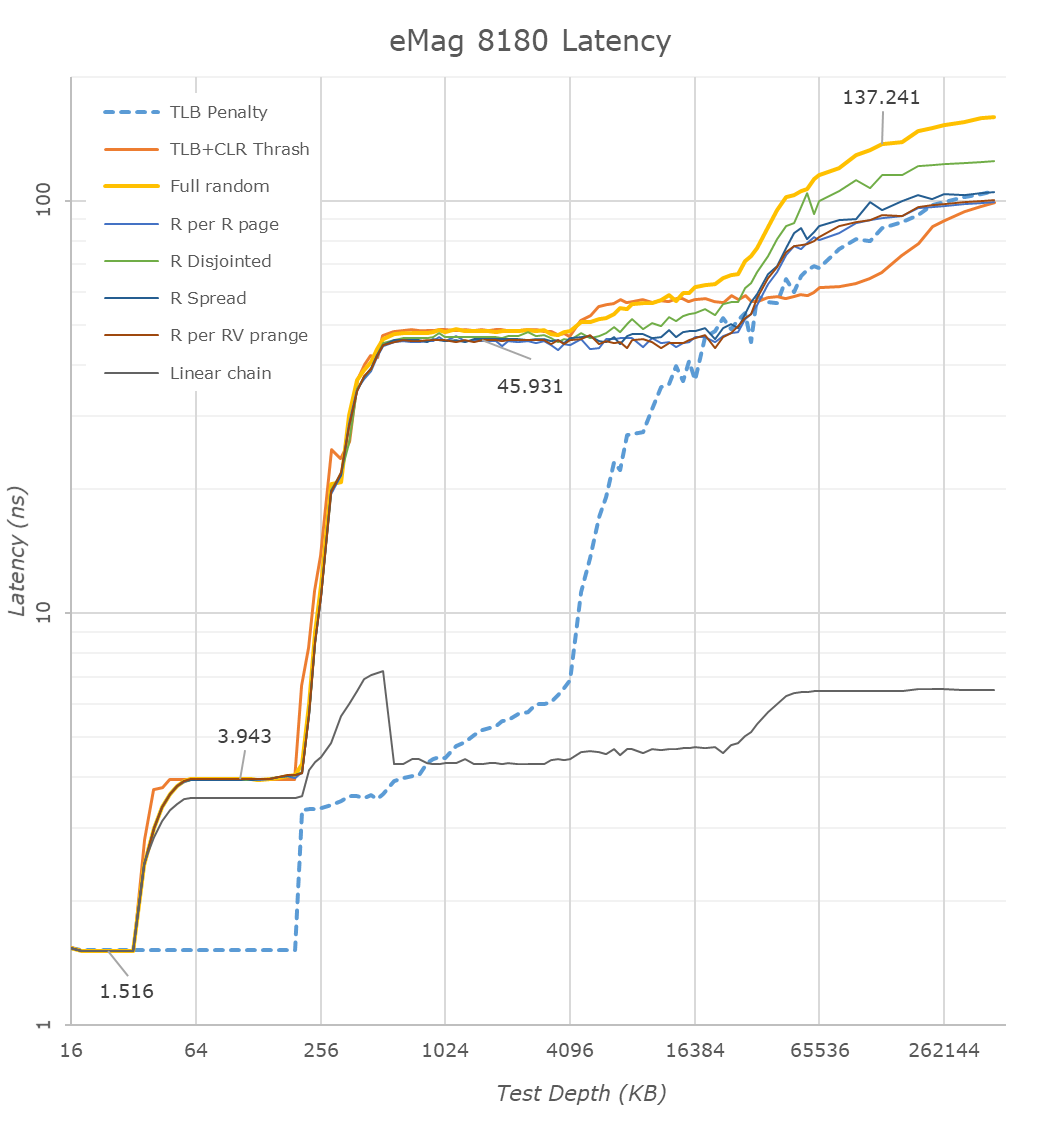
The CPU cores have 32KB L1 instruction and data caches – the access latencies here are 5 cycles. The 256KB L2 caches has a 13-cycle access latency, while the 32LB L3 cache has some massive 45ns+ access latencies that are much slower than any other comparable design out there.
We note the core’s L1 TLB ends at 48 pages (192KB) and the L2 TLB at 1024 pages (4MB), after which page-miss access times increasingly result in worse latencies.
In contrast with the quite large cache access latencies, the DRAM access latency isn’t all that bad at around 137ns full random at 128MB depth.
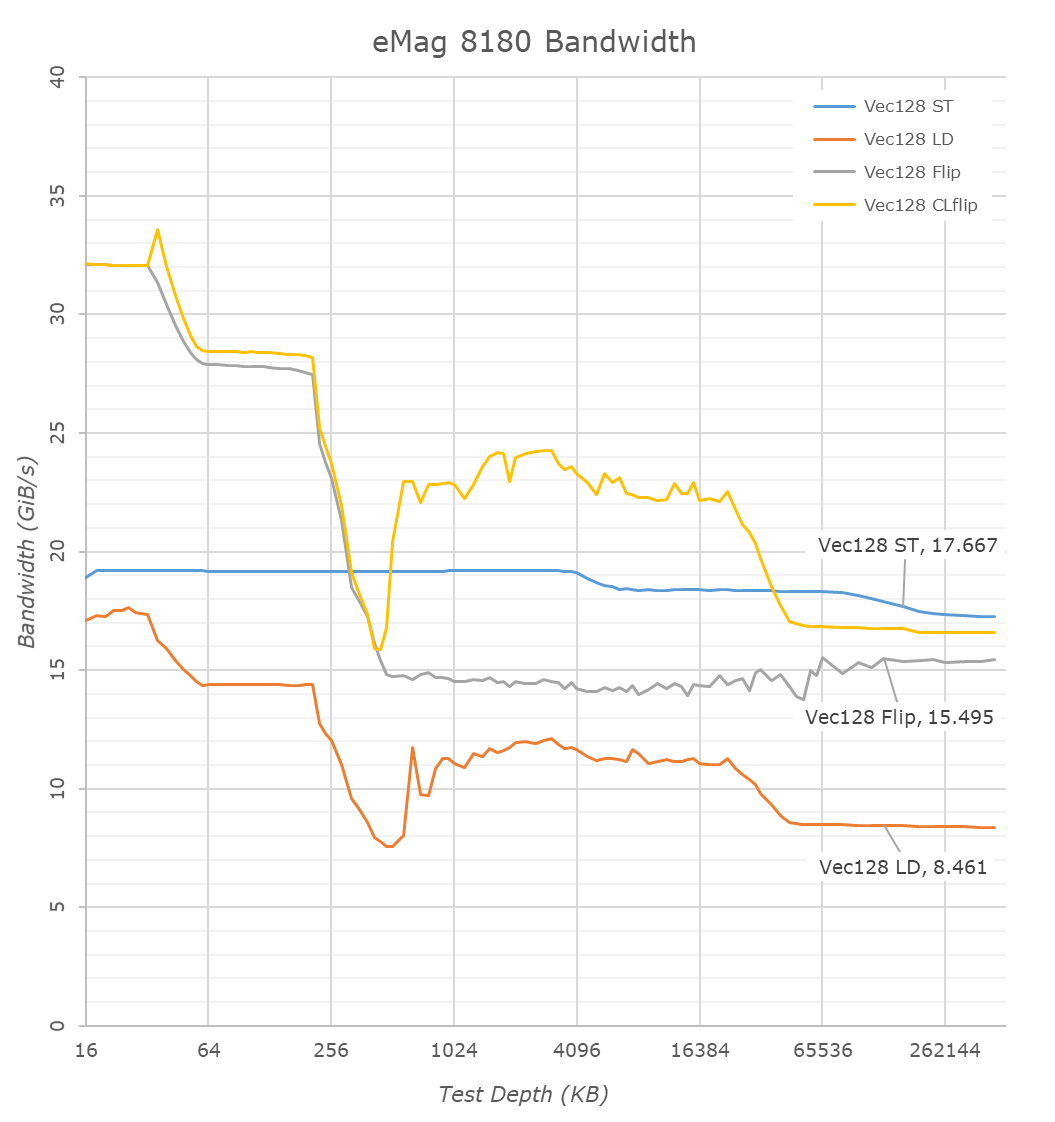
Single-core bandwidth of the Skylark cores isn’t too pretty, load and store bandwidth into the L1 and L2 seem to be limited at 8B/cycle and a combined 16B/cycle for concurrent load & stores. The dip between the L2 and L3 is usually a showcase of a bandwidth bottleneck when evicting/replacing a cacheline, and the load bandwidth at the DRAM level is also quite disappointing.
Overall, the performance here is only half of a more modern Arm core, but again, this is a 2015-2016 core design.








35 Comments
View All Comments
lmcd - Friday, May 22, 2020 - link
You can't just reference the RPi 3 and 4 interchangeably. RPi 4 ranges from 2x to 10x faster than the RPi 3 depending on workload. Most SBCs surpassed the RPi 3 merely by choosing an SoC without its terrible I/O constraints. A few have 2xA72. The RPi 4 has 4xA72 at a better process node -> better clockspeed for the same thermal constraints, and no FSB limitations. Its CPU performance is ahead of all but the top-end hardware development kit boards.lmcd - Friday, May 22, 2020 - link
Apparently I'm a moron that didn't see the ODROID-N2 release. That CPU is noticeably better.SarahKerrigan - Friday, May 22, 2020 - link
It would likely win by a small to moderate amount against the Pi4 on ST, and obviously by a factor of several times on MT.Altra will increase those numbers considerably, since it should be doing 2-3x the ST eMag and a much larger factor for MT due to the core count increase.
Dodozoid - Saturday, May 23, 2020 - link
Would have been interesting if AMDs planned K12 worked out. Any idea if any part of that architecture is still alive?AnarchoPrimitiv - Sunday, May 24, 2020 - link
There's a decent amount of spelling errors and wrong word errors in this article, for example:"... having an Arm system like this is the fact that it enables YOUR (I think you mean "you") native software development, without having to worry about cross-compiling code and all of the kerfuffle that that ENTRAILS (I think you mean "entails")"
There's a few of those on every page, did anyone even proof read this once before publishing?
LordConrad - Sunday, May 24, 2020 - link
"...without having to worry about cross-compiling code and all of the kerfuffle that that entrails."Wow, who did you have to disembowel to get the cross-compiling done?
abufrejoval - Sunday, May 24, 2020 - link
He quite exaggerated the effort, because it makes little difference if you compile GCC for the host architecture or a different one: Just a matter of configuration and that's it.You have to understand that pretty much every compiler has to compile itsself, because nobody wants to code it in machine binary or assembly. The code for all supported target architectures comes with the compiler source tree and you just need to pick the proper parts to use.
It's just a tad more involved than simply running cc off the shelf.
Fataliity - Sunday, May 24, 2020 - link
"You must first compile the compiler, to then compile your code"
Sounds pretty crazy. Isn't the compilers also written in c++, which are compiling c++?
My brain hurts.
GreenReaper - Sunday, May 24, 2020 - link
It involves a frequently non-trivial, multi-step process called bootstrapping:https://en.wikipedia.org/wiki/Bootstrapping_(compi...
abufrejoval - Sunday, May 24, 2020 - link
Well, recursion really grows on you after a bit of use :-)While I am pretty sure gcc is written in C++ these days, obviously the first C++ compiler still had to be written in C, because otherwise there was nothing to compile it with. Only after the C++ compiler had been compiled and was ready to run, the compiler could be refactored in C++, which I am pretty sure was done rather gradually, perhaps never fully.
These days I doubt that the GNU Fortran, Objective-C, Go or plain old C-compiler are written in anything but C++, because there would be no benefit in doing so. But of course, it could be done (I wouldn't want to write a compiler in Fortran, but I guess some of the early ones were, perhaps with lots of assembly sprinkled in).
The GNU bootstrapping was done a long time ago, perhaps with a K&R compiler and you don't typically have to go through the full process described in the article GreenReaper linked to. Pretty sure LLVM was bootstrapped in GCC and now you could do the same the other way around, if you didn't know what else to do with your day.
I hear the Rust guys want to do a full bootstrap now, but so far their compiler was probably just done in C++. Not that they really have to, probably just because "eat your own dogfood" gets on their nerves.
The process Andrei had to use is pretty much whatever the guy who put 'cc/c++' on the shelf of your Unix/Linux had to do, except that Andrei had to explicitly configure an ARM64 v8 target during the compile, while by default the Makefile or script will pick the host architecture.
Really a pretty minor effort, trivial if you are used to build Unix/Linux applications or even a kernel or distribution from source.
And if you are developing for Android, that's what's happening all the time under the hood, there: So far nobody will want to build Android on an Android device, because it's rather slow already, even on a big server with dozens of cores.