The Intel Lakefield Deep Dive: Everything To Know About the First x86 Hybrid CPU
by Dr. Ian Cutress on July 2, 2020 9:00 AM EST
For the past eighteen months, Intel has paraded its new ‘Lakefield’ processor design around the press and the public as a paragon of new processor innovation. Inside, Intel pairs one of its fast peak performance cores with four of its lower power efficient cores, and uses novel technology in order to build the processor in the smallest footprint it can. The new Lakefield design is a sign that Intel is looking into new processor paradigms, such as hybrid processors with different types of cores, but also different stacking and packaging technologies to help drive the next wave of computing. With this article, we will tell you all you need to know about Lakefield.
Part Smartphone, Part PC
When designing a processor, there are over a thousand design choices to be made. The processor can be built to tackle everything, or it can be aimed at a niche. For high performance computing, there might be a need for a high power, high performance design where cooling is of no consideration – compare that to a processor aimed at a portable device, and it needs to be energy efficient and offer considerable battery life for a fixed battery size. There is also the cost of designing the product, how much to invest into research and development, how many units are expected to sell, and thus how many should be produced and what size the product should be. What the price range of the target market is can be a huge factor, even before putting pen to paper.

The New Samsung Galaxy Book S
This is all why we have big multi-core processors with lots of compute acceleration in servers, more moderate power and core counts in home machines that focus on single core performance and user experience, and why smartphone processors have to physically fit into a small design and offer exceptional battery life.
Laptop processors have always sort of fit into the middle of the PC and smartphone markets. Laptop users, especially professionals and gamers, need the high performance that a desktop platform can provide, but road warriors need something that is superbly efficient in power consumption, especially at idle, to provide all-day battery life as if they were on a good smartphone. Not only this, but the more energy efficient and the smaller the footprint of the processor and its features, the thinner and lighter the laptop can be, offering a premium design experience.
As a result, we have seen the ultra-premium notebook market converge from two directions.
From the top, we have AMD and Intel, using their laptop processor designs in smaller and smaller power envelopes to offer thin and light devices with exceptional performance and yet retain the energy efficiency required for battery life. For the most premium designs, we see 12-15+ hours of laptop battery life, as well as very capable gaming.
From the bottom, we have Qualcomm, building out its high-performance smartphone processor line into larger power envelopes, in order to offer desktop-class performance with smartphone-class connectivity and battery life. With the designs using Qualcomm’s processors, a user can very easily expect 24+ hours of battery life, and with regular office use, only charge the system once every couple of days. Qualcomm still has an additional barrier in software, which it is working towards.
Both of these directions converge on something in the middle – something that can offer desktop-class performance, 24hr+ battery life, capable gaming, but also has a full range of software support. Rather continue with trying to bring its processors down to the level it requires, Intel has decided to flip its traditional processor paradigm upside down, and build a smartphone-class processor for this market, matching Qualcomm in its bottom up approach while also looking into novel manufacturing techniques in order to do so.
This processor design is called ‘Lakefield’.
Lakefield at the Core, and the Atom
For the past two decades, Intel has had two different types of x86 CPU design.
The Big ‘Core’ CPU
Intel calls its high power/high performance x86 design the ‘Core’ family. This can make it very confusing, to differentiate between the general concept of a processor core and a ‘Core’-based processor core.
Over the years, Core-based processor cores have been designed for power envelopes from low-power laptops all the way up to the beefiest of servers. The Core line of processor cores implement more complex logic in order to provide additional acceleration, at the expense of physical size and power.
The Small ‘Atom’ CPU
The second type of x86 design from Intel is its more energy efficient implementation, called ‘Atom’. With the Atom cores, Intel simplifies the design in order to maximise efficiency for a given power or a given performance. This makes the design smaller, cheaper to manufacturer, but has a lower peak performance than the Core design. We typically see Atom designs in power restricted scenarios where performance is not critical, such as IoT, or low cost laptop designs.
Where Core Meets Atom
Normally we characterise a processor core design in terms of this power and performance. Due to the variation in the design, we see where some designs work best, at various points for a given power or for a given performance. In the case of Intel’s latest generation of Core and Atom hardware, it looks something like this, if we compare one thread against one thread:
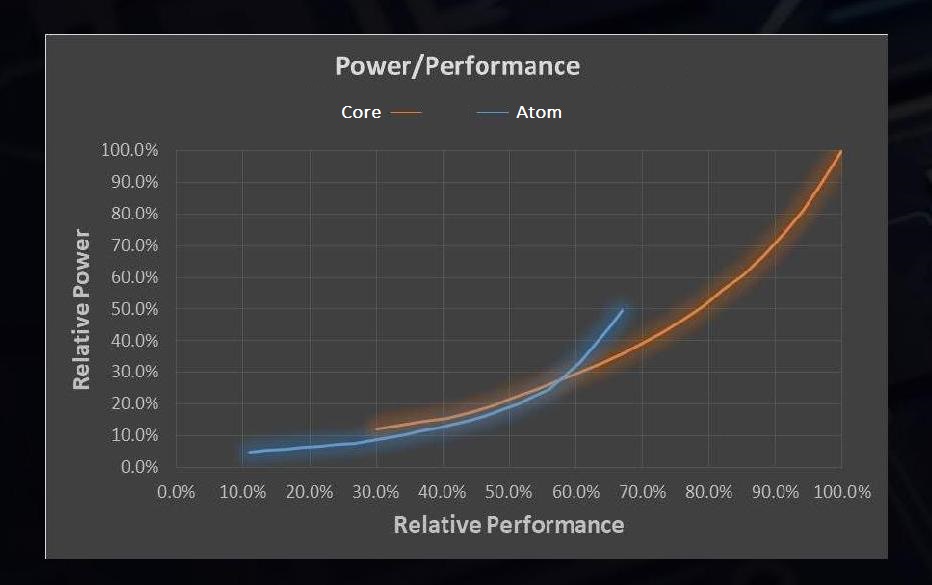
Modified from Intel’s Slides
From this graph, which measures Performance on the bottom axis and power on the side axis, there is a crossover point where each design makes the best sense. When the demand for performance is below 58%, the Atom design is the most power efficient, but above 58% then a Core design is preferred.
Homogenous CPUs (all the same) vs
Heterogeneous CPUs (mix of different)
Now in modern processors, especially in laptops, desktops, and servers, we only experience one type of core design. We either have all Core or all Atom, and the performance is designed to scale within those homogeneous designs. It becomes a simple curve to navigate, and when more parallel performance is required, more of those types of cores are fired up to serve the needs of the end user. This has been the case for these markets for the last 30-50 years.
The smartphone space, for the last decade, has been taking a different approach. Within the smartphone world, there are core designs listed as ‘big’ and core designs listed as ‘little’, in the same way that Intel has Core and Atom designs.
These smartphone processors combine numbers of big cores with numbers of small cores, such that there is an intrinsic benefit to running background tasks on the little cores, where efficiency is important, and user experience related elements on the big cores, where latency and performance is important.
The complexity of such a heterogeneous smartphone-like design has many layers. By default most items will start on the little cores, and it is up to either the processor or the operating system to identify when the higher performance mode during a user experience moment is needed. This can be tricky to identify.
Then also comes the matter when a workload has to actually move from one type of core to the other, typically in response to a request for a specific level of performance – if the cores are designed significantly different, then the demands on the memory can likely increase and it is up to the operating system to ensure everything works as it should. There is also an additional element of security, which is a larger topic outside of the scope of this article.
Ultimately building a design with both big cores and little cores comes down a lot to what we call the scheduler. This is a program inside the operating system that manages where different background processes, user experience events, or things like video editing and games, get arranged. The smartphone market has been working on different types of schedulers, and optimizing the designs, for over a decade as mentioned. For the land of Intel and AMD, the push for heterogeneous schedulers has been a slow process by comparison, and it becomes very much a chicken and egg problem – there is no need for an optimized heterogeneous scheduler if there is never a heterogeneous processor in the market.
So why bring all this up?
Lakefield is the first x86 heterogeneous processor.
In its marketing, Intel calls this a ‘hybrid’ CPU, and we will start to see logos identifying this as such. At the heart of its design, Lakefield combines one of the big Core designs with a cluster of four smaller Atom designs, all into one single piece of silicon. In normal x86 processor talk, this is essentially a ‘penta-core’ design, which will commonly be referred to as a 1+4 implementation (for one big core and four small cores).
Intel’s goal with Lakefield is to combine the benefits of the power efficient Atom core with the better user-experience elements provided by the more power hungry but better peak performing big Core. As a result, it sits in the middle of Intel’s traditional homogeneous designs which only contain one type of x86 design – somewhere above the ‘all Atom’ 0+4 design and somewhere below the ‘all Core’ 4+0 design (in actual fact, it’s closer to 0+4).
Based on our conversations with Intel, and the small demonstrations we have seen so far, the best way to consider the new Lakefield processor is to consider it similar to one of the older quad-core Atom processors, with the benefits of the single core performance of a big Core. The cluster of four smaller Atom CPUs will take care of the heavy lifting and parallel performance requests, because there are four of them, while the big Core will respond when the user loads an application, or touches the screen, or scrolls a web browser.
Being a new form of x86 hybrid CPU is not the only thing that Lakefield brings to the table.

Now, just for some form of clarification, we have already had some experience with these sorts of hybrid CPU designs on operating systems like Windows. Qualcomm’s Windows on Snapdragon laptops, like the Lenovo Yoga, use a 4+4 design with the Snapdragon smartphone chips, and Qualcomm has had to work extensively with Microsoft to develop an appropriate scheduler that can manage workloads between the different CPU designs.
The main difference to what Qualcomm has done and what Intel is doing with Lakefield is in software support – Qualcomm processors run ‘Arm’ instructions, while Intel processors run ‘x86’ instructions. Most Windows software is built for x86 instructions, which has limited Qualcomm’s effectiveness in penetrating the traditional laptop market. Qualcomm's design actually allows for ‘x86 translation’, however its scope is limited and there is a performance penalty, but is a work in progress. The point being is that while we have not had a hybrid CPU scheduler for Windows on an x86 system previously, there has been a lot of work put in by Microsoft to date while working with Qualcomm.
Visualising Heterogeneous CPU Designs
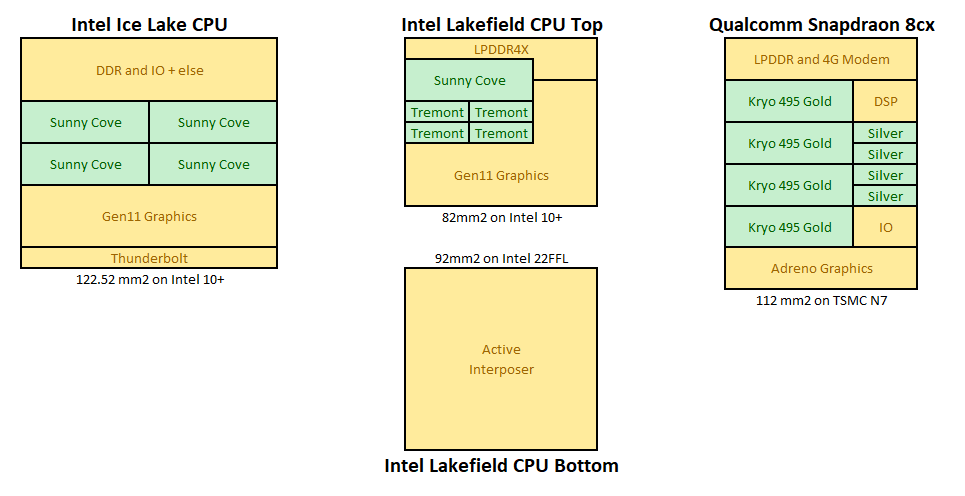
Not to any sort of scale
Here are some examples of mobile processors, from Intel and Qualcomm, with the cores in green. On the left is Intel's own Ice Lake processor, with four big cores. In the middle is Intel's Lakefield, which has two stacked silicon dies, but it's the top one that has one big core and four small ones. On the right is Qualcomm's Snapdragon 8cx, currently used in Windows on Snapdragon devices, which uses four performance cores and four efficiency cores, but also integrates a smartphone modem onboard.
In this article, over the following pages, we'll be looking at Intel's new Lakefield processor in detail, covering the new multi-core design, discussing chiplets and Intel's new die-to-die bonding technology called Foveros, the implications of such a design on laptop size (as well as looking at the publicly disclosed Lakefield laptops coming to market), die shots, supposed performance numbers, thermal innovations, and the future for Lakefield. Data for this article has come from our research as well as interviews with Intel's technical personnel and Intel's own presentations on Lakefield at events such as HotChips, Architecture Day, CES, IEDM, and ISSCC. Some information is dissected with helpful input from David Schor of Wikichip. We also cover some of Intel’s innovations with the scope of other semiconductor companies, some of which may be competitors.








221 Comments
View All Comments
ichaya - Sunday, July 12, 2020 - link
You've claimed ARM64 has a code density advantage without any evidence for a few posts now. Being byte-aligned has advantages too, which are clear in the paper with the real world program! You're welcome to provide more real world evidence!We're changing the goal posts now with new numbers, you can't estimate IPC based on one specific INTrate2006 test, and assume it's similar across other workloads as well. If we just stick to INTrate2006, IPC seems within 5% where Graviton 2 has twice the cache of AMD Epyc 7742.
Comparing a top-line power number like you were doing is irrelevant when features like AVX can easily blow past any power envelope you might have, and one chip lacks the feature.
Wilco1 - Sunday, July 12, 2020 - link
No, I am stating that AArch64 has better code density as a fact. Maybe 5 years ago you could argue about it as AArch64 was still relatively new, but today that's not even disputable. So check it out if you'd like to see it for yourself.I used the overall intrate result to get an accurate IPC comparison. If you do the math correctly you'll see that Graviton 2 has 12% higher IPC than EPYC 7742.
At the end of the day what matters is performance, perf/W and cost. Whether you have AVX or not is not relevant in this comparison - EPYC 7742 uses the same amount of power whether it executes AVX code or not.
ichaya - Tuesday, July 14, 2020 - link
This is not the first time I've seen someone look at single thread performance and disregard everything else. All Graviton 2 and A13 single thread gains can be attributed to large (100~200% more) shared L2/L3 caches, and when compared with x86, 5% or even 75% IPC gains turn out to be ~10% less real world performance or ~10% more with marginal power use difference on 7nm. AMD has everything from a 15W to 280W chip.For multi-threaded, the Graviton 2 looks better, but the 64 vcpu EPYC 2 c5a.16xlarge (144MB L2+L3) AWS instance costs the same as the 64 core Graviton 2 m6g.16xlarge (96MB L2+L3) instance and delvers equivalent performance on real world tasks while having 1/2 the real cores, 1/2 the system RAM and 50% more L2+L3.
perf/W/$ is important, and since ARM has always been on the lower end of W and $, it can be hard to see past it. If you can compare cache sizes, power and real world performance, the only thing revolutionary is the fact that Amazon, Apple and the ARM ecosystem have come this far in a few years. The overall features (AVX2+SMT among others) and openness still leaves a lot to be desired.
Wilco1 - Wednesday, July 15, 2020 - link
Single threaded performance is important in showing that x86 does no longer have the big advantage it once used to have. Overall throughput is well correlated with single thread performance, you can see that clearly in the results we discussed. Do you believe 64 Graviton 1 cores would do equally well against 7742 if they had the same huge caches?I haven't seen serious benchmarks on c5a, do you have a link? With 32 cores at 3.3GHz it should burn well over 200W, not an improvement...
It's not that revolutionary if you followed the rapid increase of single thread performance over the last 5 years. Smartphones paid for the progress in microarchitecture and process technology that enabled competitive Arm servers (it helped AMD surpass Intel as well). I don't believe SMT or AVX are useful - 128 cores in Altra Max will beat 64 cores with SMT+AVX on performance and area at similar power.
As for AVX, this article discusses how Intel's latest CPU disables AVX... Linus had some interesting comments recently about the fragmentation of the many AVX variants. Then there are all the unresolved clocking and power issues. It's a mess.
ichaya - Thursday, July 16, 2020 - link
If there was a significant power difference between m6g.16xlarge and c5a.16xlarge, they would be priced differently. 128GB of RAM can't be more than ~15W.Single thread performance can help multi-thread performance up to a point, but SMT, non-boost clocks, and biasing towards TLP more than ILP (like an in-order GPU) can hurt single thread performance at the expense of more multi-threaded throughput.
AVX-512 is a mess, but AVX2 is worth having in most contexts now. Maybe some AVX512 instructions worth having will make it into a AVX2.1 which can completely supersede AVX2. For the price of Lakefield, there are certainly more attractive options, though compatibility, packaging and performance can trump battery life.
Wilco1 - Thursday, July 16, 2020 - link
Well there is a much better comparison, c6g.16xlarge has 128GB and is 12% cheaper than c5a.16xlarge. More than enough to pay for the electricity cost of the 280W TDP of c5a.Yes you can optimize for multithreaded throughput but SMT remains questionable, especially for large core counts. Why add SMT when you could just add some more cores?
Indeed AVX512 is worse, and could be removed without anyone missing it. Lakefield battery life comparisons are in, the Atom curse has struck yet again...
ichaya - Thursday, July 16, 2020 - link
12% is probably more the amount of subsidies these instances are getting. Amazon has a very very long history of putting any profit margins back into growth. Either that, or 128GB of RAM is 100W+!SMT is perhaps the lowest level at which TLP can be extracted, recent multi-core Atoms don't have it, but for server/workstation tasks like compilation, DB engine or even general multi-tasking, it's well worth it.
Wilco1 - Friday, July 17, 2020 - link
Graviton 2 is less than a third of the silicon area of EPYC so cheaper to make. 128GB server DRAM costs over $1000, which is why the 256GB/512GB versions are more expensive. The power cost of extra DRAM is a tiny fraction of that.There are tasks where SMT helps but equally there also tasks where it is slower. So it looks great on marketing slides where you just show the best cases, but overall it is a small gain.
ichaya - Saturday, July 18, 2020 - link
I wouldn't call a 64 vcpu (180W) system beating or equaling a 64 core (110W) system in web serving/DB and code compilation a small gain. The tasks where SMT hurts is basically single threaded JS, which is just such a shame. Shame! I don't think POWER, SPARC and others have been wrong in having added SMT years ago.For code compilation and DB the differences are 50%-100%+ making perf/W/$ very competitive.
https://www.phoronix.com/scan.php?page=article&...
This article also seems to mention SMT might make an appearance in the next Neoverse N* chips: https://www.nextplatform.com/2019/02/28/arm-sharpe...
Wilco1 - Sunday, July 19, 2020 - link
The Phoronix link has various benchmarks that aren't even running identical code between different ISAs (eg. Linux kernel compile). So it's not anywhere near a fair CPU comparison like SPEC. And this: https://openbenchmarking.org/result/1907314-AS-RYZ... shows SMT gives almost no gain on multithreaded benchmarks once you stop cherry picking the good results and ignore the bad ones...Even if we just consider the benchmarks with the largest SMT speedup, Coremark and 7-zip have good SMT gains of 41% and 32%, but m6g *still* outperforms c5a by 5% and 24%.
So the best SMT gain combined with a 32% frequency advantage and 4 times the L3 cache is still not enough to provide equal per-thread performance!