Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
by Andrei Frumusanu on August 17, 2020 4:30 PM EST- Posted in
- Servers
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- ThunderX3
The Triton CPU Core - Evolution From Vulcan
Moving on onto the core level, we see the first disclosures on Marvell’s new Triton CPU microarchitecture. The design is an evolution of the ThunderX2’s Vulcan cores with the company widening a lot of the aspects of the core, both in the front-end and on the back-end.
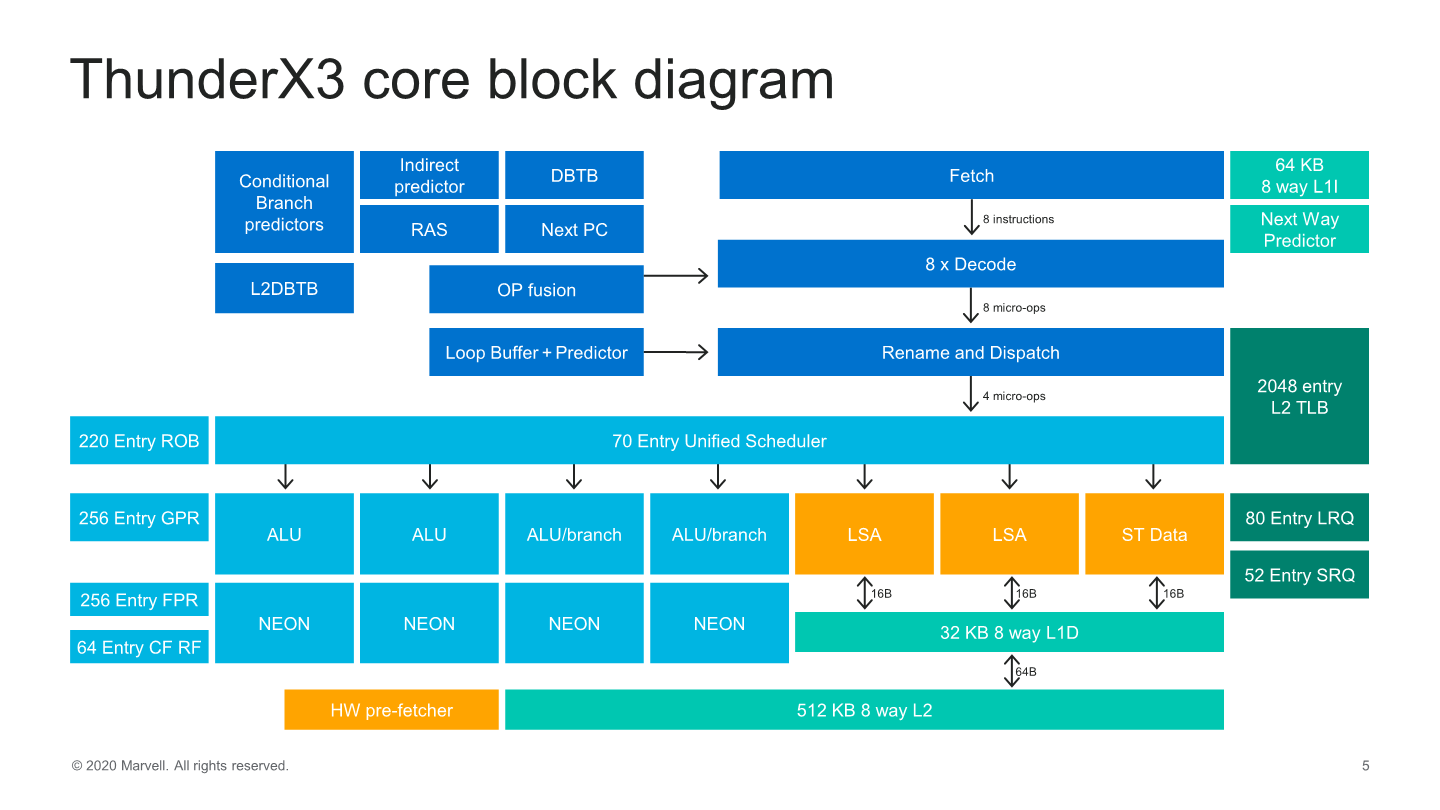
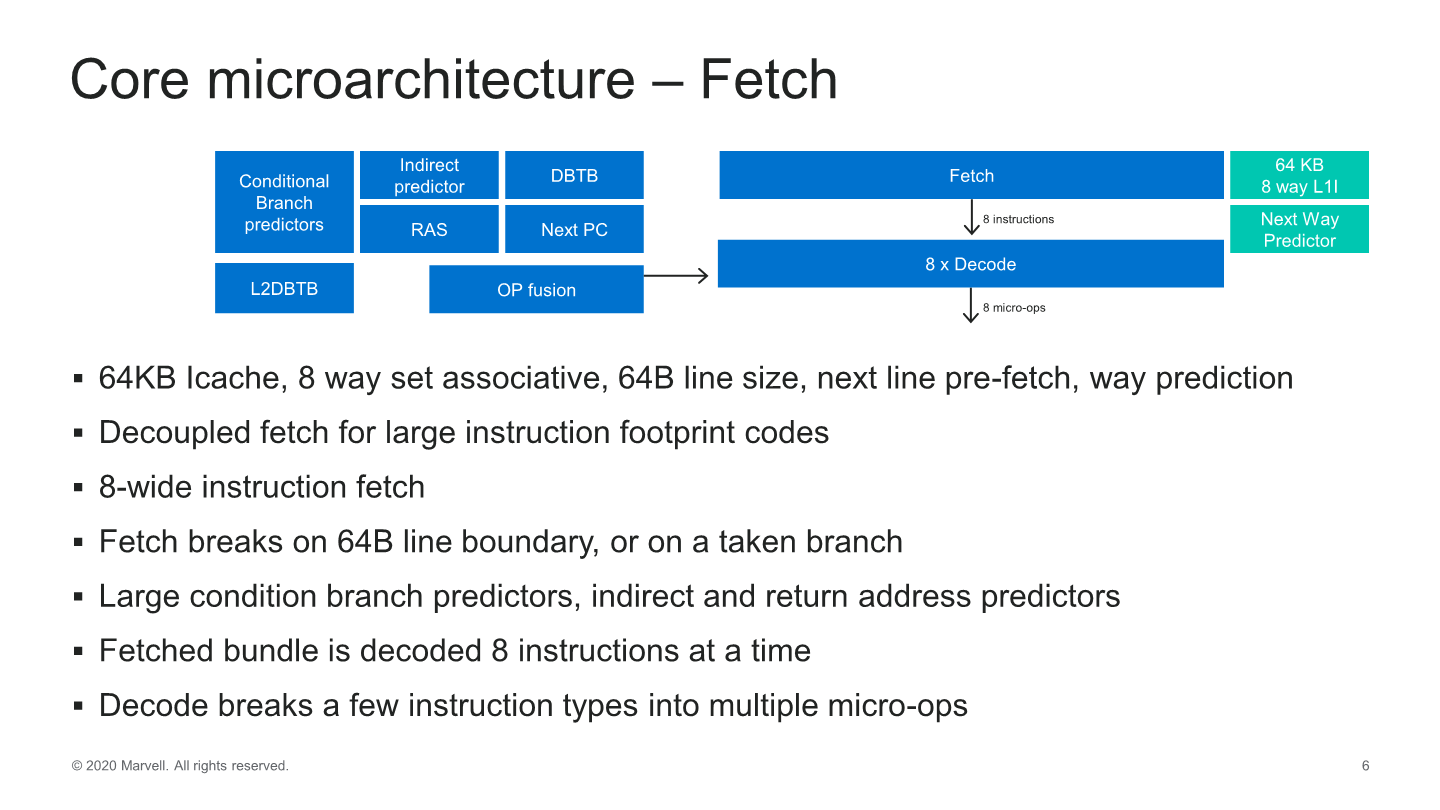
Starting off with the front-end side of the core, we see some very significant changes as we’ve almost seen a literal doubling of most structures and bandwidth in the core. The instruction cache has been doubled up from 32KB to 64KB, which now feeds into an 8-wife fetch unit, also double the previous generation.
Much like Arm’s recent microarchitectures, this is a new decoupled fetch unit that allows for better power savings. The decode unit matches the fetch bandwidth at 8 instructions wide – which actually along with the Power10 core from IBM now represents the widest decoders in the industry right now, which is quite surprising.
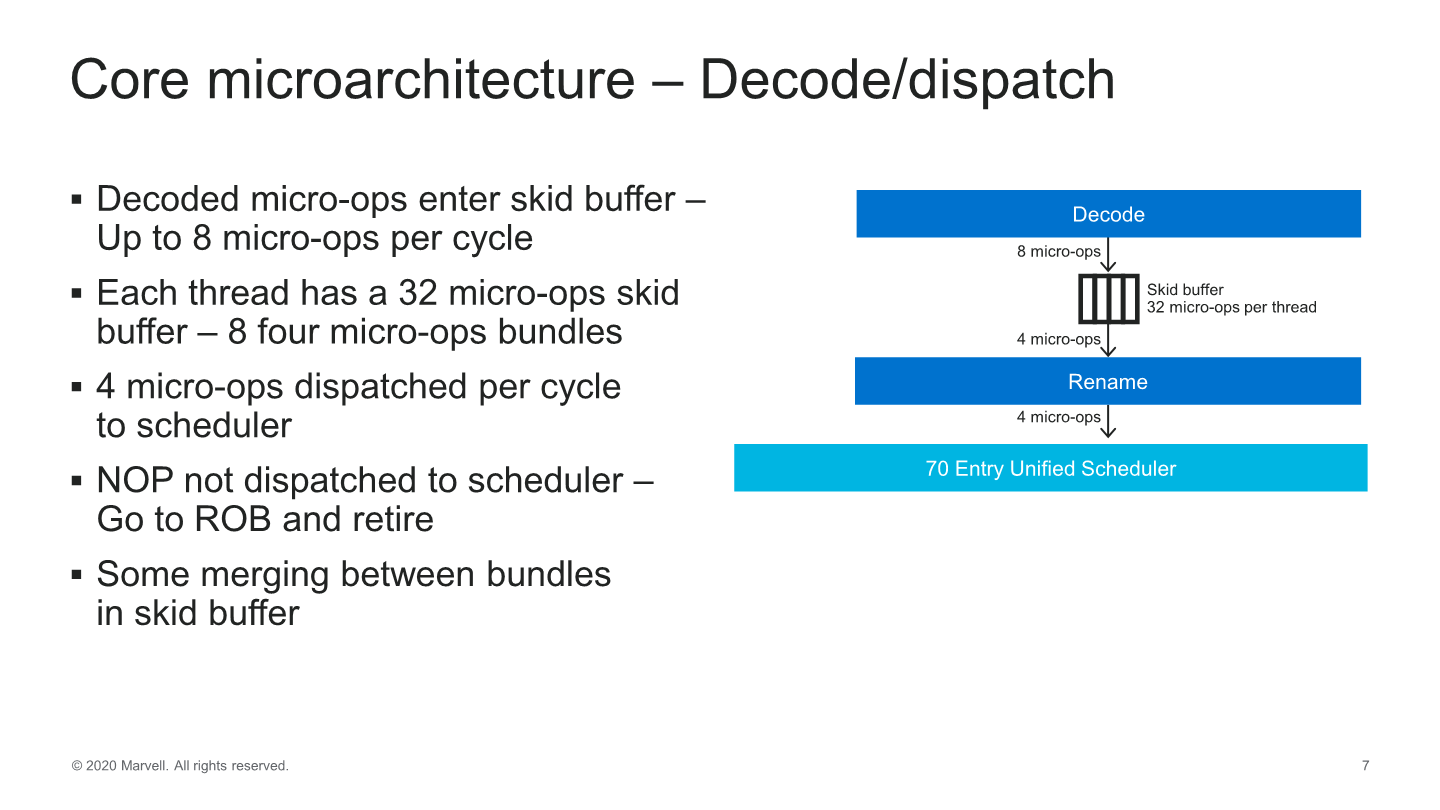
In the mid-core we see the decode unit feed into what Marvell calls a “Skid buffer”, which is essentially a loop buffer, which is segmented into 32 micro-ops per thread, further divided into eight four-wide micro-op bundles. It’s one of the rare structures in the core which is statically partitioned between threads, and it represents the boundary between the front-end and the mid-core of the microarchitecture.
The most interesting and confusing part of the Trition microarchitecture is at this part of the core, as even though the fetch and decode units of the core are 8-wide, micro-ops out of the Skid-buffer and into the rename unit and dispatched to the backend of the core only happens at 4 micro-ops per clock. So what seems to be happening here is that Marvell is taking advantage of a very wide front-end design not to actually feed a large back-end, but rather to better hide pipeline bubbles working in wider “bursts”.
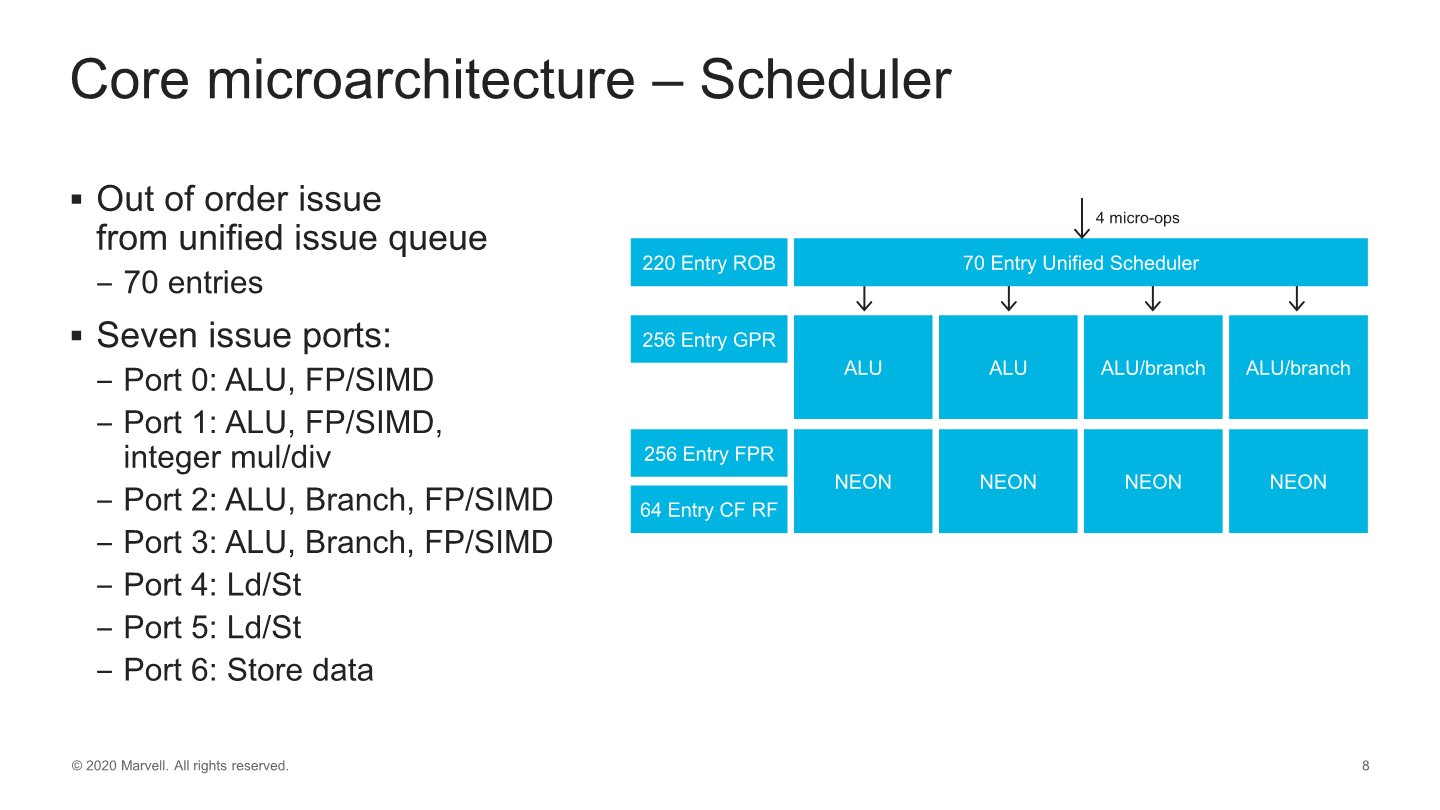
Dispatch into the backend of the core we see continued usage of a global unified scheduler that feeds into 7 execution ports. At the scheduler-level, we’ve seen a slight increase from 60 to 70 entries.
The out-of-order window of the core has increased slightly, such as the re-order buffer (ROB) growing from 180 to 220 entries.
On the execution ports, the big change has been the addition of a fourth execution pipeline capable of ALU instructions and a second branch port, meaning we’re seeing a 33% increase in simple integer ALU execution throughput and a doubling of the branch forwarding of the core. Alongside of these improvements, all four execution pipelines have been expanded with FP/SIMD capabilities which means there’s now a generational doubling of throughput for these instructions, making the Triton core one of the rare 4x128b machines out there.
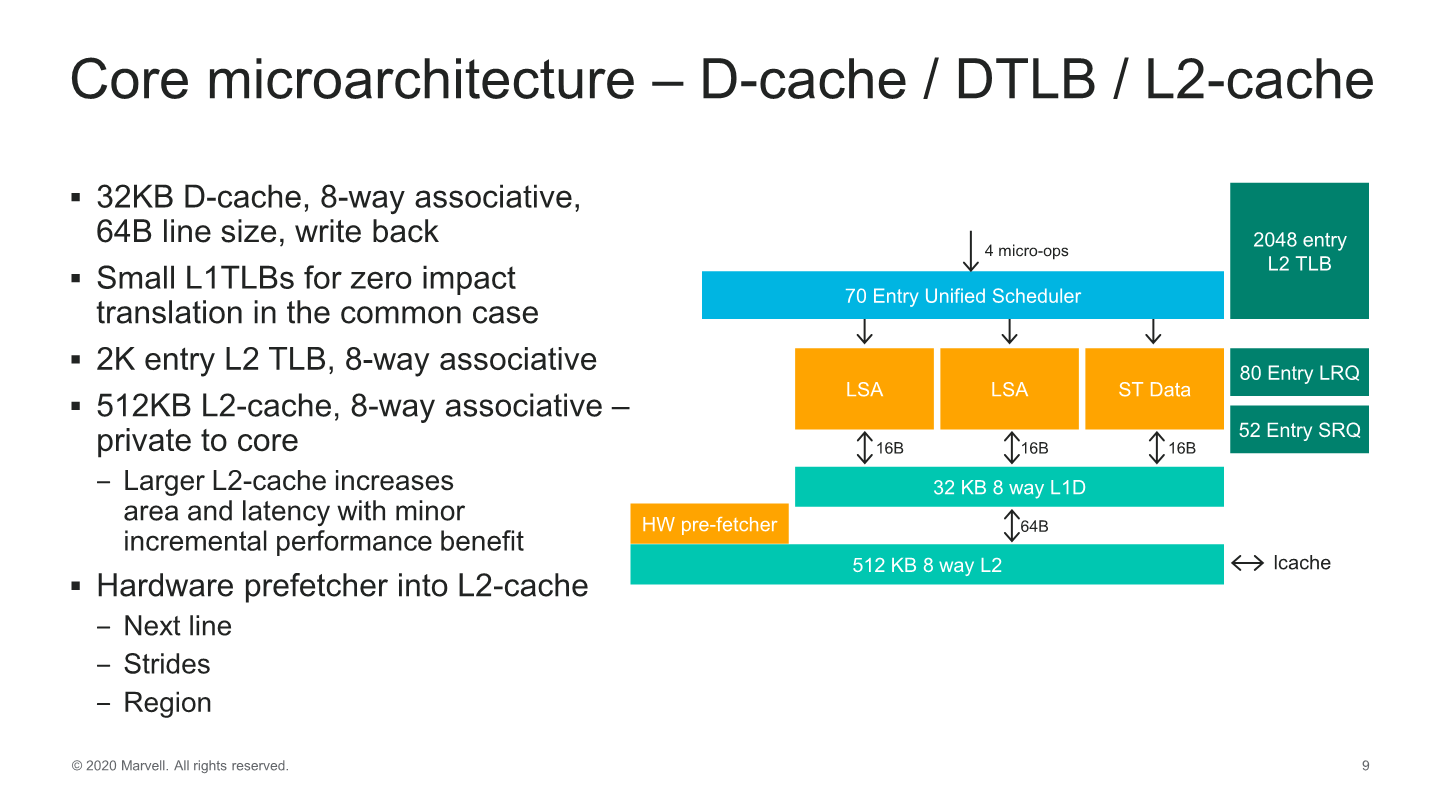
On the memory subsystem part of the core, improvements have been relatively small as we don’t seem to have major high-level changes of the microarchitecture. We still see two load-store units and a store data unit with bandwidths of 16 Bytes/cycle per unit feeding and fetching data from a 32KB L1 data cache. The load and store queues have been increased in their depth and have increased respectively from 64 to 80 entries for loads, and 36 to 48 entries for stores.
The core’s L2 has also doubled from 256KB to 512KB, but Marvell’s wording here on this change is interesting as they say it increases area and latency with only “minor incremental performance benefits”, which sounds quite disappointing in tone. We’ll see in the next slide this means 2.5%.
The hardware prefetchers are quite simplistic, with your traditional next-line, stride, and region-based designs pulling data into the L2.
Overall, generational IPC improvements of the new core sum up to 30% in SPECint, and Marvell was generous enough to give us an overview of the new core’s features and how each is accounts for the total improvement:
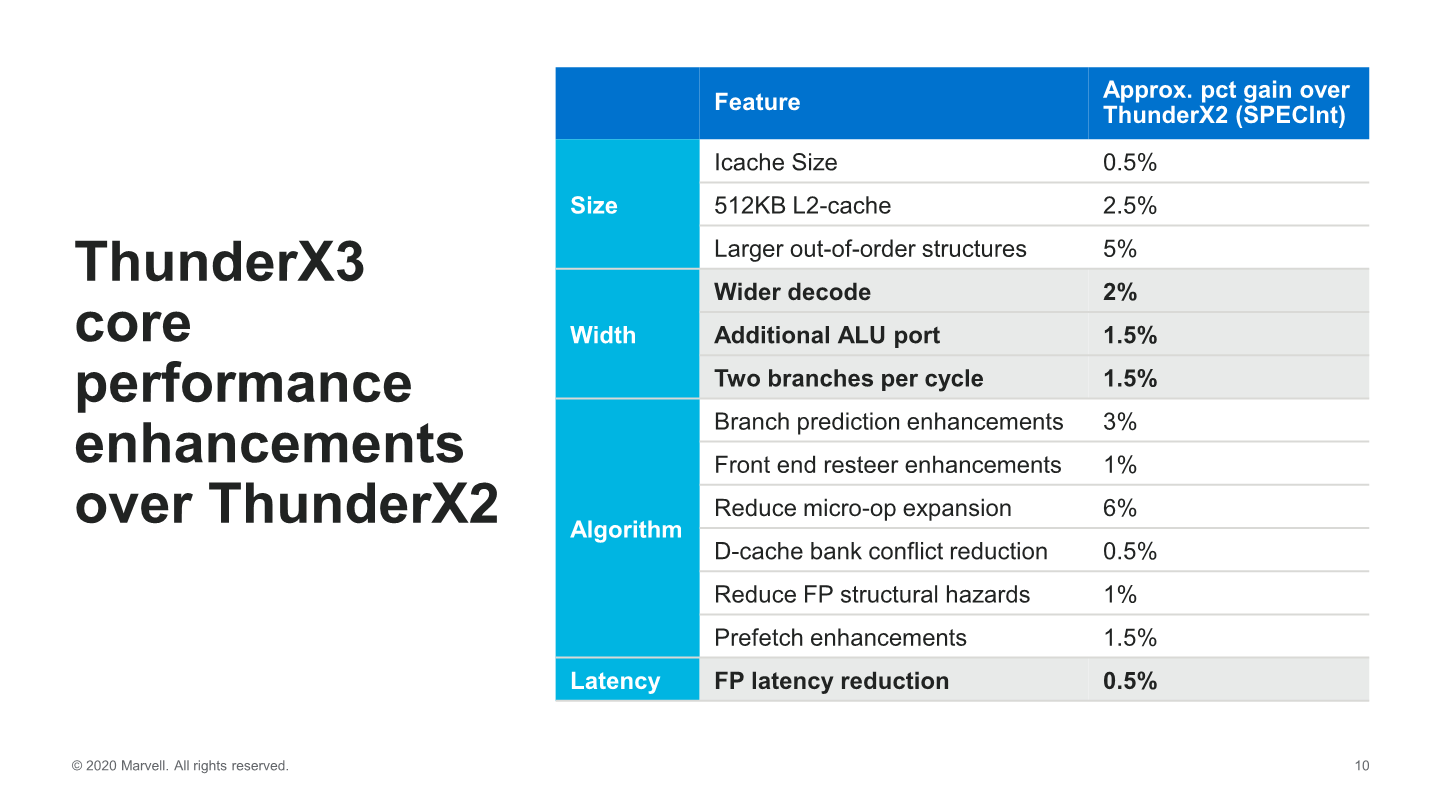
On the structure side increases of things, the biggest improvements were due to the larger OoO increases in the mid-core which, although the increases weren’t all that big, represent a 5% IPC improvement. This seems a quite good trade-off versus some other doubling of structures such as the L1I and the L2 cache increases which only got a 0.5% and 2.5% benefit.
The front-end’s doubling and wider decode from 4 to 8 only accounted for only 2% improvement in performance which is extremely tame, but is likely bottlenecked given the narrow mid-core dispatch and comparatively narrow execution back-end.
The biggest improvement in IPC was due to reduced micro-op expansion from the decoder – Marvell here stated that they had been too aggressive in this regard on the ThunderX2 Vulcan cores in expanding instructions into multiple micro-ops, so they’ve reduced this significantly, and this probably alleviating the bottleneck on the mid-core and resulting into better back-end utilisation per actual instruction.
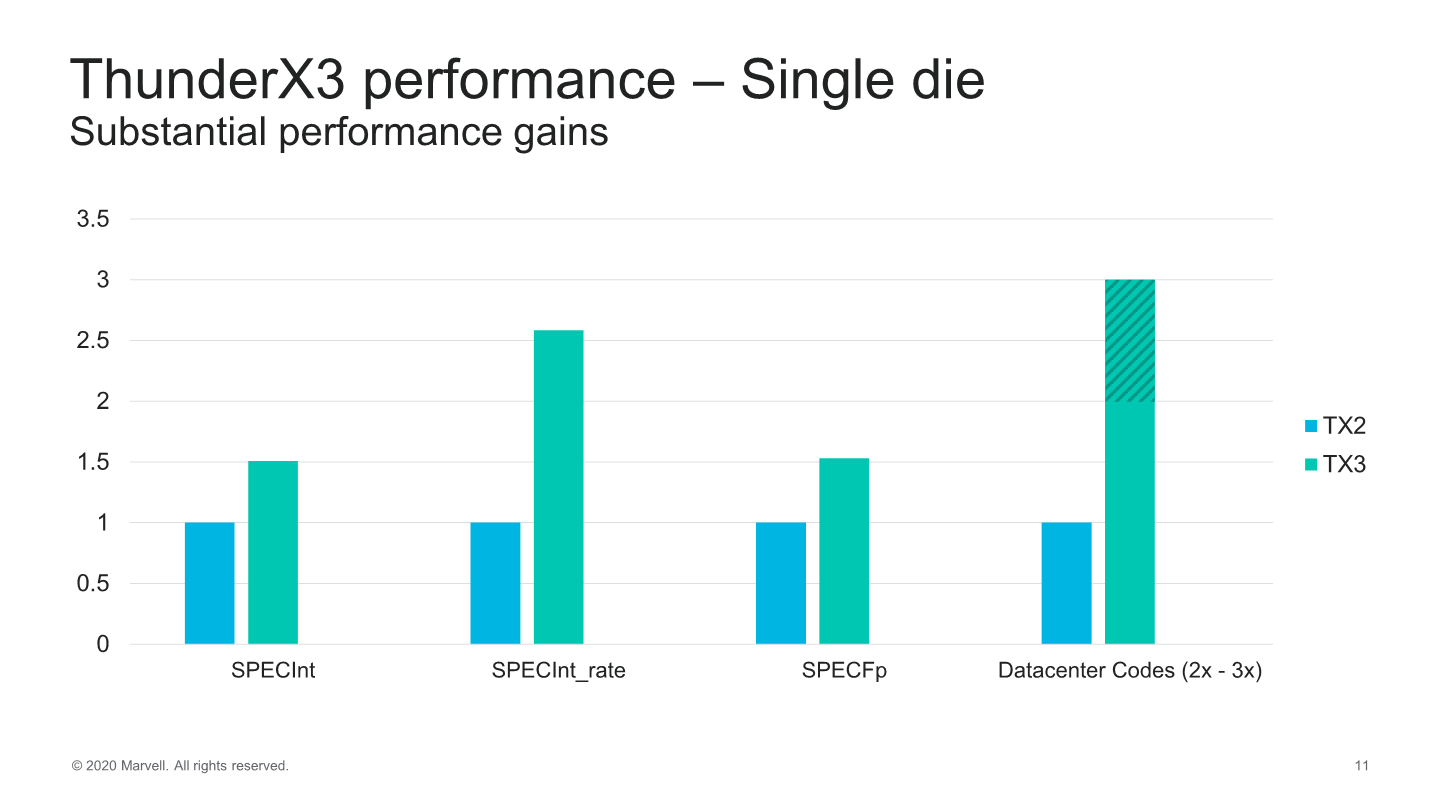
Generational performance improvements accounting for the IPC gains as well as frequency gains, we’re expected to see a 1.5x gain in SPECint. Given our historical numbers on the TX2, by these projections we should thus expect the TX3 to outperform the Graviton2 by around 10%.
SPECrate gains are naturally higher at around 2.5x the performance, thanks to the new design’s higher core count further amplifying the microarchitectural improvements.








27 Comments
View All Comments
McCartney - Tuesday, August 18, 2020 - link
i just want to give quantumz0d credit for having the courage at expressing what is clearly the case. i'm tired of ARM trash being propounded by losers stuck in the stock market and trying to pump whenever they can.i foresaw this years ago when i was propositioned with "entering the market" and doing an IPO. i steadfastly refused since i looked at it as a "credit aggregation scheme" in which the quality of any monetary "cashout" would be directly dependent on those buying in. and as far as i can see, that's not the best way to secure my future.
8 years later, my fears have been realised. the "market" has destroyed the enthusiast industry, where the latter has been enslaved by the former. all we hear about from today's "enthusiast" is how ARM processors are great, with these foolish expectations that x86 binaries can somehow be transitioned to ARM seamlessly. there is a lack of appreciation for both sides of the coin with today's enthusiast (learning the software side and the hardware side) and it is reflected by the lack of diverse offerings from the manufacturers.
in the words of one of my favourite people in the embedded space, ralph baechle (a huge contributor to MIPS), it was never foreseen that ARM would even go multicore (https://www.tldp.org/HOWTO/SMP-HOWTO-3.html).
in fact, it's hard enough to make a good multicore embedded processor (the SH4[A] is/was amasing, and stacking more cores introduces bigger challenges when you compare the physical restrictions of the embedded segment versus the desktop.
now, on to what you're saying Gomez (and originally the reason i wanted to post): i agree. for my line of work, an x86 or a good MIPS (Kfc, not just Kc) is an absolute necessity. i need larger shared memory and my work (10^5 dimension matrices that involve eigendecompositions) is not able to use "high core low cache+memory" designs such as nVidias (which has an API in MATLAB) or ARM.
i agree with you entirely. it would be very interesting from a GPU design standpoint if nVidia absorbed ARM. i would love to see what their 'shader units' would look like after getting more direction from ARM cores.
Spunjji - Wednesday, August 19, 2020 - link
Courage? For posting an ill-informed, barely-grammatical rant that didn't come close to a rational argument? Okay... 🤪Based on the rambling off-topic content of your post, it's hard to tell whether you're a z0d sockpuppet or just equally delusional.
mkanada - Wednesday, August 19, 2020 - link
With Apple going to ARM, many desktop software will be ported to this architecture. So, in the next 5 years, I hope to see ARM workstations with powerfull GPUs, competing head-to-head with x86 based computers.Gomez Addams - Friday, August 21, 2020 - link
Windows already runs on ARM and Visual Studio can target ARM code generation. All it takes is a re-compilation. There are already ARM-powered GPUs available now. This site reviewed one recently. This is only the start.Rudde - Friday, August 21, 2020 - link
"8-wife fetch unit"Now I'm intrigued.
Industry_veteran - Saturday, August 29, 2020 - link
Just 10 days after this announcement, the Marvell management seems to have realized there is no market for general purpose server grade ARM!. They pulled the rug under the feet of this team.It is funny because just stuffing more cores in the SoC doesn't win new customers in server market.
For hyper scale customers the name of the game is performance per watt numbers.
This Marvell team should have known this for long time yet they keep making these superficial announcements about how they can stuff so many cores in an SoC. Only less experienced people fall for that. The hyper scale customers know better.
pawder - Monday, September 14, 2020 - link
Wow! That is impressive, thanks for charing with us and making it clear! Now I want to help you back, do you know that most of spouses are cheating? I`m sure that you know it and you know that they are keeping their secrets in their cell phones. Today I give you an opportunity to spy on them without accessing with https://topspying.com/spy-on-a-cell-phone-without-... So follow the instuctions and spy on anybody you want