Investigating Performance of Multi-Threading on Zen 3 and AMD Ryzen 5000
by Dr. Ian Cutress on December 3, 2020 10:00 AM EST- Posted in
- CPUs
- AMD
- Zen 3
- X570
- Ryzen 5000
- Ryzen 9 5950X
- SMT
- Multi-Threading

One of the stories around AMD’s initial generations of Zen processors was the effect of Simultaneous Multi-Threading (SMT) on performance. By running with this mode enabled, as is default in most situations, users saw significant performance rises in situations that could take advantage. The reasons for this performance increase rely on two competing factors: first, why is the core designed to be so underutilized by one thread, or second, the construction of an efficient SMT strategy in order to increase performance. In this review, we take a look at AMD’s latest Zen 3 architecture to observe the benefits of SMT.
What is Simultaneous Multi-Threading (SMT)?
We often consider each CPU core as being able to process one stream of serial instructions for whatever program is being run. Simultaneous Multi-Threading, or SMT, enables a processor to run two concurrent streams of instructions on the same processor core, sharing resources and optimizing potential downtime on one set of instructions by having a secondary set to come in and take advantage of the underutilization. Two of the limiting factors in most computing models are either compute or memory latency, and SMT is designed to interleave sets of instructions to optimize compute throughput while hiding memory latency.
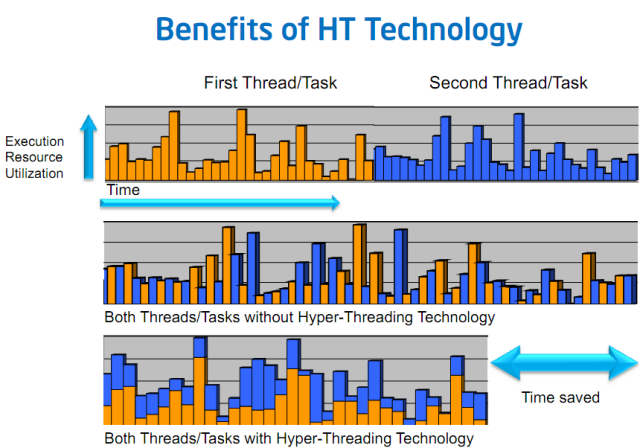
An old slide from Intel, which has its own marketing term for SMT: Hyper-Threading
When SMT is enabled, depending on the processor, it will allow two, four, or eight threads to run on that core (we have seen some esoteric compute-in-memory solutions with 24 threads per core). Instructions from any thread are rearranged to be processed in the same cycle and keep utilization of the core resources high. Because multiple threads are used, this is known as extracting thread-level parallelism (TLP) from a workload, whereas a single thread with instructions that can run concurrently is instruction-level parallelism (ILP).
Is SMT A Good Thing?
It depends on who you ask.
SMT2 (two threads per core) involves creating core structures sufficient to hold and manage two instruction streams, as well as managing how those core structures share resources. For example, if one particular buffer in your core design is meant to handle up to 64 instructions in a queue, if the average is lower than that (such as 40), then the buffer is underutilized, and an SMT design will enable the buffer is fed on average to the top. That buffer might be increased to 96 instructions in the design to account for this, ensuring that if both instruction streams are running at an ‘average’, then both will have sufficient headroom. This means two threads worth of use, for only 1.5 times the buffer size. If all else works out, then it is double the performance for less than double the core design in design area. But in ST mode, where most of that 96-wide buffer is less than 40% filled, because the whole buffer has to be powered on all the time, it might be wasting power.
But, if a core design benefits from SMT, then perhaps the core hasn’t been designed optimally for a single thread of performance in the first place. If enabling SMT gives a user exact double performance and perfect scaling across the board, as if there were two cores, then perhaps there is a direct issue with how the core is designed, from execution units to buffers to cache hierarchy. It has been known for users to complain that they only get a 5-10% gain in performance with SMT enabled, stating it doesn't work properly - this could just be because the core is designed better for ST. Similarly, stating that a +70% performance gain means that SMT is working well could be more of a signal to an unbalanced core design that wastes power.
This is the dichotomy of Simultaneous Multi-Threading. If it works well, then a user gets extra performance. But if it works too well, perhaps this is indicative of a core not suited to a particular workload. The answer to the question ‘Is SMT a good thing?’ is more complicated than it appears at first glance.
We can split up the systems that use SMT:
- High-performance x86 from Intel
- High-performance x86 from AMD
- High-performance POWER/z from IBM
- Some High-Performance Arm-based designs
- High-Performance Compute-In-Memory Designs
- High-Performance AI Hardware
Comparing to those that do not:
- High-efficiency x86 from Intel
- All smartphone-class Arm processors
- Successful High-Performance Arm-based designs
- Highly focused HPC workloads on x86 with compute bottlenecks
(Note that Intel calls its SMT implementation ‘HyperThreading’, which is a marketing term specifically for Intel).
At this point, we've only been discussing SMT where we have two threads per core, known as SMT2. Some of the more esoteric hardware designs go beyond two threads-per-core based SMT, and use up to eight. You will see this stylized in documentation as SMT8, compared to SMT2 or SMT4. This is how IBM approaches some of its designs. Some compute-in-memory applications go as far as SMT24!!
There is a clear trend between SMT-enabled systems and no-SMT systems, and that seems to be the marker of high-performance. The one exception to that is the recent Apple M1 processor and the Firestorm cores.
It should be noted that for systems that do support SMT, it can be disabled to force it down to one thread per core, to run in SMT1 mode. This has a few major benefits:
It enables each thread to have access to a full core worth of resources. In some workload situations, having two threads on the same core will mean sharing of resources, and cause additional unintended latency, which may be important for latency critical workloads where deterministic (the same) performance is required. It also reduces the number of threads competing for L3 capacity, should that be a limiting factor. Also should any software be required to probe every other workflow for data, for a 16-core processor like the 5950X that means only reaching out to 15 other threads rather than 31 other threads, reducing potential crosstalk limited by core-to-core connectivity.
The other aspect is power. With a single thread on a core and no other thread to jump in if resources are underutilized, when there is a delay caused by pulling something from main memory, then the power of the core would be lower, providing budget for other cores to ramp up in frequency. This is a bit of a double-edged sword if the core is still at a high voltage while waiting for data in an SMT disabled mode. SMT in this way can help improve performance per Watt, assuming that enabling SMT doesn’t cause competition for resources and arguably longer stalls waiting for data.
Mission critical enterprise workloads that require deterministic performance, and some HPC codes that require large amounts of memory per thread often disable SMT on their deployed systems. Consumer workloads are often not as critical (at least in terms of scale and $$$), and so the topic isn’t often covered in detail.
Most modern processors, when in SMT-enabled mode, if they are running a single instruction stream, will operate as if in SMT-off mode and have full access to resources. Some software takes advantage of this, spawning only one thread for each physical core on the system. Because core structures can be dynamically partitioned (adjusts resources for each thread while threads are in progress) or statically shared (adjusts before a workload starts), situations where the two threads on a core are creating their own bottleneck would benefit having only a single thread per core active. Knowing how a workload uses a core can help when designing software designed to make use of multiple cores.

Here is an example of a Zen3 core, showing all the structures. One of the progress points with every new generation of hardware is to reduce the number of statically allocated structures within a core, as dynamic structures often give the best flexibility and peak performance. In the case of Zen3, only three structures are still statically partitioned: the store queue, the retire queue, and the micro-op queue. This is the same as Zen2.
SMT on AMD Zen3 and Ryzen 5000
So much like AMD’s previous Zen-based processors, the Ryzen 5000 series that uses Zen3 cores also have an SMT2 design. By default this is enabled in every consumer BIOS, however users can choose to disable it through the firmware options.
For this article, we have run our AMD Ryzen 5950X processor, a 16-core high-performance Zen3 processor, in both SMT Off and SMT On modes through our test suite and through some industry standard benchmarks. The goals of these tests are to ascertain the answers to the following questions:
- Is there a single-thread benefit to disabling SMT?
- How much performance increase does enabling SMT provide?
- Is there a change in performance per watt in enabling SMT?
- Does having SMT enabled result in a higher workload latency?*
*more important for enterprise/database/AI workloads
The best argument for enabling SMT would be a No-Lots-Yes-No result. Conversely the best argument against SMT would be a Yes-None-No-Yes. But because the core structures were built with having SMT enabled in mind, the answers are rarely that clear.
Test System
For our test suite, due to obtaining new 32 GB DDR4-3200 memory modules for Ryzen testing, we re-ran our standard test suite on the Ryzen 9 5950X with SMT On and SMT Off. As per our usual testing methodology, we test memory at official rated JEDEC specifications for each processor at hand.
| Test Setup | |||||
| AMD AM4 | Ryzen 9 5950X | MSI X570 Godlike |
1.B3T13 AGESA 1100 |
Noctua NH-U12S |
ADATA 4x32 GB DDR4-3200 |
| GPU | Sapphire RX 460 2GB (CPU Tests) NVIDIA RTX 2080 Ti |
||||
| PSU | OCZ 1250W Gold | ||||
| SSD | Crucial MX500 2TB | ||||
| OS | Windows 10 x64 1909 Spectre and Meltdown Patched |
||||
| VRM Supplimented with Silversone SST-FHP141-VF 173 CFM fans | |||||
Also many thanks to the companies that have donated hardware for our test systems, including the following:
| Hardware Providers for CPU and Motherboard Reviews | |||
| Sapphire RX 460 Nitro |
NVIDIA RTX 2080 Ti |
Crucial SSDs | Corsair PSUs |
 |
 |
 |
 |
| G.Skill DDR4 | ADATA DDR4-3200 32GB |
Silverstone Ancillaries |
Noctua Coolers |
 |
|
 |
 |









126 Comments
View All Comments
MrSpadge - Friday, December 4, 2020 - link
That doesn't mean SMT is mainly responsible for that. The x86 decoders are a lot more complex. And at the top end you get diminishing performance returns for additional die area.Wilco1 - Friday, December 4, 2020 - link
I didn't say all the difference comes from SMT, but it can't be the x86 decoders either. A Zen 2 without L2 is ~2.9 times the size of a Neoverse N1 core in 7nm. That's a huge factor. So 2 N1 cores are smaller and significantly faster than 1 SMT2 Zen 2 core. Not exactly an advertisement for SMT, is it?Dolda2000 - Friday, December 4, 2020 - link
>Graviton 2 gives 75-80% of the performance of the fastest Rome at less than a third of the areaTo be honest, it wouldn't surprise me one bit if 90% of the area gives 10% of the performance. Wringing out that extra 1% single-threaded performance here or there is the name of the game nowadays.
Also there are many other differences that probably cost a fair bit of silicon, like wider vector units (NEON is still 128-bit, and exceedingly few ARM cores implement SVE yet).
Wilco1 - Saturday, December 5, 2020 - link
It's nowhere near as bad with Arm designs showing large gains every year. Next generation Neoverse has 40+% higher IPC.Yes Arm designs opt for smaller SIMD units. It's all about getting the most efficient use out of transistors. Having huge 512-bit SIMD units add a lot of area, power and complexity with little performance gain in typical code. That's why 512-bit SVE is used in HPC and nowhere else.
So with Arm you get many different designs that target specific markets. That's more efficient than one big complex design that needs to address every market and isn't optimal in any.
whatthe123 - Saturday, December 5, 2020 - link
The extra 20% of performance is difficult to achieve. You can already see it on zen CPUs, where 16 core designs are dramatically more efficient per core in multithread running at around 3.4ghz, vs 8 core designs running at 4.8ghz. I've always hated these comparisons with ARM for this reason... you need a part with 1:1 watt parity to make a fair comparison, otherwise 80% performance at half the power can also be accomplished even on x86 by just reducing frequency and upping core count.Wilco1 - Saturday, December 5, 2020 - link
Graviton clocks low to conserve power, and still gets close to Rome. You can easily clock it higher - Ampere Altra does clock the same N1 core 32% higher. So that 20-25% gap is already gone. We also know about the next generation (Neoverse N2 and V1) which have 40+% higher IPC.Yes adding more cores and clocking a bit lower is more efficient. But that's only feasible when your core is small! Altra Max has 128 cores on a single die, and I don't think we'll see AMD getting anywhere near that in the next few years even with chiplets.
peevee - Monday, December 7, 2020 - link
It is obviously a lot LESS than 5%. Nothing that matters in terms of transistors (caches and vector units) increases. Even doubling of registers would add a few hundreds/thousands of transistors on a chip with tens of billions of transistors, less than 0.000001%.They can double all scalar units and it still would be below 1% increase.
Kangal - Friday, December 4, 2020 - link
I agree.Adding SMT/HT requires something like a +10% increase in the Silicon Budget, and a +5% increase in power draw but increases performance by +30%, speaking in general. So it's worth the trade-off for daily tasks, and those on a budget.
What I was curious to see, is if you disabled SMT on the 5950X, which has lots of cores. Leaving each thread with slightly more resources. And use the extra thermals to overclock the processor. How would that affect games?
My hunch?
Thread-happy games like Ashes of Singularity would perform worse, since it is optimised and can take advantage of the SMT. Unoptimized games like Fallout 76 should see an increase in performance. Whereas actually optimised games like Metro Exodus they should be roughly equal between OC versus SMT.
Dolda2000 - Friday, December 4, 2020 - link
>What I was curious to see, is if you disabled SMT on the 5950X, which has lots of cores.That is exactly what he did in this article, though.
Kangal - Saturday, December 5, 2020 - link
I guess you didn't understand my point.Think of a modern game which is well optimised, is both GPU intensive and CPU intensive. Such as Far Cry V or Metro Exodus. These games scale well anywhere from 4-physical-core to 8-physical-cores.
So using the 5950X with its 16-physical-cores, you really don't need extra threads. In fact, it's possible to see a performance uplift without SMT, dropping it from 32-shared-threads down to 16-full-threads, as each core gets better utilisation. Now add to that some overclocking (+0.2GHz ?) due to the extra thermal headroom, and you may legitimately get more performance from these titles. Though I suspect they wouldn't see any substantial increases or decreases in frame rates.
In horribly optimised games, like Fallout 76, Mafia 3, or even AC Odyssey, anything could happen (though probably they would see some increases). Whereas we already know that in games that aren't GPU intensive, but CPU intensive (eg practically all RTS games), these were designed to scale up much much better. So even with the full-cores and overclock, we know these games will actually show a decrease in performance from losing those extra threads/SMT.