AnandTech Interviews Mike Clark, AMD’s Chief Architect of Zen
by Dr. Ian Cutress on October 26, 2021 8:00 AM EST- Posted in
- CPUs
- AMD
- Zen
- Ryzen
- Interviews
- Mike Clark

AMD is calling this time of the year as its ‘5 years of Zen’ time, indicating that back in 2016, it was starting to give the press the first taste of its new microarchitecture which, in hindsight, ultimately saved the company. How exactly Zen came to fruition has been slyly hidden from view all these years, with some of the key people popping up from time to time: Jim Keller, Mike Clark, and Suzanne Plummer hitting the headlines more often than most. But at the time AMD started to disclose details about the design, it was Mike Clark front and center in front of those slides. At the time I remember asking him for all the details, but as part of the 5 Year messaging, offered Mike for a formal interview on the topic.
Michael T Clark is a Corporate Fellow at AMD, starting at the company in 1993, fresh out of his degree at Illinois Urbana-Champaign. His role has evolved from a base engineer in processor design, all the way up to Lead Architect on several of AMD’s key processor designs, all the way to Chief Architect of Zen. Exactly what Mike has done in the meantime is somewhat of a mystery, so I get to probe him on that as well! Currently Mike is in charge of Zen and its roadmap, both for the products in the market today to several generations away from now. Unfortunately Mike won’t disclose what’s in Zen 7 just yet, but it was worth asking.
Mike Clark Zen Lead Architect, AMD |
 Dr. Ian Cutress AnandTech |
Ian Cutress: You’ve been at AMD since 1993, from leaving university, which is almost 30 years. It was funny to try and find some sort of documented work history for you through your time at AMD - aside from your Zen appearances there is little to go on! Could you give us an overview of some of those projects you’ve worked on and what you did on them on your way up to Zen?
Mike Clark: So I started right out of school, right out of the University of Illinois, and started work on K5. That was our first ground-up [design] on x86, which was awesome. [When I finished university], I had several offers, but I chose AMD because it was the only one that actually let me own a block of the CPU design, which back then was crazy! Not only did you own the RTL, you owned the verification of your own block (and we learned that's a really bad idea). You owned the physical design, you had a physical designer you worked with, but you ran the synthesis tools yourself. So you took your block, and went from soup to nuts (beginning to end).
So that's what I kind of cut my teeth on, to learn the discipline. I was also on the TLB, and nobody knew how an x86 TLB worked back then. Since we were just second sourcing Intel, I had to go lower and figure out and reverse engineer how the x86 TLB works - it was a ton of fun! I learned a lot.
From there we ended up buying NexGen, getting K6, and I helped integrate it in. Then we did K7, and I was like the lead microcode guy on K7. That was what I call the Dream Team - each block lead on K7 was just awesome. I learned so much from those guys and that's where I really learned how to build a great microarchitecture.
From there, I did the Greyhound (K9) core, I was the lead architect there, which was a derivative of K8. Then we were doing the whole Bulldozer thing - I worked on that. I was a Lead Architect on the Steamroller version, but I worked on all of them in different roles. Then I became the Lead Architect of Zen.
I'm in charge of the whole Zen roadmap now, but here at AMD a Lead Architect goes from high-level design, all the way to silicon, then to post silicon by engaging with customers. You really learn which of your decisions were good and which were bad. You feel the pain when you hear work is put on the software community [that didn’t need to be], and so you do better the next time. You really are with the design for a long time, and I really believe in the fact that you don't just work though pre-silicon, or even the execution phase, and just move on - you have to feel the pain of everything in your design, so you can be a better architect.
So now I run the roadmap, and then we have a team of great people who are now lead architects on all the Zen architectures.
IC: What would your official title be then?
MC: Leader of the Core Architecture, or Leader of the Core Roadmap I would say. I don't really think about titles that much.
Zen: The Beginning
IC: This quarter for AMD is all about the 5 Years of Zen and Ryzen, ever since those press events and first microarchitecture disclosures at Hot Chips in August 2016. Realistically, when did the Zen journey start for you - who were the big names, and were you the lead architect off the bat?
MC: Well, it started in 2012 for me. We realized we needed to do something different from the Bulldozer line. Jim came in and helped re-organize the team, and I was the Lead Architect. So it's been almost 10 years for me.
For personnel, since we started in 2012, there are so many people, and the team is awesome. I am so thankful that I get to represent the work of so many awesome engineers. Suzanne Plummer was the lead of the Zen team, managing the team, and was just keeping the team together, she was just awesome. Then there’s also Mike Tuuk, Tim Wilkens, Jay Fleischman, Leslie Barnes - all kinds of people that were contributing from all parts of the company to make Zen a success.
So it's kind of funny to say I’ve been working on it since 2012 - if I go back, I still have our HLD (High-Level Design) deck that we did for Zen. You wouldn't believe how different, after taking five years to get something to production, it looks. I mean the bones are still there, you see it, but so many things changed along the way. That's one of the keys of this business - being able to be dynamic and have things change because it's such a long time. But also still be able to deliver a competitive design, it’s pretty amazing. Once in a while, when we were starting up, when the teams were worried or feeling weird about their HLD, I'm the one who turned around and said that ‘this is what Zen was, everything's not going to be perfect coming out HLD, stuff is going to change, and it's going to get better’. So that's the art of this job.
IC: Is it ever realistic to be able to pivot a design based on what competitors just released? Or is do you still have that two year lead on changes?
MC: It matters - we can. You'd be surprised at how quickly we can respond. It still feels like a long time, but we're constantly evaluating the competition and comparing ourselves to them, trying to make sure we're staying on track. One part of it is that we have to set our own goals as well. We can't wait for them, and that's when we've seen historically what has happened in the industry - we set those aggressive goals for ourselves and just try to hit them independent of what the competition is doing as well. Now we keep our eyes on them of course.

IC: One of the cool stories out of the Ryzen saga is that CPU development funding was frozen and ring-fenced away from the rest of the business, at a time when AMD was struggling financially. How did that benefit you, or did any limitation manifest from your perspective, either practically or emotionally?
MC: It definitely takes a big investment because of the long timeframe. With that long lead time, it's tough for the business - the market wants a product every year, and you keep trying to refresh, waiting for the new big thing to come. So it was definitely necessary so that we could do what we needed to do to get the job done.
It was a tough time. I mean, one of the hardest problems we had was holding the team together. A lot of people did leave, and it was a very aggressive programme. From where we were, we spent a lot of time both trying to convince people that we would succeed. Even with succeeding, we still knew that if the competition keeps going on at their track, they may still be ahead of us when the first one comes out. That's what we needed to do to get a solid base out there, then bring out Zen 2 and Zen 3, and really we get ourselves on a trajectory where we can be a leader in the industry.
IC: In a recent interview I had with Jim Keller, Jim mentions a large 8am meeting on chip design - lots of disagreements, but he mentioned you were one of the people who had a staunch belief that you could succeed. What was it like to be summoned to that meeting, discussing those ideas, and looking back to the success Zen has had?
MC: For me, it's awesome! That engineering exchange is what we would call ‘concept’, which we do for every big project. At that time, for such a big transition, I would say there were probably more arguments than usual.
I mean, we hadn't done SMT before, and we hadn't done an micro-op cache before, and there were a lot of people that thought that doing both of those in the same core was going to be a disaster. I had to convince people. With the Bulldozer threading model, we learned a lot, and there's a lot of SMT-like stuff in Bulldozer, so we've learned the ways to do SMT even though we hadn't done it in the execution unit or the data cache. So it wasn't really that big of a step for us as it would be for someone who done none of it before.
With the micro-op cache, we did a similar thing on a project that got cancelled, and really we should have been doing in Bulldozer 2. For Zen, we needed to do it to hit our hit aggressive goal of a 40% IPC uplift. I think from discussions like that, the people who saw it was possible stayed on, and some of those who thought it was not possible decided to go their own way.
But that's engineering, right? I mean, it's tough. We know that engineers are good at smelling out bullshit, so you have to be very careful that you don’t give them completely impossible goals - they'll see that it's impossible, and they won't set themselves set up to fail. You can’t have easy goals either, so you have to find that nice balance of not impossible goals but really hard goals, and then tell them if we don't get there, it's still going to be alright as well. But we have to set these aggressive goals, and if get the engineers on-board, you'd be amazed at how hard they work to get it done.
IC: I asked Jim if he was the father of Zen, and he said he was one of the ‘crazy uncles’. Are you the father of Zen?
MC: I definitely agree with Jim that it took a lot of people to make Zen. But yeah, I think I am the father of Zen - I mean, in the sense that I gave its name. I was there in 2012 on the first day, and I was with it all the time. I know everything good and bad about it, just like parents know their own kids - you know what they're good at, and what they're not so good at, and I've felt the pain of all our bad parts, and I've seen the joy of all our goodness. But like a child you know, you have it, like you have the chip, and you finally have to let it out in the world. You don't have control over it anymore! You don’t have control, and other people judge it, and you take it personally. I’ve been with this for so long, five years since those first disclosures, and I get emotionally invested. Because of that, you know, other people can come and go and move on, but I’ve been with Zen from the beginning to the end. So I do consider myself a Father in that respect. But then like I said, it took an amazing team to make it happen - I didn't make it happen by myself, just like raising the child doesn't have one person either. It takes so many people.

IC: Recently AMD CMO John Taylor mentioned that there’s an interesting story behind the Zen and Ryzen naming. What’s that story?
MC: So with the Bulldozer architecture, I guess I've learned over all those years that building x86 cores is all about finding the right balance in the architecture between frequency, IPC, power, and area. We weren't there with Bulldozer, and so I felt that our new project needs a name that talks about what our true goal is, which is to have a balanced architecture. ‘Zen’ as a name made sense to me for what we're doing.
I think that from the Ryzen point of view, when they showed it to me the first time, they were a little nervous that I might not like it. But when I saw it, when I saw the Enzo, when I saw it was an open Enzo, with the beauty of imperfection (and we know Zen is not perfect, all cores have their problems), it just perfectly represented what I thought of when I named it in 2012. It was as though it was just this perfect synergy. No one really had talked to me about it until they showed it to me, I think they were nervous. When they showed it to me, it's like, that is awesome. It was exactly what I was thinking without even telling them.
IC: Then when the lawyers came back and said, yes, we can trademark it, you're two thumbs up!
MC: [laughs] One thing I love is that it sounds a lot like rising, as in Ryzen and rising. It has that secondary feel to that - I thought it was brilliant that AMD was rising back up. It's just genius marketing and naming to me.
IC: Alongside Zen we learned about Project Skybridge, the ability to put an x86 SoC and an Arm SoC on the same socket. Do you know how far along the Arm version of Skybridge, we know as K12, was in development before AMD went full bore for Ryzen?
MC: Originally Zen and K12 were, I think, we call them sister projects. They had kind of the same goals, just a different ISA actually hooked up. The core proper was that way, and the L2/L3 hierarchy could be either one. Then of course, in Skybridge, the Data Fabric could be either one. There was a whole team doing the K12, and we did share a lot of things you know, to be efficient, and had a lot of good debates about architecture. Although I've worked on x86 obviously for 28 years, it's just an ISA, and you can build a low-power design or a high-performance out any ISA. I mean, ISA does matter, but it's not the main component - you can change the ISA if you need some special instructions to do stuff, but really the microarchitecture is in a lot of ways independent of the ISA. There are some interesting quirks in the different ISAs, but at the end of the day, it's really about microarchitecture. But really I focused on the Zen side of it all.

Core Design
IC: When we talk about cores and products, it’s always about time to market and meeting deadlines. Realistically, how shortly after the design is signed off do you start thinking about how things could have been design better, and where the low hanging fruit is?
MC: A year even before a first tape-out, you realize the funny thing about microarchitecture is that certain decisions drive certain decisions that drive certain decisions, so if the first decision was bad, there's a lot of rework to get back down the right track. We try to make those first decisions as best as we can, but when some of them need to be redone, it's too late. Hopefully any issues are with decisions that are further down the path. But that's kind of the reality of microarchitecture.
But that that is kind of where we maybe see our strategy is. We know that when we do a grounds up redesign [of a core], that there are going to be a lot of those opportunities to improve what we did before [with an updated derivative]. So we want our derivative chip to be a big derivative, and make it worth the 12 to 18 months it's going to take to get it done. Then having done that, we know that doing a second derivative isn’t usually worth the effort - there's not much you can gain from that in a performance/power view. You could always add more to it, but you have more power, and you kind of bolt things more on the side rather than really get in and redo the guts of the machine.
So our strategy is really to do grounds up design, do a derivative, and then come back with another totally ground-up design where we re-thought everything through the pipeline. We may still reuse things, like we still have an OP cache and we're not getting rid of OP cache, but we might end up doing it in a much different way, such as a way where it interfaces with instruction cache, or the way it feeds into machine changes. Perhaps we need to rethink how it works to get it wider, and we have to really rethink the concept, not simply just make the dispatch or execute wider. The whole machine has to understand that, so we have to basically tear up the whole thing and put it down in block diagrams on a clean sheet of paper. That means that as you go along, and as our guys go to code it, it's a case of finding which parts aren’t changing, reusing code, or building new. We still use parts of the old designs, and if it's a part that isn't really changing this time, we might decide that it is good enough for this design.
So every three years, we're pretty much redesigning it all. We have to manage the power so we can put these widgets in a whole new pipeline and really control the power of them so they don't just burn all the extra power equivalent to the IPC.
First A0 Zen Needed Chilling
IC: Are you the sort of architect that will be in the room during the bring-up of the first silicon back from the fabs? And if so, what's that like? What's the atmosphere in the room?
MC: I would love to, but a lot of times they won't even let me in there! I get in there later. When it first comes back, there's a lot of bring up activities with BIOS and firmware that really don't even involve the core. So there's not a lot of need for myself or the lead architect of that generation at that time. But very quickly, as the team brings it up and gets it going and booting, is when it matters.
On the original Zen, one of the wonderfully funny stories I have is that I was the first A0 silicon, we definitely had some issues. We had to run it really cold to get it running. We were waiting for the fixed A1 to come back, or even it was A0+, to solve the issues so we didn't have to run it cold. One of the engineers was like ‘have you tried out the patch on it yet?’ – I say ‘no, I'm sitting here waiting for it to dry’. When we keep it so cold that condensation builds up, every so often we have to stop, let it dry off. Then as soon as it dries off, I'll let you know if your patch worked. It's crazy, but I love a working lab - I'm definitely an architect who likes to get his hands dirty. Unfortunately I don't get to get them as dirty as I used to, and I get involved usually much later when you have really hard problems.
IC: So it's funny that you bring up that story, because I'm kind of interested in it. When you get that A0 silicon back, and it doesn't work right at normal temperature, what tells you that you have to put it on cold? Who thinks of that? How does one come to the idea that that is what it needs to do just to run properly? And then how do you go about finding the fix for A0? Plus, is that a design fix? Or is it a manufacturing fix? How do you find the difference between the two?
MC: Now in that case, we have lots of ways to test the silicon, you know. We have DFT (design for test) teams to realize that low level circuits aren't working properly. We have strong circuit team that does debug issues like this, and they realize it’s a problem with temperature, but then suggest if it was cold, you can still work on it. They also say what is wrong with the circuit so that it can be fixed and build an A0+, to get things that can run at normal temps. Again, the amount of great engineers working on any given product here at AMD is amazing, and I like to think of myself as well rounded, but there are people that are just way better than me at a lot of things!
Future Design Considerations
IC: One of the modern design choices of the modern x86 core is the decode width of the variable instruction set - Intel and AMD's highest performance cores, all the way back since Ryzen, have been 4-wide. However, we're seeing dual 3-wide designs or 6-wide designs, relying on the op-cache to save power. Obviously 4-wide was great for AMD in Zen 1, and we're still at 4-wide for Zen 3: where does the roadmap go from here, and from a holistic perspective how does the decode width size of x86 change the fundamental IPC modelling?
MC: I think it comes back to that balance aspect, in the sense that I think going beyond four with the number of transistors and the smarts we have in our branch predictor, and the ability to feed it worked fine. But we are going to go wider, you're going to see us go wider, and to be efficient, we'll have the transistors around the front end of the machine to make it the right architectural decision. So it's really having the continuous increase in transistors that we get, allowing us to beef up the whole design to continue to get more and more IPC out of it.
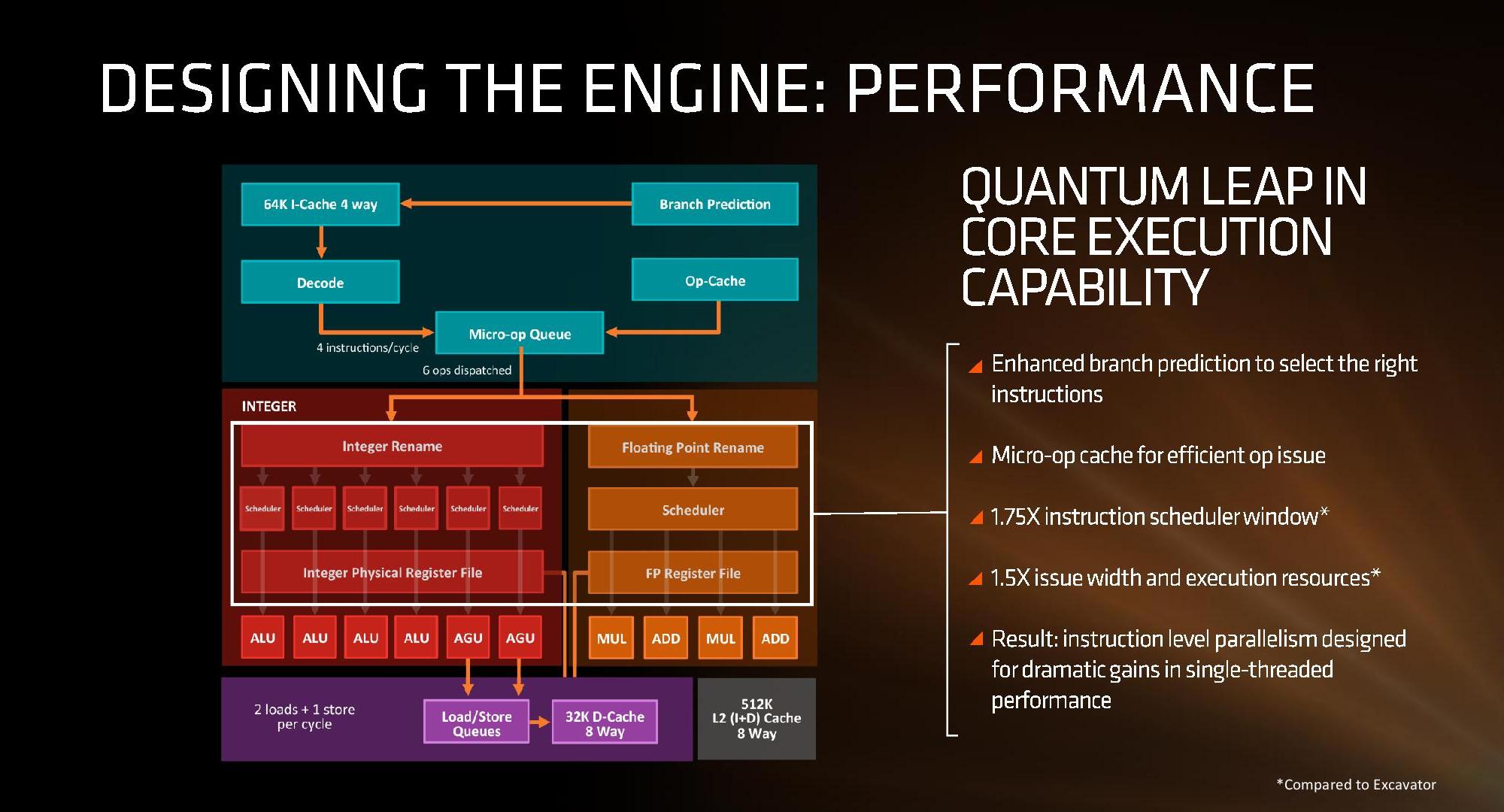
IC: How reliant are you on your competitive analysis and workload prediction teams when it comes to the basic floorplan designs? If you're back in 2012, trying to predict 20 16 workloads, that's a bit of a leap?
MC: We have great teams there, and in some sense, the problem you're stating is kind of independent of the team. Either you're trying to build a processor on the software of today, or the software five years from today. That's where a lot of it comes down to experience as an architect, understanding seeing what you're seeing in the performance traces, but also going beyond and realizing the wider implications. With the four-wide decode for example, a lot of the compilers have optimizations they do because you have a four wide machine. But when we give them something wider, they will be updated to realize how to compile the code to make it even better. So we'll see we only managed to get 10 to 15% IPC on these older codes that when we launched, but as the compilers developed, they'll be able to extract more and more out of our future designs based on what they get out from our current design.
IC: On the concept of cache – AMD’s 3D cache announcement leading to products coming next year is obviously quite big. I'm not going to ask you about specific products, but the question is more about how much cache is the right amount? It’s a stupidly open ended question, but that's the way it's intended!
MC: It's a great question! It's not just even about how much is the right amount, but at what level, what latency, what is sharing the cache and so on. As you know, those are all trade-offs that we have to decide how to make, and understand what that will mean for software.
We have chosen that our core complex is going to have to a split L3 (in VCache). If we had one gigantic L3 shared across all the threads, the more you share a giant L3 across the threads, the latency of a given thread gets longer. So you're making a trade-off there of sharing, or getting more capacity and a lower thread count versus the latency it takes to get it. So we balanced for trying to hit on that lower latency, providing great capacity at the L3 level. That's the optimization point we've chosen, and as we continue to go forward, getting more cores, and getting more cores in a sharing L3 environment, we’ll still try to manage that latency so that when there are lower thread counts in the system, you still getting good latency out of that L3. Then the L2 - if your L2 is bigger then you can cut back some on your L3 as well.
So it's a fascinating field - cache trade off studies have been going on forever, and they will continue forever of how to balance out the cache hierarchy for the core.
IC: It’s funny that you bring up the L2, because I'm not sure if you saw IBM's recent announcement on their z16 / Telum chip. They've got very large L2 caches, but they're using them as a virtual L3 as well. Have you looked into that at all, and does that seem appetizing?
MC: Yeah, we've definitely looked into it. Will Walker is the head of our cache team, and he is an awesome architect. Like I said, every HLD (High Level Design) we go through the same questions, the same designs, look at different design points, and then have to settle on one of them. Even sometimes post HLD, things change, and if we decided to switch to a different design point, we can do that. So yeah, it's a constant evolving architecture.
IC: TSMC has showcased an ability to stack 12 die with TSVs, similar to the V-Cache concept. Realistically, how many layers could be supported before issues such as the thermals of the base die become an issue?
MC: There’s a lot to architecting those levels beyond the base architecture, such as dealing with temperature, and there's a lot of cost too. That probably doesn’t answer your question, but different workloads obviously have different sensitivity to the amount of cache, and so being flexible with it, being able to have designs both with stacking and without stacking, is critical because some workloads. [Always having stacked cache] would be way too expensive for the performance uplift it would bring for some use cases. I can't really comment on how many levels of stacking we can do or we will do, but it's an exciting technology that kind of continues to grow.
IC: To what extent has AMD incorporated machine learning into its EDA tools? Both at this point, or to what extent in the future?
MC: I don't think I'm allowed to say that definitively, but I think, you can probably assume that everyone is using some form of machine learning through data to improve everything in all our business processes.
IC: So that’s a very careful answer!

IC: Initially Zen started with a 4-core CCX, and now the base in Zen 3 is an 8-core complex. Are there limits to how big the complex can be in its current form, such as the ring bus, and what things have to change as that complex grows?
MC: We build a very modular core cache hierarchy for all our different markets, from high-end servers all the way down to the low-end notebooks. So those environments desire more or fewer cores, and trying to meet them efficiently with as few designs as possible is also another interesting architectural goal. You would like to think you can just focus on one design at a time, such that we have a core roadmap for X or Y and there can be multiple of them, but there's not. We have to figure out how to leverage those designs across all those markets. Some markets like the high-end server are going crazy for more cores, whereas others are not increasing their consumption of cores at the same rate. We do see core counts growing, and we will continue to increase the number of cores in our core complex that are shared under an L3. As you point out, communicating through that has both latency problems, and coherency problems, but though that's what architecture is, and that's what we signed up for. It’s what we live for - solving those problems. So I'll just say that the team is already looking at what it takes to grow to a complex far beyond where we are today, and how to deliver that in the future.
IC: Do you see any part of the Xilinx acquisition becoming part of the Ryzen future?
MC: Oh, definitely. I can't really comment on anything particular. We sell SoCs, but we obviously integrate a lot of IP into them. If you look their IP and our IP, you can probably see some natural synergy there that you will likely see in the future. I look forward to getting those guys on board and working with them going forward. It’s a great team.
IC: IPC is always a golden goal of high-performance processor design, and one of the benefits of smaller process nodes is more transistors, bigger buffers, more execution ports, and larger caches. How do you approach how to make the core ‘smarter’, rather than simply ‘bigger’, and what key elements in modern x86 designs are the limiting factors?
MC: I think IPC gets all the glory! What it really is – I call it the ‘Wheel of Performance’ because there's four main tenets – performance, frequency, area and power. They really are all equal in a sense and you have to balance them all out to get a good design. So if you go for a really high frequency but crush IPC, you can end up with a really bad design, and increased area. If you go really hard on IPC and that adds a lot of area and a lot of power, you can be going backwards. So that's really the critical part like we said, we're trying to get that IPC but we have to get it in a way that optimizes the transistor use for both area and power, and frequency too. We want to be able to put a bunch of cores in and just add IPC and grow area, we're not making real progress.
I get it, that's my job, and it’s my Lead Architects’ job to try to find that right balance. I think that was one of the biggest part of Zen – power had been a strong part of what we cared about. We looked at power like everything else in the wheel, and from the high-level execution we would get weekly feedback on how we're doing, know what area we used, and know what our IPC is. Actually, we did not have right tools early in the design to let us know where we were in power, and by the time we did, there was very little we could do - we were in that deep in execution where those decisions were made that if we had to redo a bad power design, we would have to rip up the whole thing and we would never hit schedule now.
For the original Zen, we had to go create those new tools, and it was really a stress point on the team. Since they were new, a lot of it is just that it was so early in the design, and they weren’t perfect, none of our performance or frequency tools were perfect, but people use them enough that they trust them. We had to really come in with the knowledge that those tools weren’t perfect, but if you get the vectors right, and we're making decisions, that they're good enough and we managed to get over that hurdle and really properly use them.
Feedback is like any other part of the design. Being able to drive that 40% IPC in a more efficient design with Zen - that was one of the first sticking points we said about it, but if you are going to have 40% more IPC but add 40% power, it won’t go anywhere.

IC: In a recent AMD video on the 5 Years of Zen celebration, it was discussed that having a more scalable core was the preferred approach for the future compared to a hybrid design. Where are the difficulties in building a core with that much scale, from milliwatts to dozens of watts per core - is it specifically in logic design, power design, or manufacturing?
MC: I mean it's all of those! As an architect, we have to consider all the markets we're wanting to focus on. If I want to hit this IPC at this frequency at this power, we can't think of the core as one thing and one set of targets - it has to be many sets of targets, and have it planned like that from the beginning. How it's going to scale up and down into those markets has been another part of the Ryzen and Zen success, in that we haven't solely been trying to use technology to fit a different hole of the market. We thought about how to scale to all those markets, and designed it to be capable of doing that upfront. That way it's easy for the backend to change the product for those different markets and execute.
IC: Long-term R&D roadmaps are usually quoted at the 3/5/7 year timescale. As AMD has grown, especially recently, how has that changed inside AMD for you?
MC: Not really. I mean, even back in 2012 we were thinking well beyond Zen, especially since your customers demand it, right? They're not going to switch over to using you if you don't have a long term roadmap. Our customers demand that when they want to do business with us, and of course our own teams demand that they want - our teams want to see a roadmap! There were a lot of people, even internally, that were worried we weren't going to be able to sustain the rate of progress. It is a very risky strategy, - tearing the whole core up every three years is risky. But to me, I've managed to convince everyone, and it’s what the market requires. If we don't do it, someone else will.
Zen 5, Zen 8, and Everything Else
IC: You mentioned in a publicity video in April 2018 for AMD that you were working on Zen 5. We’re three years on - does that mean you’re working on Zen 8 now?
MC: You’ve done the math pretty well, I’ll say that! I got a little flak saying that (in 2018) by the way, but I think you know how hard this business is. Like I was saying earlier, you have to be dynamic and willing to have a process that you can change as the market changes around you. If you build exactly what you set out to do on day 1, you'll put out something that nobody wants.

IC: Finally, what should AMD users look forward to?
MC: It's going be great! I wish I could tell you of all what's coming. I have this annual architecture meeting where we go over everything that's going on, and at one of them (I won't say when) the team and I went through Zen 5. I learned a lot, because of nowadays as running the roadmap, I don't get as close to the design as I wish I could. Coming out of that meeting, I just wanted to close my eyes, go to sleep, and then wake up and buy this thing. I want to be in the future, this thing is awesome and it's going be so great - I can't wait for it. The hard part of this business is knowing how long it takes to get what you have conceived to a point where you can build it to production.
Many thanks to Mike Clark and his team for their time.
Many thanks to Gavin Bonshor for transcription.








115 Comments
View All Comments
Bambel - Thursday, October 28, 2021 - link
It's one thing to say "ISA doesn't matter" and it's another thing to proof that. Why is there no x86 core that has the same efficiency like Apples cores? Build it and i believe it.BTW: Apples efficiency comes from the relatively low frequency that their cores run at and it's not just TSMCs 5N process. Intel, AMD an Apple have give or take the same performance but, while Apples run at 3.2 GHz, intel and AMDs need about 5 GHz to deliver the same performance. If you build intel or AMD cores on the same 5N and run them at 5 Ghz they will draw much more power than at 3.2 GHz.
And this relationship between clock speed and power isn't new. Ask the folks at intel who designed the P4. So again: why is there no x86 core that only needs to run at 3.2 GHz for the same performance? Strange, isn't it?
mode_13h - Thursday, October 28, 2021 - link
> Apples run at 3.2 GHz, intel and AMDs need about 5 GHz to deliver the same performance.How do the cores compare in terms of area? Because Intel and AMD have both designed cores that they sell into the server market. So, if Apple is delivering less performance per transistor, maybe that's a reason Intel and AMD didn't increase the width of their uArch at the same rate as Apple.
mode_13h - Thursday, October 28, 2021 - link
I should've added that the reason area is relevant for the server market is due to the high core-count needed for servers. So, if Apple can't scale up to the same core counts, due to the area needed by their approach, that could be a key reason why Intel and AMD haven't gone as wide.Also, cost increases as a nonlinear function of area. So, perf/$ could be worse than their current solutions, on the nodes for which they were designed.
Bambel - Friday, October 29, 2021 - link
A few thoughts....- AFAIK most PCs sold today are laptops and intel lost Apples business because they were not satisfied with the efficiency of current (mobile-)CPUs. intel should have enough ressoures to develop different cores for different applications. The loss of Apple as a customer not only lost them money, it was also bad PR.
- x86 CPUs have to clock down for thermal reasons in all core loads anyway, so they could design them to run at lower clock speeds from the beginning. So pretty much what is needed in a laptop. BTW: the new E-cores in ADL are much smaller and seem to be very efficient both in area and thermals. Maybe it's a starting point for a new P-core. The "core" architecture was derived from the Pentium M which was "only" a mobile chip at the beginning but evolved into much more. Funny enough, Apples stuff originated in mobile as well, so it seems that it makes more sense to focus on efficiency first and than scale performance. Both intel and AMD seem to have done it the other way round in recent years.
- Looking at a lot of die-shots i have the impression that caches and uncore are larger than the cores themselves, so i'm not sure area is the culprit. And chiplets mitigate that anyways for high core count CPUs.
Will be interressting to see what AMD can achieve with ZEN 4. I don't expect it to reach Apples IPC, but should be closer than today.
GeoffreyA - Friday, October 29, 2021 - link
I've always felt that Gracemont will lead to their main line of descent. They're slowly working the design up.mode_13h - Saturday, October 30, 2021 - link
> I've always felt that Gracemont will lead to their main line of descent.It depends on what people want and are willing to pay for. There are currently Atom server CPUs with up to 16 cores. If the version with Gracemont is popular (maybe with even more cores), then they'll probably expand their server CPU offerings with E-cores.
mode_13h - Saturday, October 30, 2021 - link
> intel should have enough ressoures to develop different cores for different applications.They do. The Atom-line was for low-cost and low-power, while their other cores were for desktops, mid+ range laptops, and most servers.
What they haven't done is a completely separate core for servers. If they did that, then maybe they could make the desktop/laptop cores even bigger, although that would make them more expensive so maybe not.
> x86 CPUs have to clock down for thermal reasons in all core loads anyway
You're thinking of desktops & laptops, but not servers. Servers' clocks are limited by power, not thermals.
> the new E-cores in ADL are much smaller and seem to be very efficient both in
> area and thermals. Maybe it's a starting point for a new P-core.
They've recently done complete redesigns of their P-cores. I forget which one was the last redesign, but it might be the very P-core in Alder Lake. They don't need Gracemont as a "starting point". If Golden Cove's efficiency is bad, it's because they *decided* not to care about efficiency, not because of legacy.
> it seems that it makes more sense to focus on efficiency first and than scale performance.
> Both intel and AMD seem to have done it the other way round in recent years.
Apple didn't *only* focus on efficiency, in case you haven't been following their CPUs. They have consistently had far better performance than their competitors.
And neither AMD nor Intel can afford to come out with a lower-performing CPU that's simply more power-efficient. I mean, not in the main markets where they play. Obviously, Intel sells cost/efficiency-oriented CPUs for Chromebooks, and it sells specialty server CPUs based on the same "Mont" series cores.
> Looking at a lot of die-shots i have the impression that caches and uncore are
> larger than the cores themselves
That's not very helpful. You need to find someone who has done the analysis and made credible estimates of the number of transistors in the cores.
FreckledTrout - Tuesday, October 26, 2021 - link
What a well thought out interview. Thanks Ian.patel21 - Tuesday, October 26, 2021 - link
Would have loved some questions about their ARM endeavorsIan Cutress - Tuesday, October 26, 2021 - link
As shown by the K12 question, that's not what Mike's working on.