10Gbit Ethernet: Killing Another Bottleneck?
by Johan De Gelas on March 8, 2010 12:00 PM EST- Posted in
- IT Computing
In the second quarter of this year, we’ll have affordable servers with up to 48 cores (AMD’s Magny-cours) and 64 threads (Intel Nehalem EX). The most obvious way to wield all that power is to consolidate massive amounts of virtual machines on those powerhouses. Typically, we’ll probably see something like 20 to 50 VMs on such machines. Port aggregation with a quad-port gigabit Ethernet card is probably not going to suffice. If we have 40 VMs on a quad-port Ethernet, that is less than 100Mbit/s per VM. We are back in the early Fast Ethernet days. Until virtualization took over, our network intensive applications would get a gigabit pipe; now we will be offering them 10 times less? This is not acceptable.
Granted, few applications actually need a full 1Gbit/s pipe. Database servers need considerably less, only a few megabits per second. Even at full load, the servers in our database tests rarely go beyond 10Mbit/s. Web servers are typically satisfied with a few tens of Mbit/s, but AnandTech's own web server is frequently bottlenecked by its 100Mbit connection. Fileservers can completely saturate Gbit links. Our own fileserver in the Sizing Servers Lab is routinely transmitting 120MB/s (a saturated 1Gbit/s link). The faster the fileserver is, the shorter the waiting time to deploy images and install additional software. So if we want to consolidate these kinds of workloads on the newest “über machines”, we need something better than one or two gigabit connections for 40 applications.
Optical 10Gbit Ethernet – 10GBase-SR/LR - saw the light of day in 2002. Similar to optical fibre channel in the storage world, it was very expensive technology. Somewhat more affordable, 10G on “Infiniband-ish” copper cable (10GBase-CX4) was born in 2004. In 2006, 10Gbit Ethernet via UTP cable (10GBase-T) held the promise that 10G Ethernet would become available on copper UTP cables. That promise has still not materialized in 2010; CX4 is by far the most popular copper based 10G Ethernet. The reason is that the 10GBase-T PHYs need too much power. The early 10GBase-T solutions needed up to 15W per port! Compare this to the 0.5W that a typical gigabit port needs, and you'll understand why you find so few 10GBase-T ports in servers. Broadcom reported a breakthrough just a few weeks ago: Broadcom claims that their newest 40nm PHYs use less than 4W per port. Still, it will take a while before the 10GBase-T conquers the world, as this kind of state-of-the art technology needs some time to mature.
We decided to check out the some of the more mature CX4-based solutions as they are decently priced and require less power. For example, a dual-port CX4 card goes as low as 6W… that is 6W for the controller, two ports and the rest of the card. So a complete dual-port NIC needs considerably less than one of the early 10GBase-T ports. But back to our virtualized server: can 10Gbit Ethernet offer something that the current popular quad-port gigabit NICs can’t?
Adapting the network layers for virtualization
When lots of VMs are hitting the same NIC, quite a few performance problems may arise. First, one network intensive VM may completely fill up the transmit queues and block the access to the controller for some time. This will increase the network latency that the other VMs see. The hypervisor has to emulate a network switch that sorts and routes the different packets of the various active VMs. Such an emulated switch costs quite a bit of processor performance, and this emulation and other network calculations might all be running on one core. In that case, the performance of this one core might limit your network bandwidth and raise network latency. That is not all, as moving data around without being able to use DMA means that the CPU has to handle all memory move/copy actions too. In a nutshell, a NIC with one transmit/receive queue and a software emulated switch is not an ideal combination if you want to run lots of network intensive VMs: it will reduce the effective bandwidth, raise the NIC latency and increase the CPU load significantly.
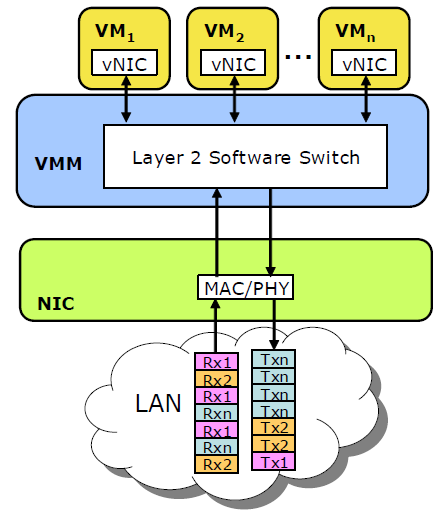
Several companies have solved this I/O bottleneck by making use of the multiple queues". Intel calls it VMDq; Neterion calls it IOV. A single NIC controller is equipped with different queues. Each receive queue can be assigned to a virtual NIC of your VM and mapped to the guest memory of your VM. Interrupts are load balanced across several cores, avoiding the problem that one CPU is completely overwhelmed by the interrupts of tens of VMs.
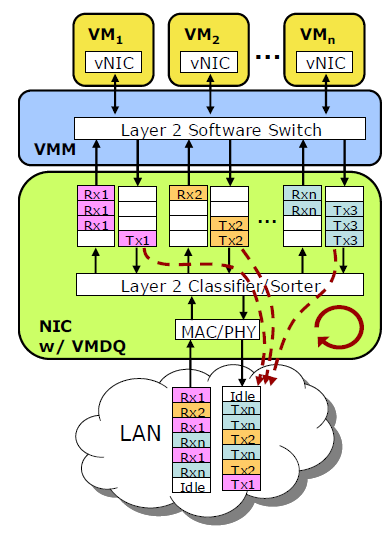
When packets arrive at the controller, the NIC’s Layer 2 classifier/sorter sorts the packets and places them (based on the virtual MAC addresses) in the queue assigned to a certain VM. Layer 2 routing is thus done in hardware and not in software anymore. The hypervisor looks in the right queue and then routes those packets towards the right VM. Packets that have to go out of your physical server are placed in the transmit queues of each VM. In the ideal situation, each VM has its own queue. Packets are sent to the physical wire in a round-robin fashion.
The hypervisor has to support this and your NIC vendor must of course have an “SR-IOV” capable driver for the hypervisor. VMware ESX 3.5 and 4.0 have support for VMDq and similar technologies, calling it “NetQueue”. Microsoft Windows 2008 R2 supports this too, under the name “VMQ”.








49 Comments
View All Comments
krazyderek - Monday, March 8, 2010 - link
Furthermore where do the upgrades stop? Dual NIC's are common on workstations but you can also get triple and quad built in, or add in cards. Where do you stop?Maybe i'm looking for an answer to a question that doesn't have a clear cut answer, it's just a balancing act, and you have to balance performance with home much you have to spend.
If you upgrade the server to remove it as a bottleneck, then your clients become the bottleneck, if you team up enough client NIC's then your server become's the bottleneck again, if you upgrade the server with PCIe solid state drive like the Fusion IO and several 10Gb connections then your clients and your switch start to become the bottleneck, and on and on....
Kjella - Tuesday, March 9, 2010 - link
If you use "IT" "upgrades" and "end" in the same post, well... it doesn't end. It ends the day megacorporations can run off a handful of servers, which is never because the requirements keep going up. Like for example your HDD bottleneck, well then let's install a SSD array that can run tens (hundreds?) of thousands of IOPS and several Gbit/s speeds and something else becomes the bottleneck. It's been this way for decades.has407 - Tuesday, March 9, 2010 - link
You stop when you have enough performance to meet your needs. How much is that? Depends on your needs. Where's the bottleneck? A bit of investigation will identify them.If you have a server serving a bunch of clients, and the server network performance is unacceptable, then increasing the number of 1Gbe ports on the server is likely your best choice if you have expansion capability; if not then port/slot consolidation using 10Gbe may be appropriate. However, if server performance is limited by other factors (e.g., CPU/disk), then that's where you should focus.
If you have clients hitting a server, and the client network performance is unacceptable (and the server performance is OK), then (in general) aggregating ports on the client won't get you much (if anything). In that case 10Gbe on the client may be appropriate. However, if client performance is limited by other factors (e.g., CPU/disk), then that's where you should focus.
Link aggregation works best when traffic is going to different sources/destinations, and is generally most useful on a server which is serving multiple clients (or between switches with a variety of end-point IP's).
4X 1Gbe links != 1x 4Gbe link. Link aggregation and load balancing across multiple links is typically based on source/destination IP. If they're the same, they'll follow the same link/path, and link aggregation won't buy you much because all of the packets from the same source/destination are following the same path--which means they go over the same link, which means that the speed is limited to that of the single fastest link. (Some implementations can also load balance based on source/destination port as well as IP, which may help in some situations.)
That means that no matter how many 1Gbe links you have aggregated on client or server, the end-to-end speed for any given source/destination end-to-end IP pair (and possibly port) will never exceed that of a single 1Gbe link. (While there are ways to get around that, it's generally more trouble than it's worth and can seriously hurt performance.)
krazyderek - Tuesday, March 9, 2010 - link
I thought this is why you had to use Link Aggregation and NIC teaming in combination, giving the client and server one IP each on multiple ethernet cords, so that when a client with 2xnic is doing say, sequential transfer from a server with 2x 3x or 4x then you could get 240MB/s throughput if the storage systems can handle it on either end, but when a 2x client connects to anther 1x client then you're limited by the slower of the two connections and thus only capable of 120MB/s max, which would open the door to still have 120MB/s combing from another client at the same time.Maybe it's all this SSD talk as of late, but i just want to see some of those options and bottlenecks tackled in real life and i just don't happen to have 5 or 10 SSD's kicking around to try it myself.
has407 - Wednesday, March 10, 2010 - link
Link Aggregation (LACP) == NIC teaming (c.f., 802.3ad/802.1AX). Assigning different IP's will not get you anything unless higher layers are aware and are capable (e.g., use multipath which can improve performance, but in my experience not a lot--and it comes with overhead).Reordering Ethernet frames or IP packets can carry a heavy penalty--more than it's worth in many (most?) cases, which is why packets sent from any endpoint pair will (sans higher-order intervention) follow the same path. Endpoint pairs are typically based on IP, although some switches also use the port numbers (i.e., path == hash of IPs in the simple case, path == hash of IPs+ports in more sophisticated case). Which is why you genrally won't see performance exceed the fastest *single physical link* between endpoints (regardless of how many links you've teamed/aggregated), and which is why a single fast link can be better than teamed/aggregated links.
E.g., team 4x 1Gbe links on both client and server. You generally won't see more than 1Gb from the client to the server for any given xfer or protocol, If you run multiple xfer's using differnt protocols (i.e., different ports) and you have a smart switch, you may see > 1Gb.
In short, if you have a client with 4x 1Gb teamed/aggregated NICs, you won't see >1Gb for any IP/port pair, and probably not for any IP pair (depending on the switch/NIC smarts and how you've done your port aggregation/teaming) on the client, switch and server. Which again is why a single faster link is generally better than teaming/aggregation.
There's a simple way for you to test it... fire up an xfer from a client with teamed NICs to a server with plenty of bandwidth. In most cases it will max out at the rate of the fastest single physical link on the client (or server). Fire up another xfer using the same protocol/port. In most cases the aggregate xfer will remain about the same (all packets are following the same path). If you see an increase, congratulations, your teaming is using both IP and port hashing to distribute traffic.
Lord 666 - Monday, March 8, 2010 - link
In the market for a new SAN for a server in preparation for a consolidation/virtualization/headquarters move, one of my RFP requirements was for 10gbe capabilities now. Some peers of mine have questioned this requirement stating there is enough bandwidth with etherchanneled 4gb nics and FC would be the better option if thats not enough.Thank you for doing this write up as it confirms that my hypothesis is correct and 10gbe will/is a valid requirement for the new gear from a very forward looking view.
It would be nice to see the same kit used in combination with SANS. With the constant churn of new gear, this will be very helpful.
has407 - Monday, March 8, 2010 - link
Agree. Anyone who suggests FC is the answer today is either running on inertia or trying to justify a legacy FC investment/infrastructure.Build on 10Gbe if at all possible; if you need FC in places, look at FCoE.
mino - Tuesday, March 9, 2010 - link
FC is good solution where iSCSI over Gbit is not enough but 10Gbps, along with all the teething troubles, is just not worth it.FC is reliable, 4Gb is no overpriced and has none of the issues of iSCSI.
It just works.
Granted, for heavily loaded situations, especially on blades, 10G is the way to go.
But for many medium loads, FC is often the simpler/cheaper option.
JohanAnandtech - Tuesday, March 9, 2010 - link
Which issues of iSCSI exactly? And FC is still $600 per port if I am not mistaken?Not to mention that you need to import a whole new kind of knowledge in your organisation, while iSCSI works with the UTP/Ethernet tech that every decent ITer knows.
mino - Tuesday, March 16, 2010 - link
The issues with latency, reliability, multipathing etc. etc.Basically the strongest point of iSCSI is the low up-front price and single-infrastructure mantra.
Optimal for small or scale-out. Not so much for mid projects.
"... while iSCSI works with the UTP/Ethernet tech that every decent ITer knows ..."
Sorry to break the news, but any serious IT shop has an in-house FC-storage experience going back a decade or more.
1Gbps is really not in a competition with FC. It is an order of magnuitude below in latency and protocol overhead (read low IOps).
Whe the fun starts is 10G vs FC and serious 10G infrastructure is actually more expensive per port than FC.
When iSCSI over 10G shines is in port consolidation oportunity.
Not in bandwith, not in latency, not in price/port.