Qualcomm Snapdragon S4 (Krait) Performance Preview - 1.5 GHz MSM8960 MDP and Adreno 225 Benchmarks
by Brian Klug & Anand Lal Shimpi on February 21, 2012 3:01 AM EST- Posted in
- Smartphones
- Snapdragon
- Qualcomm
- Adreno
- Krait
- Mobile
We won't go too deep into Krait's CPU architecture, because we've already done so in an earlier piece. What we can provide however is a quick recap. Architecturally Krait isn't a design of tradeoffs, rather it's a significant step forward along almost all vectors. Each core can fetch, decode and execute more instructions in parallel than its predecessor (Scorpion, Snapdragon S1/S2/S3).
| Qualcomm Architecture Comparison | ||||
| Scorpion | Krait | |||
| Pipeline Depth | 10 stages | 11 stages | ||
| Decode | 2-wide | 3-wide | ||
| Issue Width | 3-wide? | 4-wide | ||
| Execution Ports | 3 | 7 | ||
| L2 Cache (dual-core) | 512KB | 1MB | ||
| Core Configurations | 1, 2 | 1, 2, 4 | ||
Even if you're not comparing to Qualcomm's previous architecture, Krait maintains the same low level advantage over any other ARM Cortex A9 based design (NVIDIA Tegra 2/3, TI OMAP 4, Apple A5). Clock speeds are up with only a small increase in pipeline depth. The combination of these two factors alone should result in significant performance improvements for even single threaded applications. If you want to abstract by one more level: Krait will be faster regardless of application, regardless of usage model. You're looking at a generational gap in architecture here, not simply a clock bump.
| Architecture Comparison | ||||||||
| ARM11 | ARM Cortex A8 | ARM Cortex A9 | Qualcomm Scorpion | Qualcomm Krait | ||||
| Decode | single-issue | 2-wide | 2-wide | 2-wide | 3-wide | |||
| Pipeline Depth | 8 stages | 13 stages | 8 stages | 10 stages | 11 stages | |||
| Out of Order Execution | N | N | Y | Partial | Y | |||
| FPU | VFP11 (pipelined) | VFPv3 (not-pipelined) | Optional VFPv3 (pipelined) | VFPv3 (pipelined) | VFPv4 (pipelined) | |||
| NEON | N/A | Y (64-bit wide) | Optional MPE (64-bit wide) | Y (128-bit wide) | Y (128-bit wide) | |||
| Process Technology | 90nm | 65nm/45nm | 40nm | 40nm | 28nm | |||
| Typical Clock Speeds | 412MHz | 600MHz/1GHz | 1.2GHz | 1GHz | 1.5GHz | |||
The memory interface of the chip has been improved tremendously. At a high level, the MSM8960 is Qualcomm's first SoC to feature PoP support for two LPDDR2 memory channels. We suspect there are lower level improvements to the memory interface as well however we don't have more details from Qualcomm, not to mention the current state of memory latency/bandwidth testing on Android is pretty abysmal.
Quantifying the Krait performance advantage requires a mixture of synthetic and application level tests. We'll start with Linpack, a Java port of the classic memory bandwidth/FPU test:
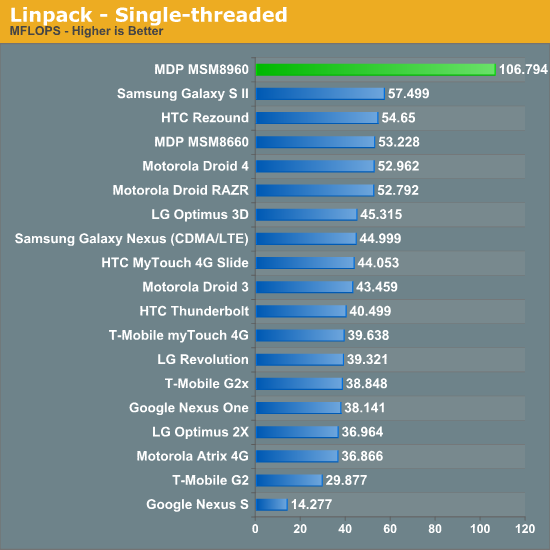
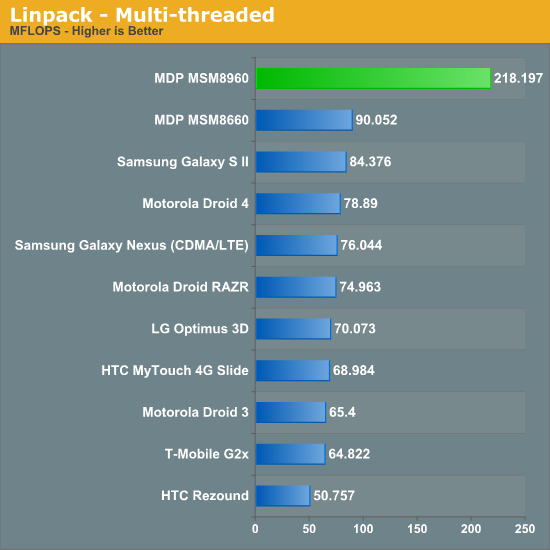
Occasionally we'll see performance numbers that just make us laugh at their absurdity. Krait's Linpack performance is no exception. The performance advantage here is insane. The MSM8960 is able to deliver more than twice the performance of any currently shipping SoC. The gains are likely due in no small part to improvements in Krait's cache/memory controller. Krait can also issue multi-issue FP instructions, A9 class architectures can apparenty only dual-issue integer instructions.
Moving on we have our standard JavaScript benchmarks: Sunspider and Browsermark. Both of these tests show significant performance improvements, although understandably not by the margins we saw above in Linpack:


Krait and the MSM8960 are 20 - 35% faster than the dual-core Cortex A9s used in Samsung's Galaxy Nexus. For a look at how overall web page loading is impacted we loaded AnandTech.com three times and averaged the results. We presented results with the browser cache cleared after each run as well as results after all assets were cached:
| AnandTech.com Page Loading Comparison (Stock ICS Browser) | ||||
| Browser Cache Cleared | Cache In Use | |||
| Qualcomm MDP MSM8960 (Krait) | 5.5 seconds | 3.0 seconds | ||
| Samsung Galaxy Nexus (ARM Cortex A9) | 5.8 seconds | 4.4 seconds | ||
There's hardly any advantage when you're network bound, which is to be expected. However whenever the device can pull assets from a local cache (something that is quite common as images, CSS and even many page elements remain static between loads) the advantage grows considerably. Here we're seeing a 46% advantage from Krait over the Cortex A9 in the Galaxy Nexus.
We turn to Qualcomm's own Vellamo as a system/CPU/browser performance test:
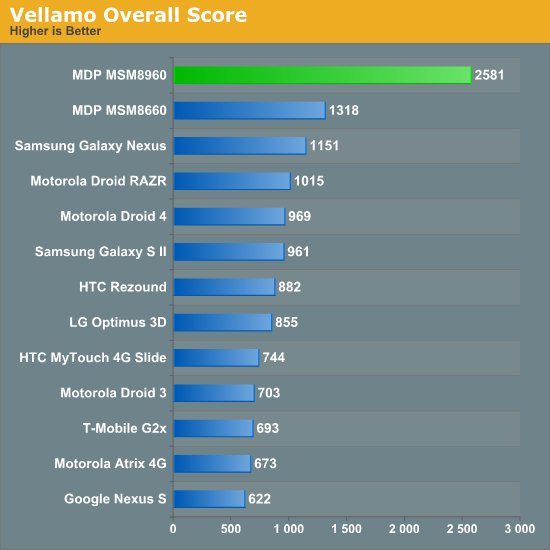
Again, we're showing a huge performance advantage here thanks to Krait. Seeing as how Vellamo is a Qualcomm benchmark don't get too attached to the advantage here, but it does echo some of what we've seen earlier.
Finally we have Rightware's Basemark OS 1.1 RC which is fast becomming an impressively polished system benchmark, one which will hopefully eventually take the place of the likes of Quadrant.
| Basemark OS - System | |||
| HTC Rezound | Galaxy Nexus | MDP MSM8960 | |
| System Overall Score | 658 | 538 | 907 |
| Simple Java 1 | 298 loops/s | 210 loops/s | 375 loops/s |
| Simple Java 2 | 7.28 loops/s | 8.61 loops/s | 10.8 loops/s |
| SMP Test | 35.3 loops/s | 49.2 loops/s | 64.4 loops/s |
| 100K File (eMMC->SD) | 6.49 mB/s | 9.52 mB/s | 8.64 mB/s |
| 100K File (SD->eMMC) | 33.0 mB/s | 17.8 mB/s | 39.8 mB/s |
| 100K File (eMMC->eMMC) | 37.8 mB/s | 34.5 mB/s | 48.9 mB/s |
| 100K File (SD->SD) | 8.47 mB/s | 8.30 mB/s | 12.7 mB/s |
| Database Operation | 10.0 ops/s | 5.73 ops/s | 19.4 ops/s |
| Zip Compression | 0.509 s | 0.848 s | 0.561 s |
| Zip Decompression | 0.097 s | 0.206 s | 0.073 s |
On the CPU centric tests Basemark OS is showing anywhere from a 20% - 80% increase in performance over the 1.5 GHz APQ8060 based HTC Rezound. IO performance is also tangibly improved although that could be a function of NAND performance rather than the SoC specifically.
These results as a whole simply quantify what we've felt during our use of the MSM8960 MDP: this is the absolute smoothest we've ever seen Ice Cream Sandwich run.








86 Comments
View All Comments
ssj4Gogeta - Tuesday, February 21, 2012 - link
I think he meant lower compared to the 720p GLBenchmark where the A5 wins.zanon - Tuesday, February 21, 2012 - link
I agree the wording is a bit awkward there since they are both driving identical numbers of pixels. If he meant to compare it to the earlier 720p results it'd probably be better to make that explicit.jjj - Tuesday, February 21, 2012 - link
Looks like it's faster than Tegra 3 and with single threaded perf certainly much better the only remaining big question is power consumption.Malih - Tuesday, February 21, 2012 - link
I've been my old android device that comes with Android 1.6, and Cyanogenmod-ded to Gingerbread (it's not so responsive when running more than one app), because I need the new version of the Gmail app.Malih - Tuesday, February 21, 2012 - link
correction: I've been *using* my old...In short: it looks like I'll be waiting in line for a smartphone with this SoC
Zingam - Tuesday, February 21, 2012 - link
I haven't been impressed by a CPU/GPU for years but this thing looks amazing! If they manage to go on like that we'll soon have a true ARM desktop experience.Great job! I wish now they support the latest DirectX/OpenGL/OpenCL/OpenVG etc. stuff and we'll have it!!! It is unimaginable what ARM based SoCs would deliver when the time for 14nm comes.
Torrijos - Tuesday, February 21, 2012 - link
Since both devices actually render the same amount of pixel but with different aspect ratio, would it be possible, that the performance hit seen for the iPhone 4S, is the result of graphics rendered in a standard aspect ratio (16:9 or something else) then having to be transformed to fit the particular screen?cosminmcm - Tuesday, February 21, 2012 - link
Maybe it's because at the lower resolution the faster CPU on the Krait (newer architecture with higher clocks) matters more than the faster GPU on the A5. When the resolution grows, the difference between the GPU becomes more apparent.LetsGo - Tuesday, February 21, 2012 - link
What difference?http://blogs.unity3d.com/wp-content/uploads/2011/0...
metafor - Tuesday, February 21, 2012 - link
Considering Apple controls the entire software stack and the A5 silicon, it'd be pretty stupid of them to do that. And if you look at how performance scales between the iPad (4:3) and iPhone (16:9), there's no slowdown due to aspect ratio.