Intel's Xeon E5-2600 V2: 12-core Ivy Bridge EP for Servers
by Johan De Gelas on September 17, 2013 12:00 AM ESTWhat Has Improved?
Ivy Bridge is what Intel calls a tick+, a transition to the latest 22nm process technology (the famous P1270 process) with minor architectural optimizations compared to predecessor Sandy Bridge (described in detail by Anand here):
- Divider is twice as fast
- MOVs take no execution slots
- Improved prefetchers
- Improved shift/rotate and split/Load
- Buffers are dynamically allocated to threads (not statically split in two parts for each thread)
Given the changes, we should not expect a major jump in single-threaded performance. Anand made a very interesting Intel CPU generational comparison in his Haswell review, showing the IPC improvements of the Ivy Bridge core are very modest. Clock for clock, the Ivy Bridge architecture performed:
- 5% better in 7-zip (single-threaded test, integer, low IPC)
- 8% better in Cinebench (single-threaded test, mostly FP, high IPC)
- 6% better in compiling (multi-threaded, mostly integer, high IPC)
So the Ivy Bridge core improvements are pretty small, but they are measureable over very different kinds of workloads.
The core architecture improvements might be very modest, but that does not mean that the new Xeon E5-2600 V2 series will show insignificant improvements over the previous Xeon E5-2600. The largest improvement comes of course from the P1270 process: 22nm tri-gate (instead of 32nm planar) transistors. Discussing the actual quality of Intel process technology is beyond our expertise, but the results are tangible:
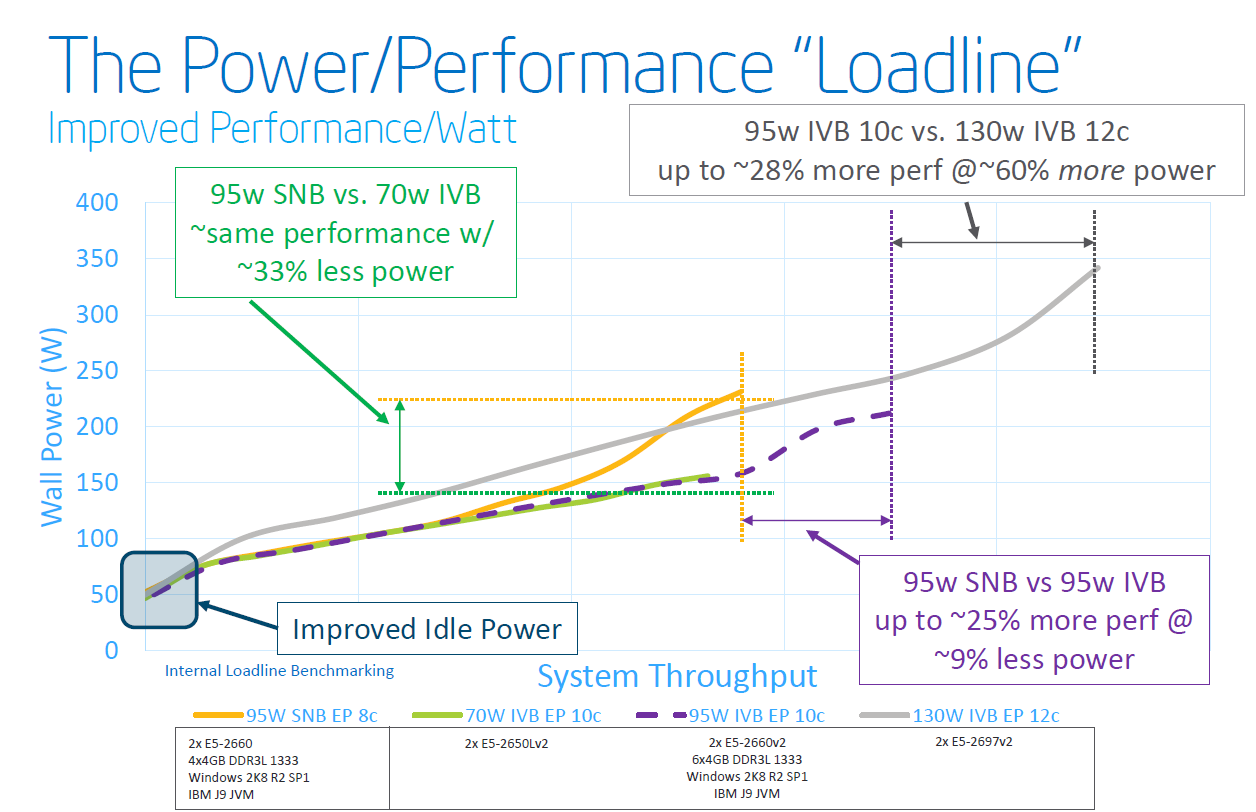
Focus on the purple text: within the same power envelope, the Ivy Bridge Xeon is capable of delivering 25% more performance while still consuming less power. In other words, the P1270 process allowed Intel to increase the number of cores and/or clock speed significantly. This can be easily demonstrated by looking at the high-end cores. An octal-core Xeon E5-2680 came with a TDP of 130W and ran at 2.7GHz. The E5-2697 runs at the same clock speed and has the same TDP label, but comes with four extra cores.
Virtualization Improvements
Each new generation of Xeon has reduced the amount of cycles required for a VMexit or a VMentry, but another way to reduce hardware virtualization overhead is to avoid VMexits all together. One of the major causes of VMexits (and thus also VMentries) are interrupts. With external interrupts, the guest OS has to check which interrupt has the priority and it does this by checking the APIC Task Priority Register (TPR). Intel already introduced an optimization for external interrupts in the Xeon 7400 series (back in 2008) with the Intel VT FlexPriority. By making sure a virtual copy of the APIC TPR exists, the guest OS is capable of reading out that register without a VMexit to the hypervisor.
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparantly, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
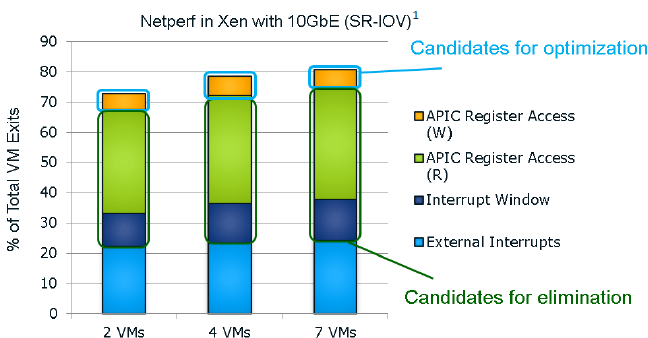
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
Related to this, Sandy Bridge introduced support for large pages in VT-d (faster DMA for I/O, chipset translates virtual addresses to physical), but in fact still fractioned large pages into 4KB pages. Ivy Bridge fully supports large pages in VT-d.
Only Xen 4.3 (July 2013) and KVM 1.4 (Spring 2013) support these new features. Both VMware and Microsoft are working on it, but the latest documents about vSphere 5.5 do not mention anything about APICv. AMD is working on an alternative called Advanced Virtual Interrupt Controller (AVIC). We found AVIC inside the AMD64 programmer's manual at page 504, but it is not clear which Opterons will support it (Warsaw?).








70 Comments
View All Comments
mczak - Tuesday, September 17, 2013 - link
Yes that's surprising indeed. I wonder how large the difference in die size is (though the reason for two dies might have more to do with power draw).zepi - Tuesday, September 17, 2013 - link
How about adding turbo frequencies to sku-comparison tables? That'd make comparison of the sku's a bit easier as that is sometimes more repsentative figure depending on the load that these babies are run.JarredWalton - Tuesday, September 17, 2013 - link
I added Turbo speeds to all SKUs as well as linking the product names to the various detail pages at AMD/Intel. Hope that helps! (And there were a few clock speed errors before that are now corrected.)zepi - Wednesday, September 18, 2013 - link
Appreciated!zepi - Wednesday, September 18, 2013 - link
For most server buyers things are not this simple, but for armchair sysadmins this might do:http://cornflake.softcon.fi/export/ivyexeon.png
ShieTar - Tuesday, September 17, 2013 - link
"Once we run up to 48 threads, the new Xeon can outperform its predecessor by a wide margin of ~35%. It is interesting to compare this with the Core i7-4960x results , which is the same die as the "budget" Xeon E5s (15MB L3 cache dies). The six-core chip at 3.6GHz scores 12.08."What I find most interesting here is that the Xeon manages to show a factor 23 between multi-threaded and single-threaded performance, a very good scaling for a 24-thread CPU. The 4960X only manages a factor of 7 with its 12 threads. So it is not merely a question of "cores over clock speed", but rather hyperthreading seems to not work very well on the consumer CPUs in the case of Cinebench. The same seems to be true for the Sandy Bridge and Haswell models as well.
Do you know why this is? Is hyperthreading implemented differently for the Xeons? Or is it caused by the different OS used (Windows 2008 vs Windows 7/8)?
JlHADJOE - Tuesday, September 17, 2013 - link
^ That's very interesting. Made me look over the Xeon results and yes, they do appear to be getting close to a 100% increase in performance for each thread added.psyq321 - Tuesday, September 17, 2013 - link
Hyperthreading is the same.However, HCC version of IvyTown has two separate memory controllers, more features enabled (direct cache access, different prefetchers etc.). So it might scale better.
I am achieving 1.41x speed-up with dual Xeon 2697 v2 setup, compared to my old dual Xeon 2687W setup. This is so close to the "ideal" 1.5x scaling that it is pretty amazing. And, 2687w was running on a slightly higher clock in all-core turbo.
So, I must say I am very happy with the IvyTown upgrade.
garadante - Tuesday, September 17, 2013 - link
It's not 24 threads, it's 48 threads for that scaling. 2x physical CPUs with 12 cores each, for 24 physical cores and a total of 48 logical cores.Kevin G - Tuesday, September 17, 2013 - link
Actually if you run the numbers, the scaling factor from 1 to 48 threads is actually 21.9. I'm curious what the result would have been with Hyperthreading disabled as that can actually decrease performance in some instances.