Intel's Xeon E5-2600 V2: 12-core Ivy Bridge EP for Servers
by Johan De Gelas on September 17, 2013 12:00 AM ESTWhat Has Improved?
Ivy Bridge is what Intel calls a tick+, a transition to the latest 22nm process technology (the famous P1270 process) with minor architectural optimizations compared to predecessor Sandy Bridge (described in detail by Anand here):
- Divider is twice as fast
- MOVs take no execution slots
- Improved prefetchers
- Improved shift/rotate and split/Load
- Buffers are dynamically allocated to threads (not statically split in two parts for each thread)
Given the changes, we should not expect a major jump in single-threaded performance. Anand made a very interesting Intel CPU generational comparison in his Haswell review, showing the IPC improvements of the Ivy Bridge core are very modest. Clock for clock, the Ivy Bridge architecture performed:
- 5% better in 7-zip (single-threaded test, integer, low IPC)
- 8% better in Cinebench (single-threaded test, mostly FP, high IPC)
- 6% better in compiling (multi-threaded, mostly integer, high IPC)
So the Ivy Bridge core improvements are pretty small, but they are measureable over very different kinds of workloads.
The core architecture improvements might be very modest, but that does not mean that the new Xeon E5-2600 V2 series will show insignificant improvements over the previous Xeon E5-2600. The largest improvement comes of course from the P1270 process: 22nm tri-gate (instead of 32nm planar) transistors. Discussing the actual quality of Intel process technology is beyond our expertise, but the results are tangible:
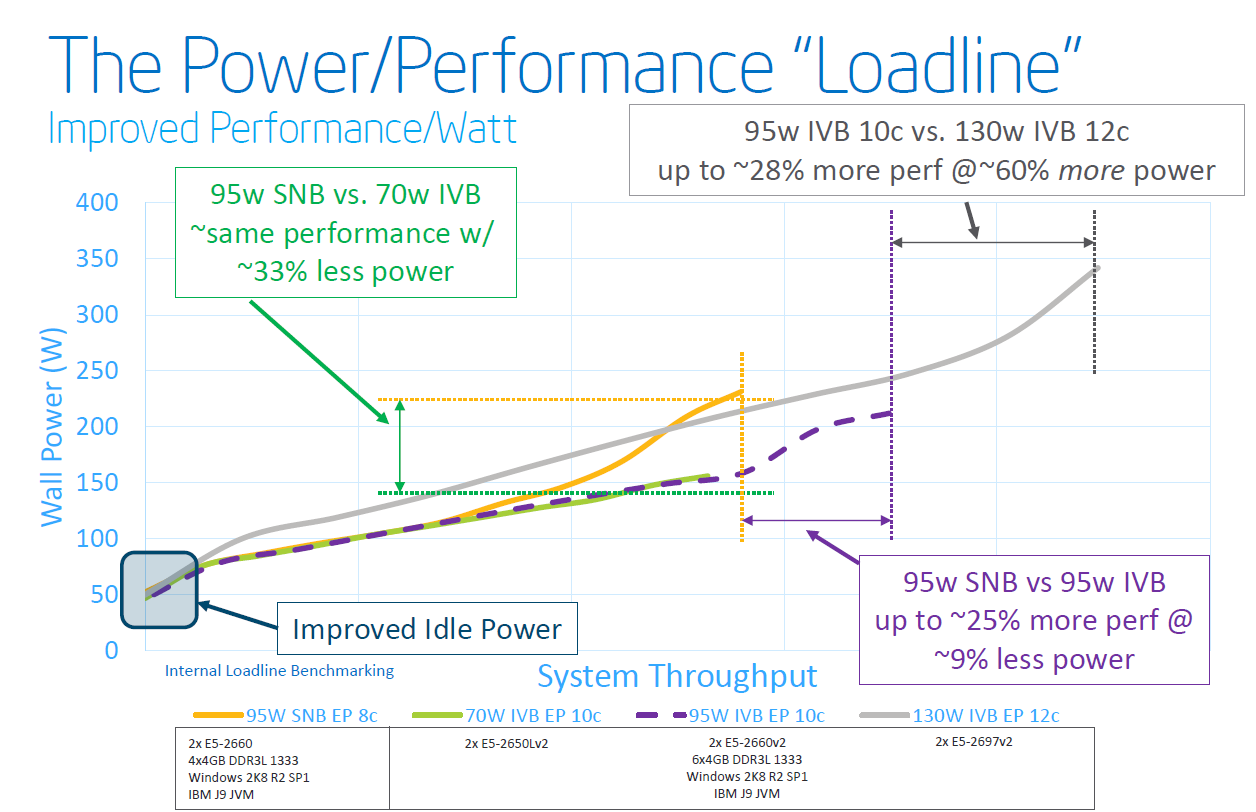
Focus on the purple text: within the same power envelope, the Ivy Bridge Xeon is capable of delivering 25% more performance while still consuming less power. In other words, the P1270 process allowed Intel to increase the number of cores and/or clock speed significantly. This can be easily demonstrated by looking at the high-end cores. An octal-core Xeon E5-2680 came with a TDP of 130W and ran at 2.7GHz. The E5-2697 runs at the same clock speed and has the same TDP label, but comes with four extra cores.
Virtualization Improvements
Each new generation of Xeon has reduced the amount of cycles required for a VMexit or a VMentry, but another way to reduce hardware virtualization overhead is to avoid VMexits all together. One of the major causes of VMexits (and thus also VMentries) are interrupts. With external interrupts, the guest OS has to check which interrupt has the priority and it does this by checking the APIC Task Priority Register (TPR). Intel already introduced an optimization for external interrupts in the Xeon 7400 series (back in 2008) with the Intel VT FlexPriority. By making sure a virtual copy of the APIC TPR exists, the guest OS is capable of reading out that register without a VMexit to the hypervisor.
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparantly, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
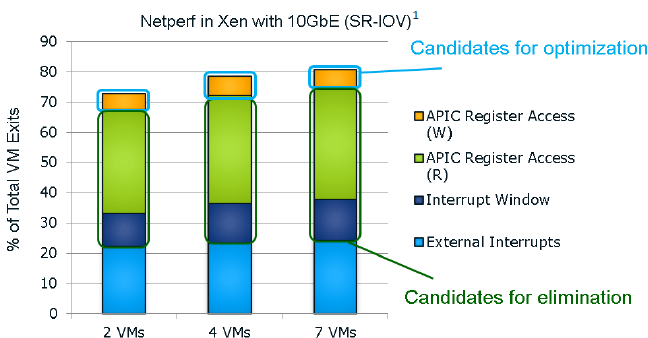
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
Related to this, Sandy Bridge introduced support for large pages in VT-d (faster DMA for I/O, chipset translates virtual addresses to physical), but in fact still fractioned large pages into 4KB pages. Ivy Bridge fully supports large pages in VT-d.
Only Xen 4.3 (July 2013) and KVM 1.4 (Spring 2013) support these new features. Both VMware and Microsoft are working on it, but the latest documents about vSphere 5.5 do not mention anything about APICv. AMD is working on an alternative called Advanced Virtual Interrupt Controller (AVIC). We found AVIC inside the AMD64 programmer's manual at page 504, but it is not clear which Opterons will support it (Warsaw?).








70 Comments
View All Comments
psyq321 - Tuesday, September 17, 2013 - link
Yep, EP-46xx v2 will use the same C1 stepping (for HCC SKUs) for production parts as 2P Xeons, but there will be some features enabled in microcode which did not make it in the 26xx SKUs.EX is already on D1 stepping for QS, as the validation cycle for EX is more strict due to more RAS features etc.
Casper42 - Tuesday, September 17, 2013 - link
So I work for HP and your comments about 4x1P instead of 2x2P make me wonder if you have been sneaking around our ProLiant development lab in Houston.I was there 6 weeks ago and a decent sized cluster of 1P nodes was being assembled on an as yet unannounced HP platform. I was told the early/beta customer it was for had done some testing and found for their particular HPC app, they were in fact getting measurably better overall performance.
The interesting thing about this design was they put 2 x 1P nodes on a single PCB (Motherboard) in order to more easily adapt the 1P nodes to a system largely designed with 2P space requirements in mind.
Pretty sure the chips were Haswell based as well but can't recall for sure.
André - Tuesday, September 17, 2013 - link
Would be nice to see benchmarks for OS X, considering this thing is going inside the new Mac Pro.Final Cut X, After Effects, Premiere Pro, Photoshop, Lightroom, DaVinci Resolve etc.
I believe the 2660v2 hits the sweet spot with it's 10 cores.
DanNeely - Tuesday, September 17, 2013 - link
That'd require Apple giving Anandtech a new Mac Pro to run benchmarks on...Kevin G - Tuesday, September 17, 2013 - link
Now that Intel has officially launched the new Xeons, the new Mac Pro can't be far behind.wallysb01 - Tuesday, September 17, 2013 - link
Well, you could run the CPU benchmarks just fine. But not the GPU ones.Simon G - Tuesday, September 17, 2013 - link
Typo in Conclusion section . . . " Thta's no small feat, . . ."garadante - Tuesday, September 17, 2013 - link
There's a minor error on the Cinebench single-threaded graph. It has the clock speed for the E5-2697 v2 as 2.9 instead of 2.7, as it should be. Which is semi confusing on that graph as it explains the lower single-threaded performance from the E5-2690.SanX - Tuesday, September 17, 2013 - link
This forum has most obsolete comments design of pre-Neanderthals times, no Edit, no Delete, no look at previous user comments. Effin shameMrSpadge - Tuesday, September 17, 2013 - link
You mixed up forum and article comments.