Launching the #CPUOverload Project: Testing Every x86 Desktop Processor since 2010
by Dr. Ian Cutress on July 20, 2020 1:30 PM ESTAutomation
For anyone that has ever had to do boring, repetitive tasks, there is always the wish that it could be done without any interaction at all. For a number of professional applications, automation can be a primary requirement - the ability to press a button and let something go, with consistency every time, removes headaches and can lead to scaling out the process.
When it comes to benchmarking, having an automated test suite enables several benefits. Tests can have consistent delays between each test to provide the same environment for temperature and turbo ramps, it should arrange the cache and standardize cache defragmentation, and it lends itself to repeated consistent results. Bonus points are then awarded if the testing can then be scaled out to multiple systems at once. Sitting at a system with irregular jumps in testing can add in more degrees of freedom on things that might not be consistent and effect the results. Plus it becomes incredibly dull, incredibly fast. I mean OEM product manufacturing line dull. To all my fellow reviewers out there, I know the pain when you have several hundred hours of gameplay on something like Far Cry 5, but it’s all just benchmarking.
This is where I point to the well-known graph about automation (original source unknown):
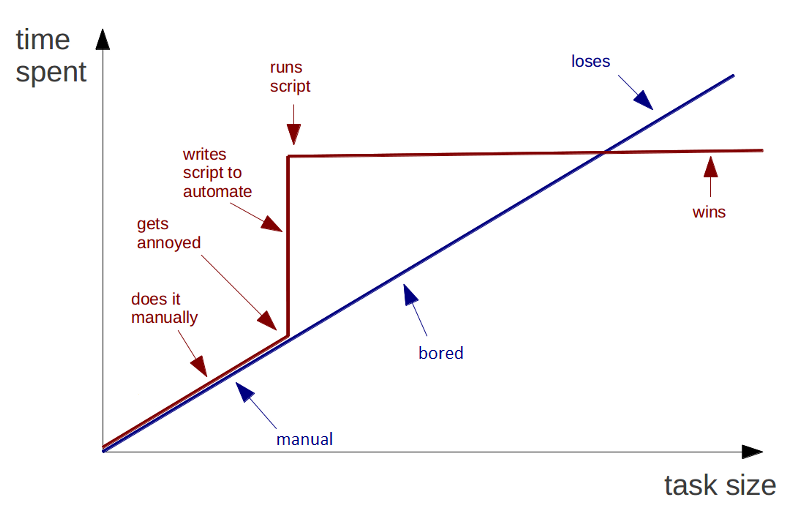
For small tasks or projects, sometimes manually doing the work is quicker. If it takes 5 minutes to do the task manually, but then 8 hours to write the script which saves 5 seconds, the script has to be run 5760 times for the payoff. If the script is run 50 times a day, then the payoff will be in 115 days. This ignores scale out, if the script allows multiple systems to run concurrently, but for a lot of tasks can make it a no brainer to put the effort in. Otherwise, 3 years later, it becomes ultimately depressing when running CineBench for the 80000th time. (Insert stories from TheDailyWTF about how in a company a boss does not want automation because it might kill their job). Insert obligatory XKCD.
When I first started at AnandTech, testing motherboards, I did not run anything automated. Going through a basic motherboard testing suite manually took three days, because when testing you have to be alert and present every time a test finished to run the next one (and if the mind wanders, that 2-minute test becomes 15 minutes until you realize it's done). For our 2015 CPU Benchmark suite, a basic script that was written performed about 20 tests and lasted around 4 hours. It looked like spaghetti code, and very quickly became annoying to manage and update, especially when a benchmark decided it wasn't going to work/needed to be bypassed – there was no easy way to add benchmarks either. On top of this, benchmark installing was manual. Insert more XKCD. Thank you XKCD.

The new scripts for our Windows 10 testing are larger, modular, and more involved. The goal was essentially to automate everything down to what was feasibly possible, within my knowledge (or didn't require much learning), and required no user interaction. Over the course of two months, while testing which benchmarks were usable and applicable, two major scripts were written: CPU Tests and CPU Gaming Tests.
How to Automate: Batch Files, Powershell, and AHK
There are many ways to automate in a system. Ganesh, for example, uses PowerShell almost exclusively to call benchmarks from the command line. To say that PowerShell is a glorified command prompt doesn't do it justice, but Ganesh ensures that his workloads for mini-PC testing can only ever run from the command line, and the results can be parsed therein.
I'm not as au fait with PowerShell (if I had time for a crash course, it'd be on my to-do list), so I use a combination of batch files and a tool called AutoHotKey (AHK for short). AHK is a simple enough scripting language which can run programs, call command line functions, call PowerShell scripts, emulate mouse movements, emulate clicks and keyboard presses, and perform internal math, with subroutine support. It is like a poor man's C++, with an alarming number of foibles, such as poor type definition and zero type checking, but it can work if you treat it right.
For each benchmark I tested for suitability, either a fixed benchmark like Cinebench or a custom workload such as WinRAR or Blender, I tried to get the test to run from a simple batch file command line and manipulate the output. For Cinebench 15, the output is part of the stderr, and for Photoscan it outputs a results file due to the python script it requires that Agisoft provided (and I've edited). For WinRAR it is a timing function wrapper around a command line call pointing at the workload, and for Civilization 6 it's a simple flag after adjusting the settings file. For benchmarks like Gears Tactics, or Cinebench R10, there is no command line option and we have to turn to AHK to simulate keyboard presses.
So with each benchmark profiled, the individual tests are written as separate functions in AHK with three stages: preparation/installation, execution, and result parsing.
Preparation involves ensuring that the benchmark can be run in its current state, installing it if it isn’t, and deleting any previous temporary results file (if present) to ensure the directory structure is valid where needed. With the right preparation, running each test in the same manner makes the result as consistent as possible. Parsing the output into something suitable usually means flicking through an output file and doing the appropriate regular expression functions to pull out the required value. Some tests automatically allow for repeated results (Corona or 3DPMv2), whereas others need multiple runs specified (WinRAR) and those results can be put into an array and averaged or geomeaned using AHK. A final function is written to take the results and ply them into a custom results directory.
Outside of the testing functions is a general preparation element to the script. For our testing we have four main modes: the full list of tests, a short list of tests (determined in the script), running a single test, and an option to continue from a certain point of a full test run (in case one benchmark needed attention and errored out the process, such as a web benchmark when the server host fails). The initialization of one of our scripts asks which benchmarks suite is required, and detects the CPU/GPU present in the system, before offering a default location to save the results based on the CPU/GPU combo. By having the results location determined when the script is started, we can move results to the directory as each test finishes, and the results are parsed into an easy to read format for a mental check before they go into the database. For ease of use, I have a results location on a NAS, and so as the script uploads benchmark results to it, I can start looking at the results uploaded to the NAS as the other benchmarks are running. Useful when running to a deadline! We also do additional checks on the state of Spectre and Meltdown fixes in the OS, to ensure consistency.
Sanity Checks of Results and Running Order
Mental checks of results become important - being able to spot an outlier, or identifying when a result seems abnormal. For example, through the initial testing, I noticed that one of the results in one of our web tests (scoring ~100ms) was staying in the clipboard for the next web test (scoring 700ms). This gave a much lower average for the second test - and this only happened on fast CPUs. Similarly with game tests, over the benchmark being repeated multiple times, sometimes a result (for whatever reason) might be 10% down on all the others. So either automatic detection of outliers needs to be in place (doesn't work if two results out of four repeats are bad), or a manual mental check needs to take place. There are a few things that automation can’t replace easily, such as experience. This is where for some tests an average might be representative, or a median might be more appropriate.
Also useful to note is determining the benchmark running order. Experience with our previous automation has shown that the shortest tests should run first, in order to populate our results directory on the NAS quicker, and the longer tests should be near the end but not right at the end. The tests that more frequently cause unpredictable errors (e.g. DLL support on a new platform causing a system to hang, or a benchmark that is reliant on online license servers which could be down for maintenance) are put in last, so an overnight run will go through as many tests as possible first before tackling potential breaks in the testing.
GPU Tests and Steam
The methods listed above work for our CPU and CPU Gaming tests. The CPU Gaming tests have an additional element, given that we are using games from Steam, and we are using only one log-in account for multiple systems under test at once. For the most part, if the game title likes to run nice offline, the test can be run offline. Unfortunately there are some games where the benchmark script will run 95% smoother (GTA, RDR2) when the user is logged in, due to online DRM checks.
For this, the script I’ve written runs a test and lock mechanism when trying to log in to Steam, and only tries to run the online tests if the account is not already signed in elsewhere. If the account is already signed in on a different system, the first system will instead automatically run one of the offline tests and come back after one test to see of online is available. If not, it will run another of the other offline tests, check again and so on, until there are no more offline tests to run, where it will sit and wait and probe every 120 seconds for access to Steam. For the machine that is online, it will run both sets of the online tests back-to-back, and then go back offline to run the rest of the offline tests, freeing the lock for any other machine that needs it. Some of this uses Steam's APIs, probing how Steam’s login mechanism works, and undocumented features.








110 Comments
View All Comments
DiHydro - Monday, July 20, 2020 - link
This is epic. Thank you for doing this.DiHydro - Monday, July 20, 2020 - link
To add a note: I think the ~$300 CPU year-over-year performance would be an interesting metric to see. That price point seems to be pretty popular for enthusiasts, and seeing back 5-6 years how that performance has increased per dollar would be neat.bldr - Monday, July 20, 2020 - link
Agree!close - Monday, July 20, 2020 - link
It will be especially interesting to see those CPUs (the popular mainstream ones) tested now and compared to the numbers they got originally to see how much they lost with all the recent mitigations.close - Tuesday, July 21, 2020 - link
Oh, because I forgot previously, congratulations and good luck with the endeavor! I got exhausted only by reading about the work you're going to have to doFozzie - Monday, July 20, 2020 - link
Except keep in mind that adjusted for inflation $200 in the year 2000 is worth over $300 now.You'd either be making a chart of the increased value over time just due to inflation or in fact the every increasing value at the $300 price point due to the reduced value of the Dollar on top of whatever performance gains occurred.
biosstar - Friday, July 24, 2020 - link
You could also use the value of a dollar in a certain year (let's say 2020) and compare the processors in the inflation adjusted equal categories.PeterCollier - Monday, July 20, 2020 - link
What's the point of this Geekbench/Userbenchmark knockoff? I've never used AT's Bench tool. Especially not for smartphones, since the Bench tool is about 5 years out of date.BushLin - Monday, July 20, 2020 - link
A controlled environment across all tests is reason enough. Even if I don't agree with AT policy on what speed they allow RAM to operate, it is a fair comparison.Byte - Monday, July 20, 2020 - link
RAM is a really important topic. I think at this point in time, we can reasonable put almost maxed out ram for every platform. Like DDR3 can run at 2133, DDR4 we can run it at 3200 as prices are so close.It is like rating sports cars but all have Goodride tires on them.
A dodge viper was a widowmaker when it came out. Today with a good set of summers like PS4S or PZero, you will have a hard time slipping even if you tried.