Arm Unveils 2024 CPU Core Designs, Cortex X925, A725 and A520: Arm v9.2 Redefined For 3nm
by Gavin Bonshor on May 29, 2024 11:00 AM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex
- 3nm
- Armv9.2
- Cortex-A520
- Cortex X925
- Cortex A725
Closing Remarks: Pushing Forward on 3 nm For 2024
Having attended Arm's Client Technology Day, my initial impressions were that Arm has opted to refine and hone its IP for 2024 instead of completely redefining and making groundbreaking changes. Following on from last year's introduction of the Armv9.2 family of cores, Arm has made some notable changes within the architecture of the latest Cortex series for 2024, with a clear and intended switch to the more advanced 3 nm process node, both with Samsung and TSMC 3 nm as the basis of client-based CSS for the 2024 platform.
The Cortex-X925, Cortex-A725, and Cortex-A520 cores have been optimized for the 3 nm process, delivering significantly touted performance and power efficiency improvements. The Cortex-X925, with its enhanced 10-wide decode and dispatch width and higher clock speeds reaching up to 3.8 GHz, looks to set a new standard for single-threaded IPC performance. Arm's updated v9.2 platform looks ideal for high-performance applications, including AI workloads and high-end gaming, both in the mobile space and with Microsoft's Windows on Arm ecosystem.
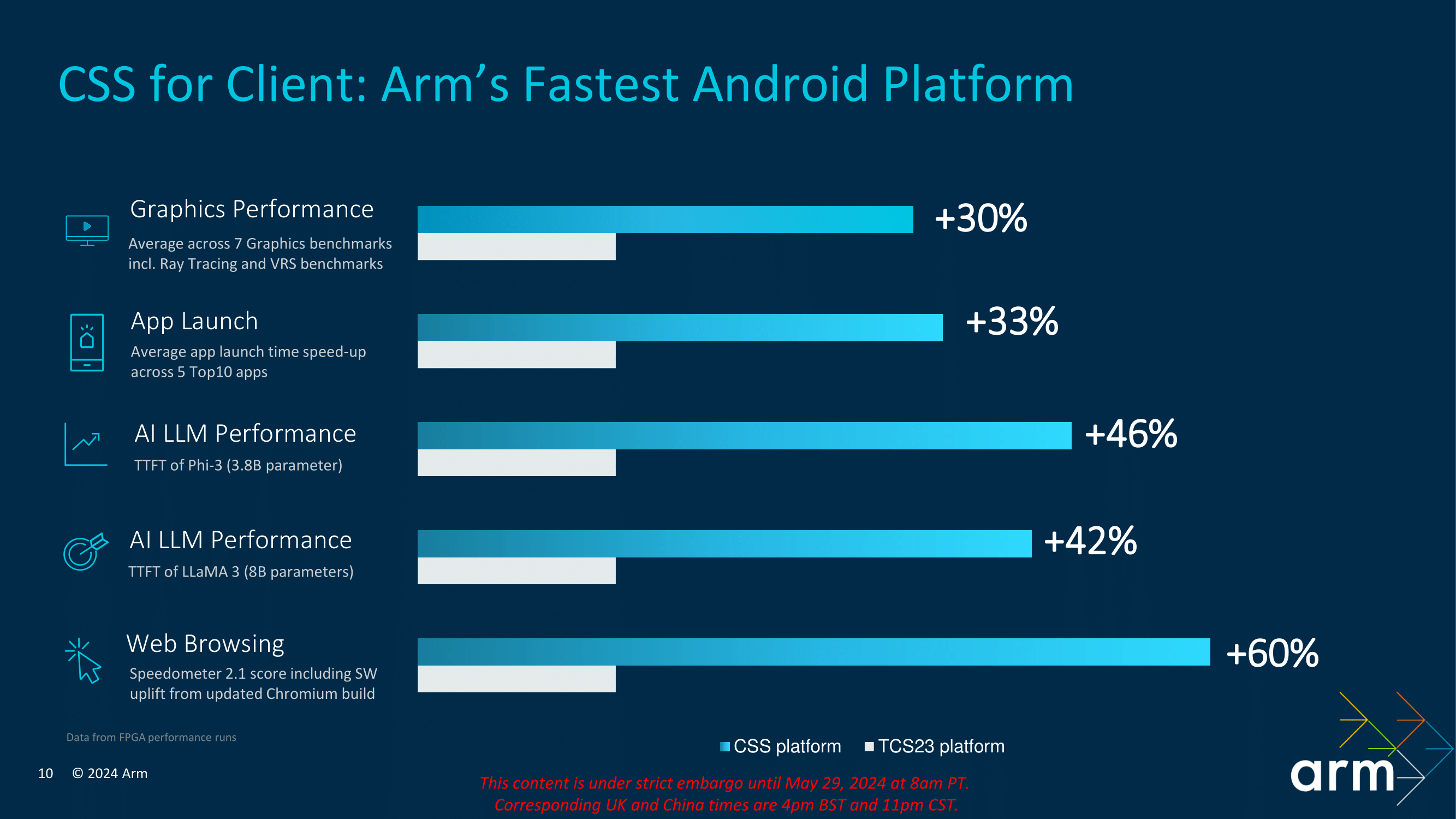
In the grand scheme of things, and from Arm's in-house performance comparisons between the new CSS platform and last year's TCS2023 version, Arm claims gains of between 30 and 60% in performance, depending on the task and workload. If it is to be believed and taken as gospel, the performance improvements are incredible, with the likely transition to 3 nm being the primary improver of performance rather than the underlying architectural improvements.
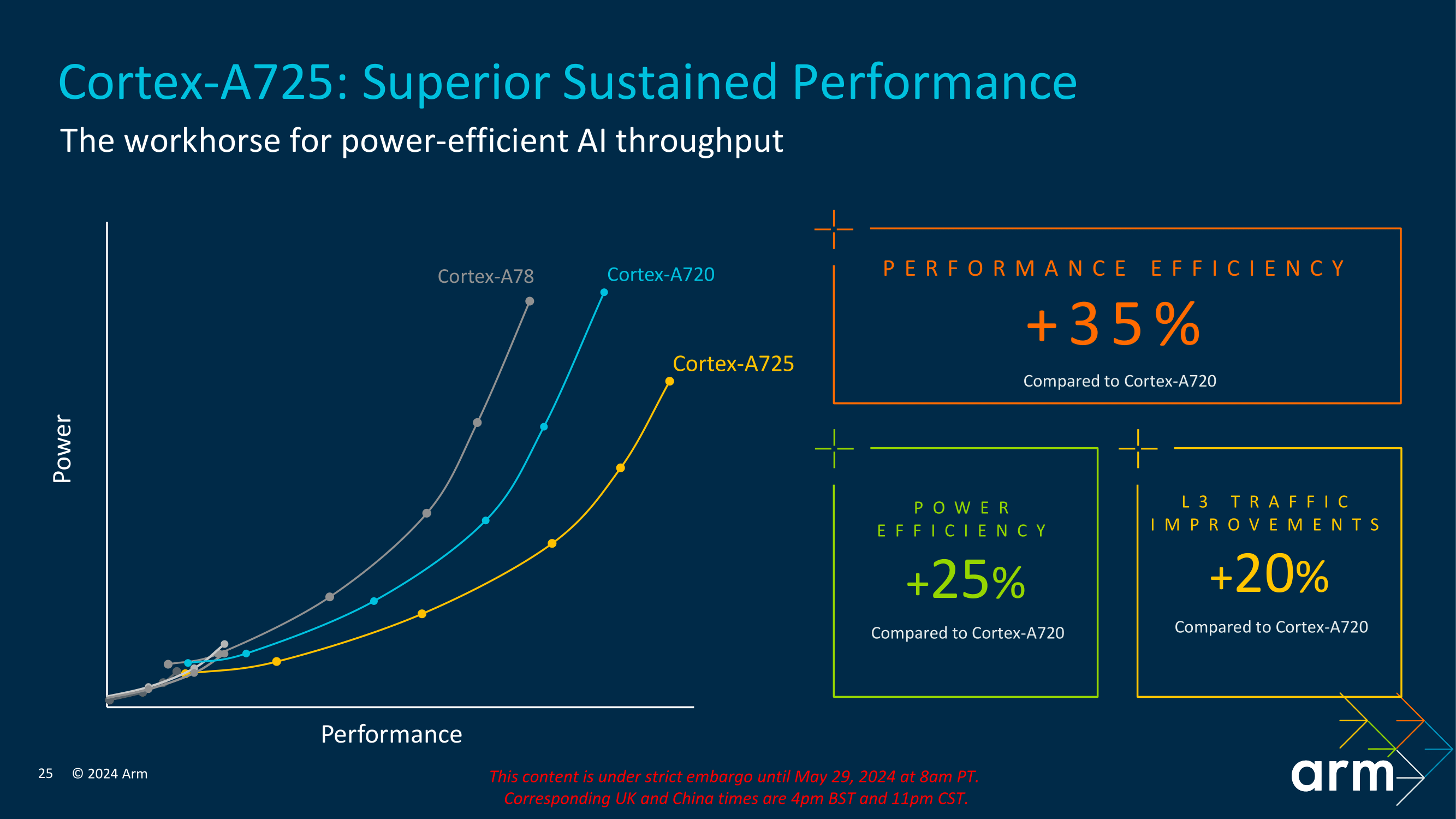
The Cortex-A725 balances performance and efficiency, making it suitable for several mid-range devices. Thanks to architectural enhancements such as increased cache sizes and expanded reorder buffers, Arm claims the improvements achieve up to 35% performance efficiency over the previous generation. The refreshed Cortex-A520 focuses primarily on being optimized on the 3 nm node while looking to remain unmatched in power efficiency, achieving a 15% energy saving compared to its predecessor. This core is optimized for low-intensity workloads, making it ideal for power-sensitive applications like IoT devices and lower-cost smartphones.
AI capabilities have been a significant focus in Arm's latest offerings. The Cortex-X925 and Cortex-A725 cores primarily integrate dedicated AI accelerators, allowing access to optimized software libraries, such as KleidiAI and KleidiCV, ensuring efficient AI processing. These enhancements are crucial for applications ranging from neural language models and LLMs.

Arm also continues to support its latest Core Cluster with a usually adept and comprehensive ecosystem driven by the new CSS platform, coupled with the Arm Performance Studio and in tandem with the Kleidi AI and CV libraries. These provided tools give developers a robust foundation to fully leverage the new architecture's capabilities. This effectively reduces the overall time-to-market and fosters innovations across various industries, such as content creation and on-device AI inferencing. The CSS platform's integration with operating systems such as Android, Linux, and Windows (Windows on Arm) ensures a larger reach in adoption. It pushes a wider level of development, making software and applications available on more devices than in previous generations.
In summary, Arm's move to all its latest CPU designs onto the 3 nm process technology and the refinements in the Cortex-X925 and Cortex-A725 cores demonstrate a strategic focus on optimizing existing architectures rather than making radical changes. These refinements include increased cache sizes per core, moving to a wider pipeline, and bolstering the DSU-120 Core Cluster for 2024, which certainly delivers substantial performance and power efficiency gains on paper.
While enabling new devices capable of handling demanding applications, most of these improvements in efficiency and performance are prevalent from the switch to the more advanced yet more challenging jump to the 3 nm node. As Arm continues to push the boundaries of what's possible with its IP, these technologies should pave the way for more powerful, efficient, and intelligent devices, shaping the future of what's possible and capable from a mobile device, whether that be in terms of the new generation of AI capable devices, or mobile gaming, Arm is looking to offer it all.








55 Comments
View All Comments
eastcoast_pete - Wednesday, May 29, 2024 - link
Speaking of SVE and SME: are there any applications (for Android, Windows-on-ARM or Apple devices) available to the general public that use either or both of them? SVE was originally co-developed by ARM and Fujitsu for the core that powers Fugaku, Riken's supercomputer. There are reports (rumors) that SVE is painful to implement, and someone wrote that Qualcomm elected to not enable SVE in their 8 Gen3 SoC, even though it's in their big cores. Anyone here knows, can comment? Right now, outside of 1-2 benchmarks, which applications actually use SVE, never mind SME? Replyname99 - Wednesday, May 29, 2024 - link
Presumably ARM’s Kleidi AI libraries (and various MS equivalents) use SVE and SME if present.And that’s really what matters. This functionality is envisaged (for now) as “built-in”.
Obviously they want developer buy-in over time, but that’s not what matters right now; what matters is what’s in the OS and API’s. Same as the fact that AMX was available to developers via Accelerate was great, but the primary user was Apple’s ML APIs. Reply
Marlin1975 - Thursday, May 30, 2024 - link
What do you mean, its all there. They went over the Optimized design that will take advantage of the synergies of the new NM tech from a leading edge lithography manufacture and lead them to greater performance. Its a win win for everyone, are you not onboard?:) Reply
syxbit - Wednesday, May 29, 2024 - link
I suspect this will still be worse than the A17 and the Nuvia chips. ReplyGC2:CS - Wednesday, May 29, 2024 - link
A17 and M3 and M4 did not show much benefit by going to the 3nm. If ARM can do better than only good for them. ReplyBGQ-qbf-tqf-n6n - Wednesday, May 29, 2024 - link
A17 was already 30% faster than S8G3 in single-core scores. In the same GB tests ARM is referring to, M4 is 27% faster still.Presuming the X925 is relative to the X4 with “36 percent faster”, they’ll still be behind M3, much less M4. Reply
OreoCookie - Saturday, June 1, 2024 - link
The speed ups in single and multi core were significant. To my knowledge the 10-core M4 is the fastest stock CPU in single core performance that was tested (about 13 % faster than Intel's Core i9 14900 KS, which clocks up to 6.2 GHz stock). The M3 is about 6 % behind the 14900 KS. (I am unaware of e. g. SPECmark results for the M4.) Replymode_13h - Saturday, June 1, 2024 - link
> I am unaware of e. g. SPECmark results for the M4.I'm pretty sure nobody is testing that, since Anandtech stopped doing it (i.e. after Andrei left). Reply
OreoCookie - Sunday, June 2, 2024 - link
Yeah, and it seems nobody is doing it consistently across several generations. The best dissection of the M3 architecture I remember was by a Chinese Youtube channel, but nobody is carrying the baton. Maybe Ian and Andrei are doing this as part of their work for clients. (Andrei, I think, is working for Qualcomm now, isn't he?) Replymode_13h - Monday, June 3, 2024 - link
name99 would know what M3 analysis is out there. He wrote/compiled the Apple M1 explainer, which is a 300-page PDF you can find with all the details about it.https://github.com/name99-org/AArch64-Explore/ Reply