NVIDIA ARM SoC Roadmap Updated: After Xavier Comes Orin
by Ryan Smith on March 29, 2018 11:00 AM EST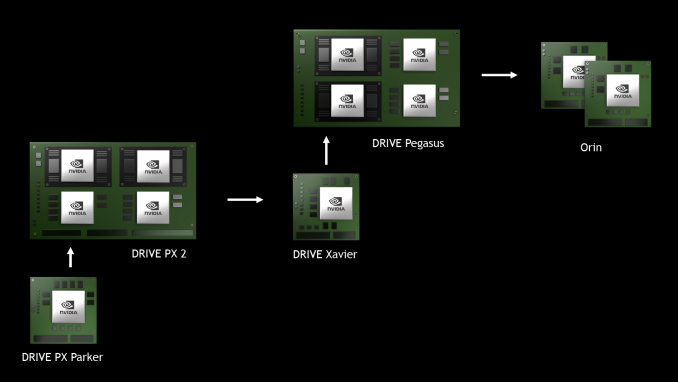
As part of this week’s GTC 2018 keynote address, NVIDIA CEO Jen-Hsun Huang quickly touched upon the future of NVIDIA’s ARM SoC lineup. While the company no longer publicly advertises or sells new ARM-based SoCs – the last SoC branded Tegra was the Tegra X1 – they have continued development for private uses. Chief among these of course being their DRIVE systems, where the Xavier SoC is at the heart of both the single-SoC Xavier module, as well as the larger and more powerful muti-processor Pegasus module for level 5 vehicles.
While Xavier itself is just now sampling to partners, NVIDIA already has their eye on what’s next. And that is Orin.
Unlike even the Xavier tease in 2016, NVIDIA is saying very little about Orin other than the fact that it’s the next generation of NVIDIA SoCs. Like Xavier, it’s a single-chip solution. But otherwise we don’t know anything about the planned architecture or features.
| NVIDIA ARM SoC Specification Comparison | |||||
| Orin | Xavier | Parker | |||
| CPU Cores | ? | 8x NVIDIA Custom ARM "Carmel" | 2x NVIDIA Denver + 4x ARM Cortex-A57 |
||
| GPU Cores | ? | Xavier Volta iGPU (512 CUDA Cores) |
Parker Pascal iGPU (256 CUDA Cores) |
||
| DL TOPS | [A Ton] | 30 TOPS | N/A | ||
| FP32 TFLOPS | ? | 1.3 TFLOPs | 0.7 TFLOPs | ||
| Manufacturing Process | 7nm? | TSMC 12nm FFN | TSMC 16nm FinFET | ||
| TDP | ? | 30W | 15W | ||
With respect to performance, NVIDIA isn’t giving hard figures there either, but they are saying that they want to replace a Pegasus module with a couple of Orins. Pegasus, as a reminder, is a pair of Xaviers each with an unnamed, post-Volta discrete GPU attached, with a total power consumption of 500W. So to replace that with a couple of single-chip SoCs would be a significant accomplishment – and presumably a massive bump in energy efficiency.
But finally, let’s talk about the real question on everyone’s mind: which superhero is this new SoC named after? After a run in the Marvel universe, it looks like NVIDIA is back to favoring DC. A brief search shows that Orin is another name for Aquaman. Which certainly isn’t as high-profile as the likes of Kal-El, Wayne, or Xavier, but perhaps Jen-Hsun Huang is a big fan of Jason Momoa? (ed: and indeed, who doesn’t find Aquaman outrageous?)








43 Comments
View All Comments
Trixanity - Thursday, March 29, 2018 - link
How come Xavier's quoted TFLOPS count is less than double of Parker? The TDP is twice as high, the GPU twice as big with newer CUDA cores and spanking new (and more) custom ARM cores? One would think the TFLOPS would be more than twice as big - perhaps even surpassing 2 TFLOPS. My brain can't compute this.karthik.hegde - Thursday, March 29, 2018 - link
It is FP32 FLOPs, a large number workloads often need only half precision float or even only 8-bit float. Hence, at the cost of FP32 FLOPs, they increased Half-precision float.Trixanity - Thursday, March 29, 2018 - link
That makes sense. Thanks!iter - Thursday, March 29, 2018 - link
There is no such thing as 8bit float. Floating point numbers at 8bits of precision defies basic common sense. Lowest precision floating point implementations are 16 bit, i.e. half precision.It is 8bit INTEGERS. Which is why the chart says TOPS - tera operations per second rather than tera floating point operations per second. 8bit integers suffice for ML, and the compute units required are much simpler, smaller and energy efficient. Which is how they get to reach those highly disproportional throughput values.
name99 - Friday, March 30, 2018 - link
There are indeed 8-bit floats. See eghttp://www.cs.jhu.edu/~jorgev/cs333/readings/8-Bit...
https://en.m.wikipedia.org/wiki/Minifloat
It’s even a possible that at some point they’ll be considered a good match for neural nets or something which doesn’t demand precision but does want dynamic range? (But yeah, the accumulator for such systems would have to be very carefully designed...)
mode_13h - Friday, March 30, 2018 - link
I think it's pretty clear that @karthik.hegde meant to write 8-bit int. Everyone is all about inferencing with small-width ints.name99 - Friday, March 30, 2018 - link
Sure. But I think it's interesting to know that the option for 8-bit floats exists.Even though they don't have essential use cases today (and so haven't been implemented in HW) we don't know what tomorrow will bring. NN, in particular, have created an environment where poor precision is often acceptable, but one has to play games with a manually tracked fixed point to maintain dynamic range, and it's possible that (for at least some subset of the problem, once appropriately reconceptualized) 8-bit FP might be a better overall fit --higher per-op energy, yes, but easier to code because one doesn't have to track the position of the fixed point.
mode_13h - Monday, April 2, 2018 - link
No. They also use up more die area than int, and if the benefits were that great, then we should've long ago seen a surge games' demand for fp16. In fact, having to support denormals probably burns most of the die area savings vs. fp16.The reality is that GPUs had fp32 in such abundance that games ditched fixed-point arithmetic long ago. In fact, it's in such low demand that GCN only bothered to implement a scalar integer ALU, as opposed to the 64-wide SIMD they have for fp32.
Looking towards the future, Intel has had 2xfp16 since Broadwell and AMD has it in Vega. If Nvidia brings it to their mainstream post-Pascal line, then we might actually see fp16 start to gain traction, in games. It just depends on how compute-bound they still are (fp16 load/store has been around for a while).
peevee - Tuesday, July 3, 2018 - link
fp16 is twice as energy efficient compared to fp32, and requires about half of the chip size for the same performance (or more, as multiplying 11-bit mantissas is way more than twice as cheap as 24-bit mantissas). Meaning enablement of 1080p+ gaming on battery-powered, even small and light laptops, just as it enabled phone and tablet games.It is also more useful for AI for the same power+performance+cost reasons.
The whole fp32 thing was a strategic mistake made for 640x480 no-AA low-detail gaming.
mode_13h - Monday, April 2, 2018 - link
And that first link you posted really drives home the point about how tricky float8 would be to actually use. You'd have epsilon issues all over the place!Honestly, fp32 has enough pitfalls, for me. I've never used fp16, but contemplating fp8 is a wake-up call that even fp16 would have to be used with care. Especially if no denormals (as I imagine GPUs implement it).