Hot Chips 2020 Live Blog: Baidu Kunlun AI Processor (4:30pm PT)
by Dr. Ian Cutress on August 18, 2020 7:30 PM EST- Posted in
- AI
- Live Blog
- Baidu
- Kunlun
- Hot Chips 32

07:29PM EDT - Last session of Hot Chips is all about ML inference. Starting with Baidu, and its Kunlun AI processor
07:30PM EDT - We’ve heard of Baidu’s Kunlun a few months ago due to a press release from the company and Samsung stating that the silicon was making use of Interposer-Cube 2.5D packaging, as well as HBM2, and packing 260 TOPs into 150 W.

07:32PM EDT - Baidu and Samsung build the chip together

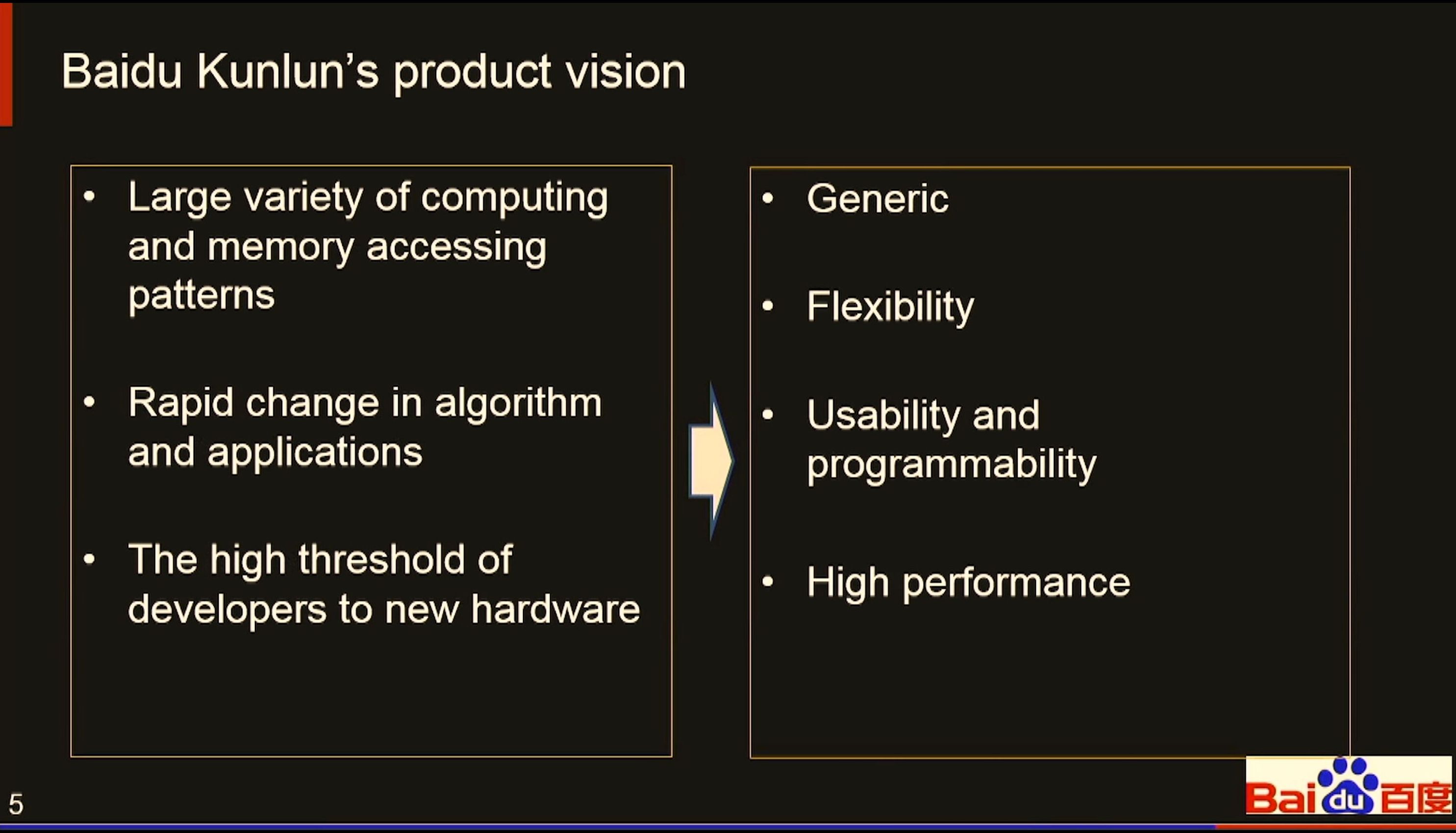
07:33PM EDT - Need a processor to cover a diversified AI workflow
07:33PM EDT - NLP = Neural Language Processing
07:33PM EDT - All these systems are priority inside Baidu

07:34PM EDT - Traditional AI computing is performed in Cloud, Datacenter, HPC, Smart Industry, Smart City
07:35PM EDT - High-end AI chips cost a lot to create
07:36PM EDT - Try to explore market volume as much as possible
07:36PM EDT - The challenge is the type of compute
07:36PM EDT - Design and implementation

07:38PM EDT - Kunlun (Kun-loon)
07:38PM EDT - Need flexible, programmable, high performance
07:38PM EDT - Moved from FPGA to ASIC
07:39PM EDT - 256 TOPs in 2019
07:42PM EDT - (the presenter is a bit slow fyi)
07:43PM EDT - Now some detail
07:43PM EDT - Samsung Foundry 14nm

07:43PM EDT - Interposer package, 2 HBM, 512 GB/s
07:43PM EDT - PCIe 4.0 x8
07:43PM EDT - 150W / 256 TOPs
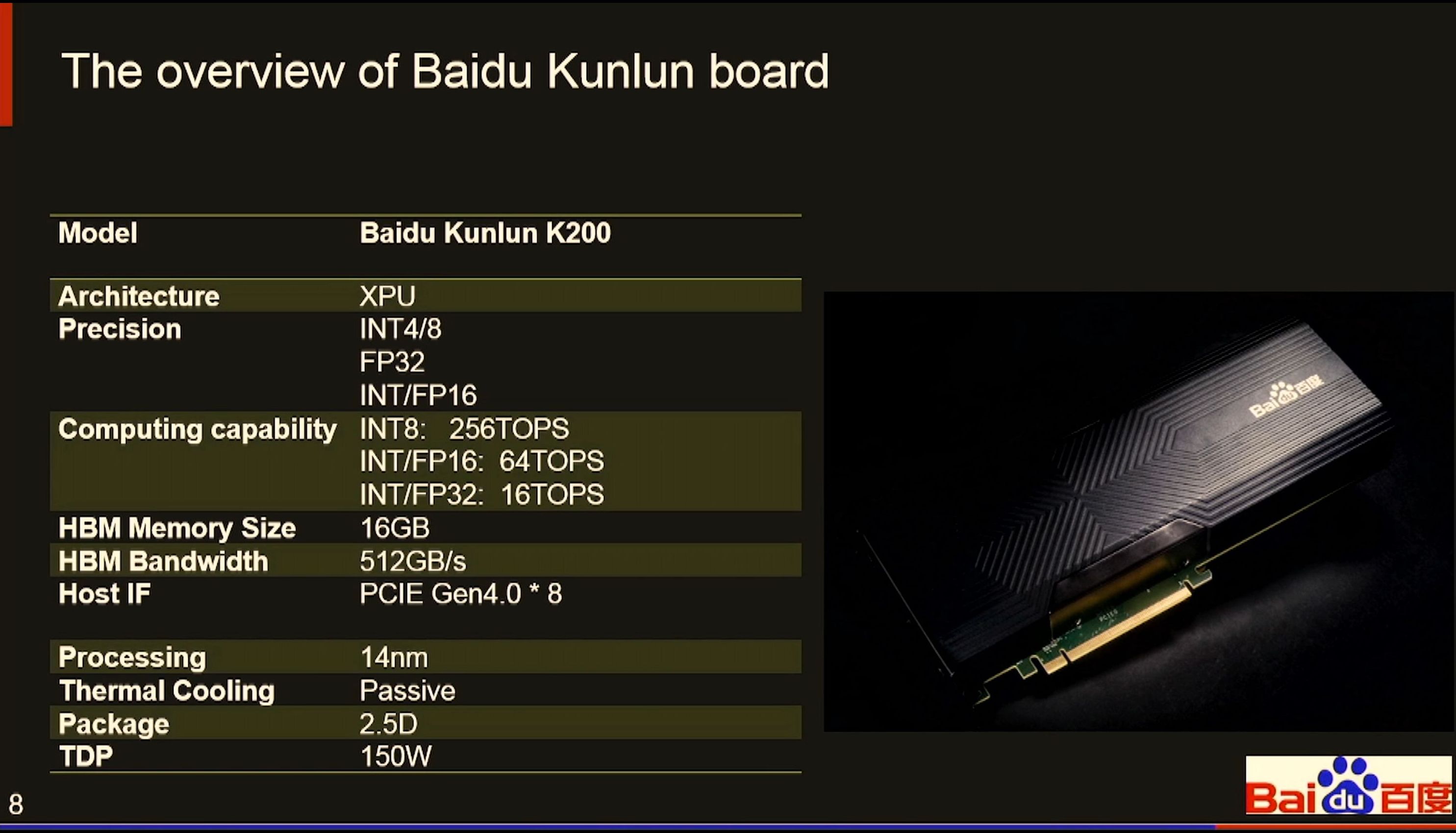
07:43PM EDT - PCIe card
07:44PM EDT - 256TOPs for INT8
07:44PM EDT - 16 GB HBM
07:44PM EDT - Passive cooling
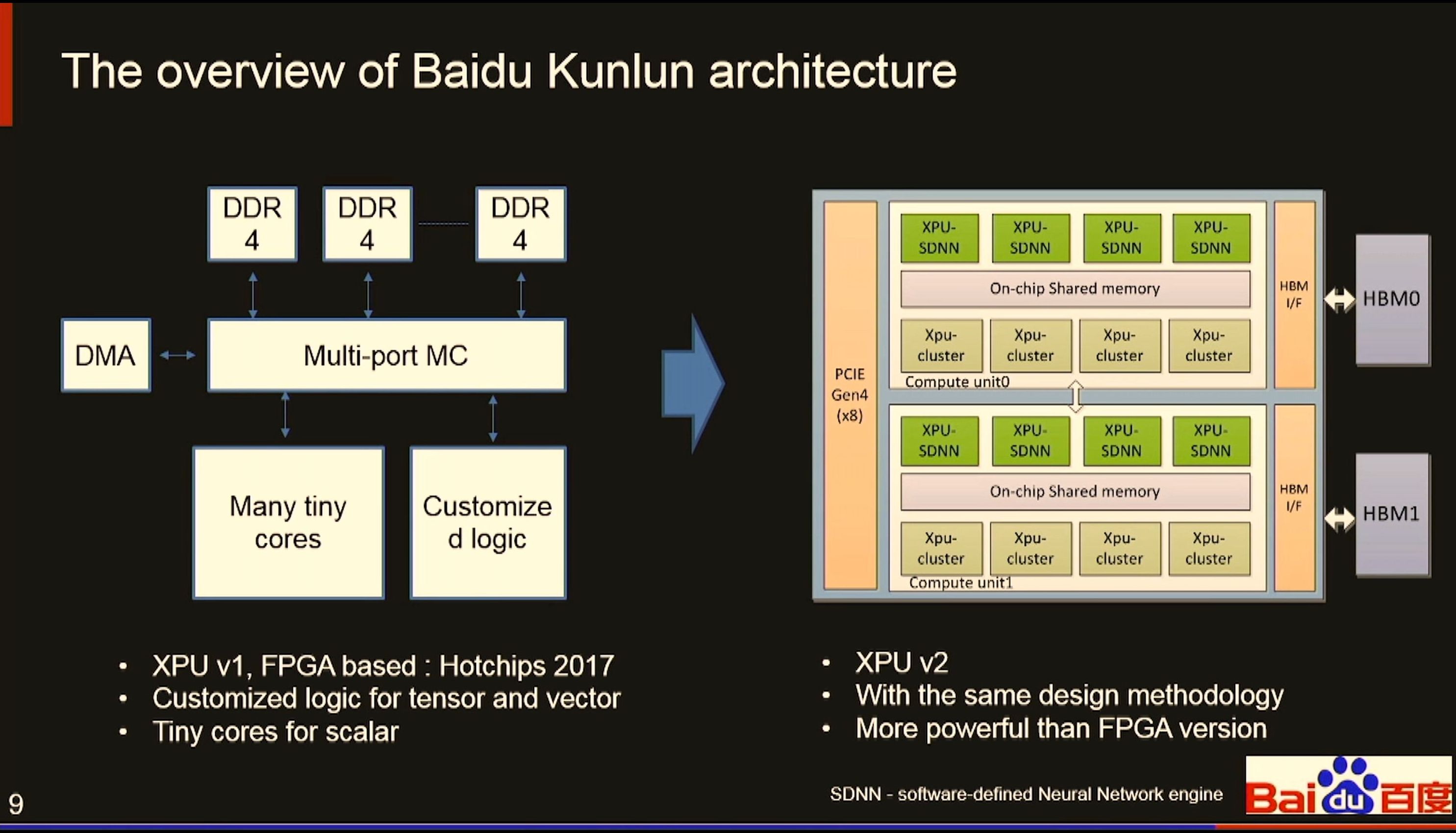
07:45PM EDT - Same layout as XPUv1 shown in HotChips 2017
07:45PM EDT - XPU cluster
07:45PM EDT - Software defined neural network engine
07:45PM EDT - XPU-SDNN
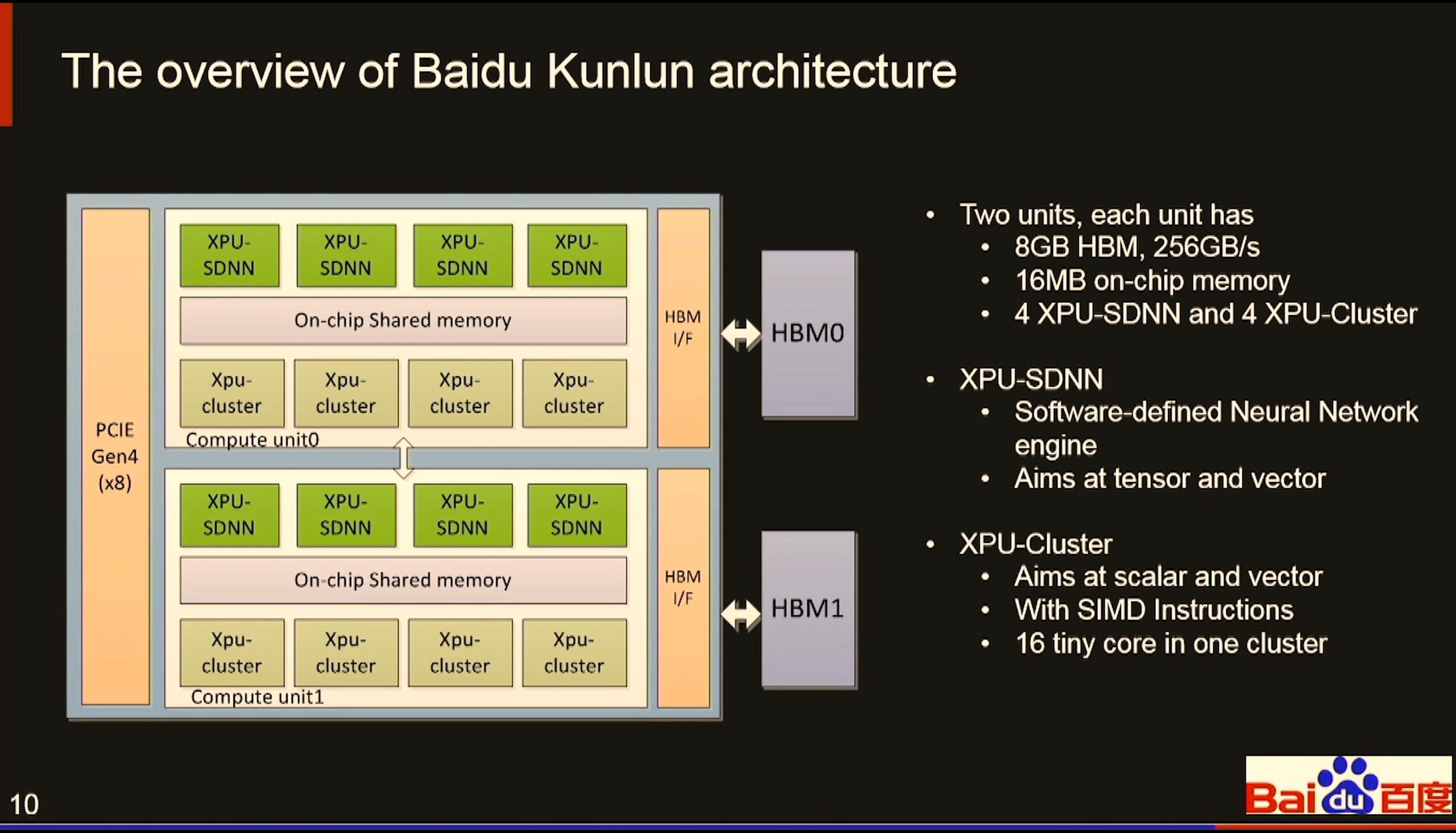
07:46PM EDT - XPU-SDNN does tensor and vector
07:46PM EDT - XPU-Cluster does scalar and vector
07:46PM EDT - Each cluster has 16 tiny cores
07:46PM EDT - each unit has 16 MB on-chip memory
07:47PM EDT - (what are the tiny cores?)
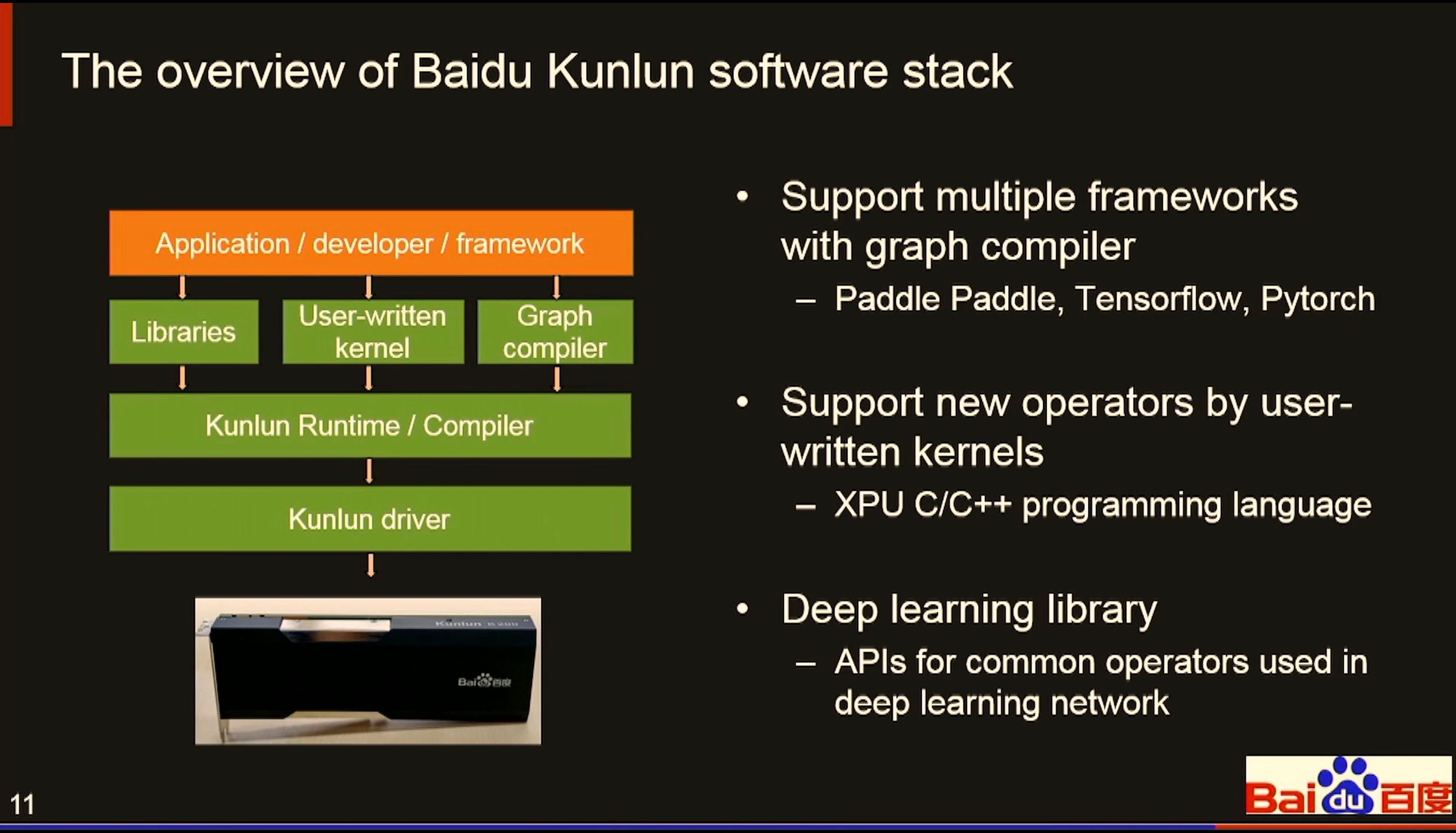
07:47PM EDT - Graph compiler
07:47PM EDT - supports PaddlePaddle, Tensorflow, pytorch
07:48PM EDT - XPU C/C++ for custom kernels
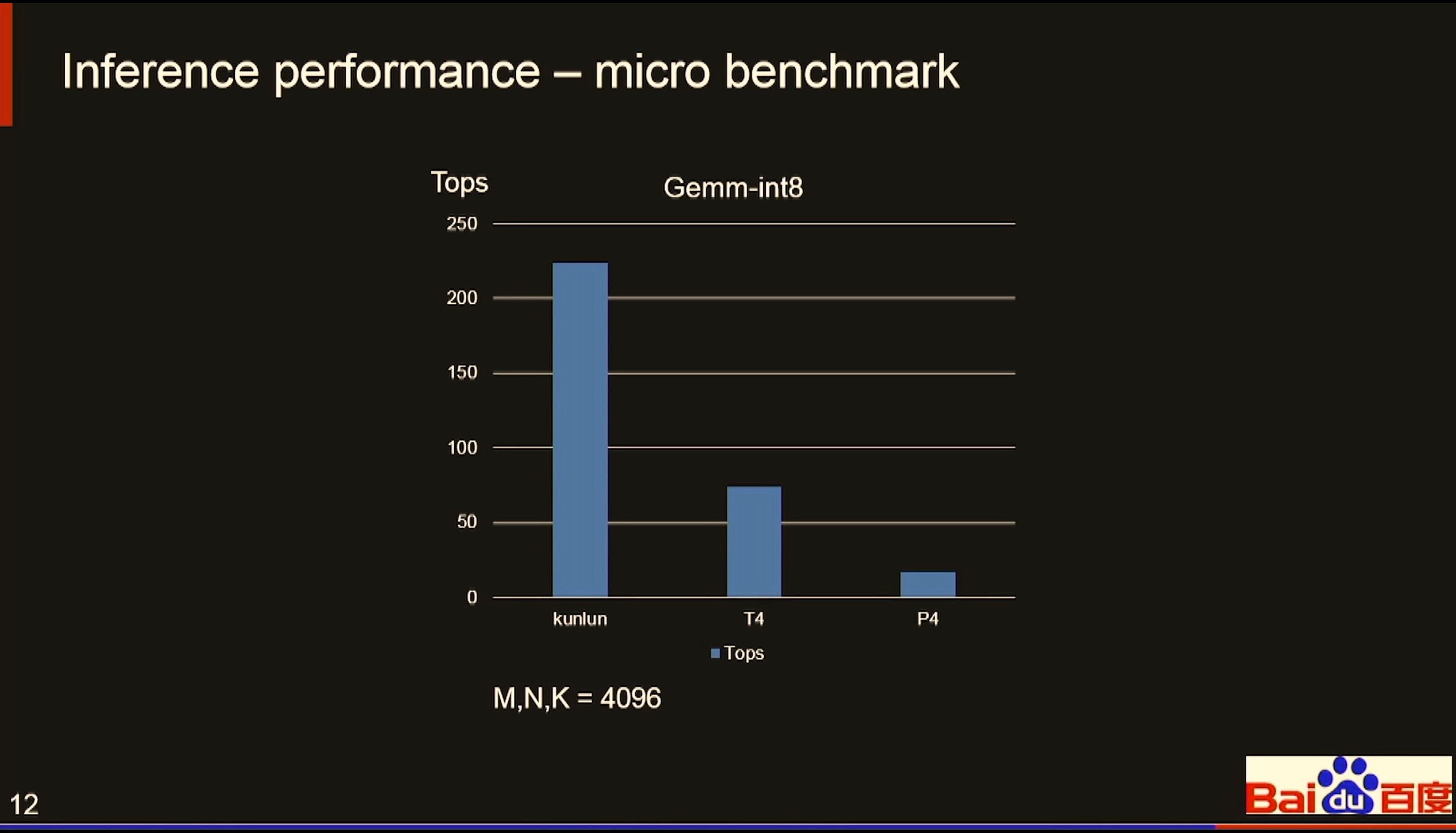
07:48PM EDT - 256 TOPs for 4096x4096x4096 GEMM INT8 inference


07:51PM EDT - These benchmarks are very odd

07:51PM EDT - big edge = industrial
07:51PM EDT - Mask inspection
07:52PM EDT - Mask RCNN

07:52PM EDT - Available in Baidu Cloud
07:53PM EDT - Q&A time
07:54PM EDT - Q: hardware image/video decode? A: No
07:55PM EDT - Q: INT4 throughput as INT8? A: INT4 same as INT8, but INT4 and leverage more of the capabilities
07:56PM EDT - Q: Size and BW of on-chip shared memory? A: BW is 512 GB/s for each port each cluster (I don't think that answers the questions)
07:56PM EDT - Q: Static scheduling of resources? A: Yes
07:57PM EDT - Q:Power? A: Real Power 70-90W, almost same as T4, but TDP 150W
07:57PM EDT - That's a wrap. Next talk is Alibaba NPU








0 Comments
View All Comments