Hot Chips 2021 Live Blog: Machine Learning (Esperanto, Enflame, Qualcomm)
by Dr. Ian Cutress on August 24, 2021 11:05 AM EST
11:08AM EDT - Welcome to Hot Chips! This is the annual conference all about the latest, greatest, and upcoming big silicon that gets us all excited. Stay tuned during Monday and Tuesday for our regular AnandTech Live Blogs.
11:08AM EDT - Event starts at 8:30am PT, so in about 22 minutes
11:25AM EDT - Starting here in about 5 minutes
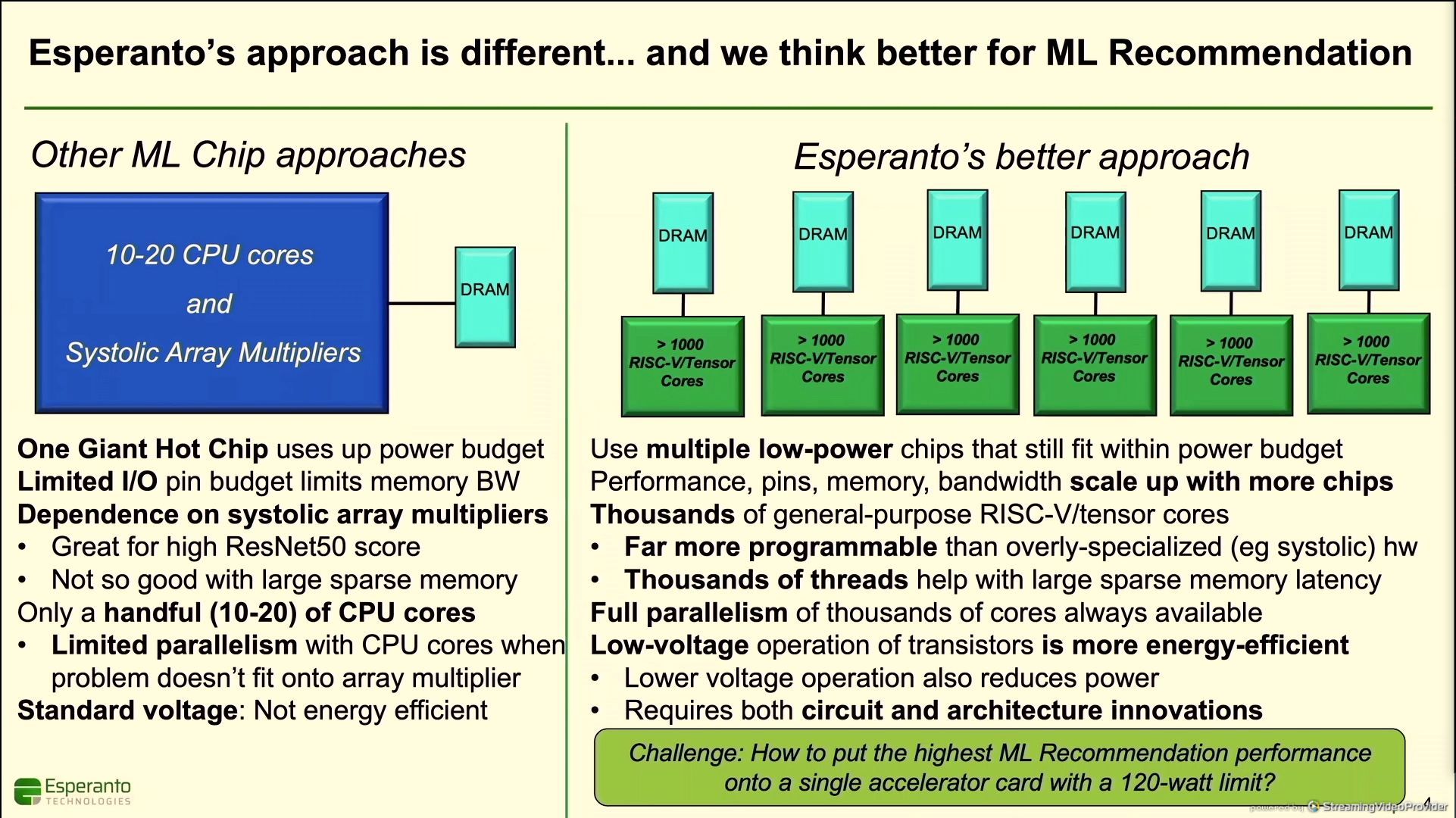
11:30AM EDT - First up is a talk from Esperanto Technologies
11:31AM EDT - AI Accelerator - 1000 RISC-V cores on a chip


11:32AM EDT - 1088 RISC-V cores
11:32AM EDT - ET-Minion with tensor units
11:33AM EDT - 160 million bytes of SRAM onboard
11:33AM EDT - PCIe x8 Gen 4
11:33AM EDT - Up to 200 Tera-Ops
11:33AM EDT - Under 20 watts for inference
11:33AM EDT - focus on recommendation models
11:34AM EDT - traditionally run on x86
11:34AM EDT - these servers need add-in cards
11:34AM EDT - Low power budget per card
11:34AM EDT - Multiple data type support
11:34AM EDT - dense and sparse workloads
11:34AM EDT - be programmable

11:35AM EDT - reduce off-die memory references
11:36AM EDT - Fixed function hardware can quickly become obsolete
11:37AM EDT - thousands of threads
11:38AM EDT - limited parallelism with single big chips
11:38AM EDT - 1000s of RISC-V cores in esperanto
11:38AM EDT - Large chips have large power
11:38AM EDT - Esperanto splits it across chips
11:38AM EDT - allows for lower voltage, increasing efciciency
11:38AM EDT - Highest recommendation performance inside 120W in six chips

11:40AM EDT - TSMC 7nm FinFET
11:40AM EDT - drive down voltage per core
11:40AM EDT - C dynamic is hard


11:41AM EDT - Efficiency vs voltage - 0.34 is best
11:42AM EDT - Inferences per second per watt
11:42AM EDT - One chip could use 275W at peak
11:42AM EDT - 0.75 volts is 164W per chip
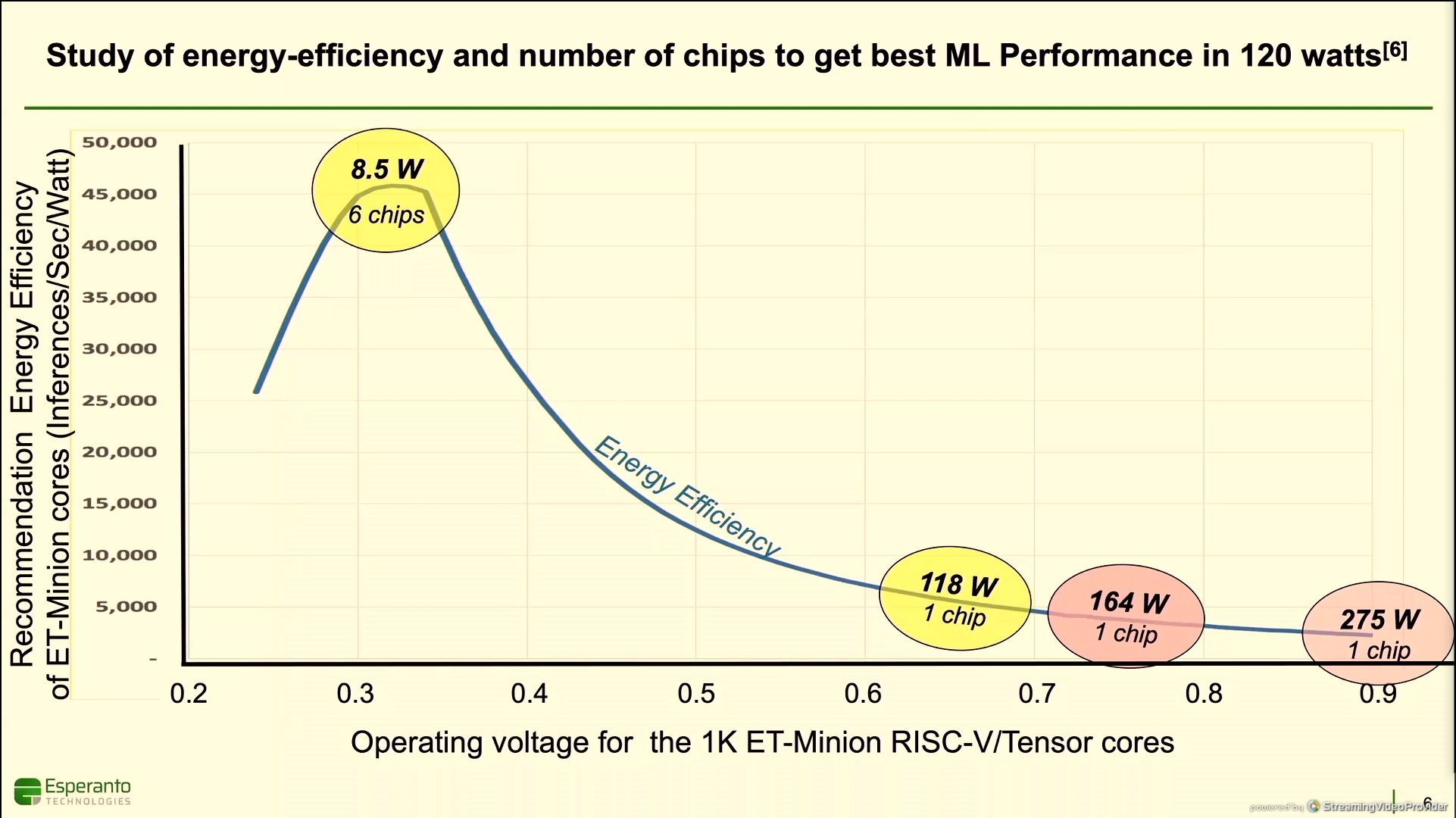
11:43AM EDT - Best efficient point is at 8.5 W - 2.5x better perf than at 0.9 volts


11:44AM EDT - 64-bit risc-v processor, software configurable l1 data cache
11:44AM EDT - in order pipeline
11:44AM EDT - SMT2
11:45AM EDT - 300 MHz to 2 GHz
11:45AM EDT - can do 64 ops on one tensor instruction
11:45AM EDT - 64k ops
11:45AM EDT - 512-bit wide integer per cycle, 256-bit wide FP per cycle, per core
11:46AM EDT - 8 cores on a chip form a neighborhood
11:46AM EDT - before wide length became a problem
11:46AM EDT - 8 minions share a single large instruction cache
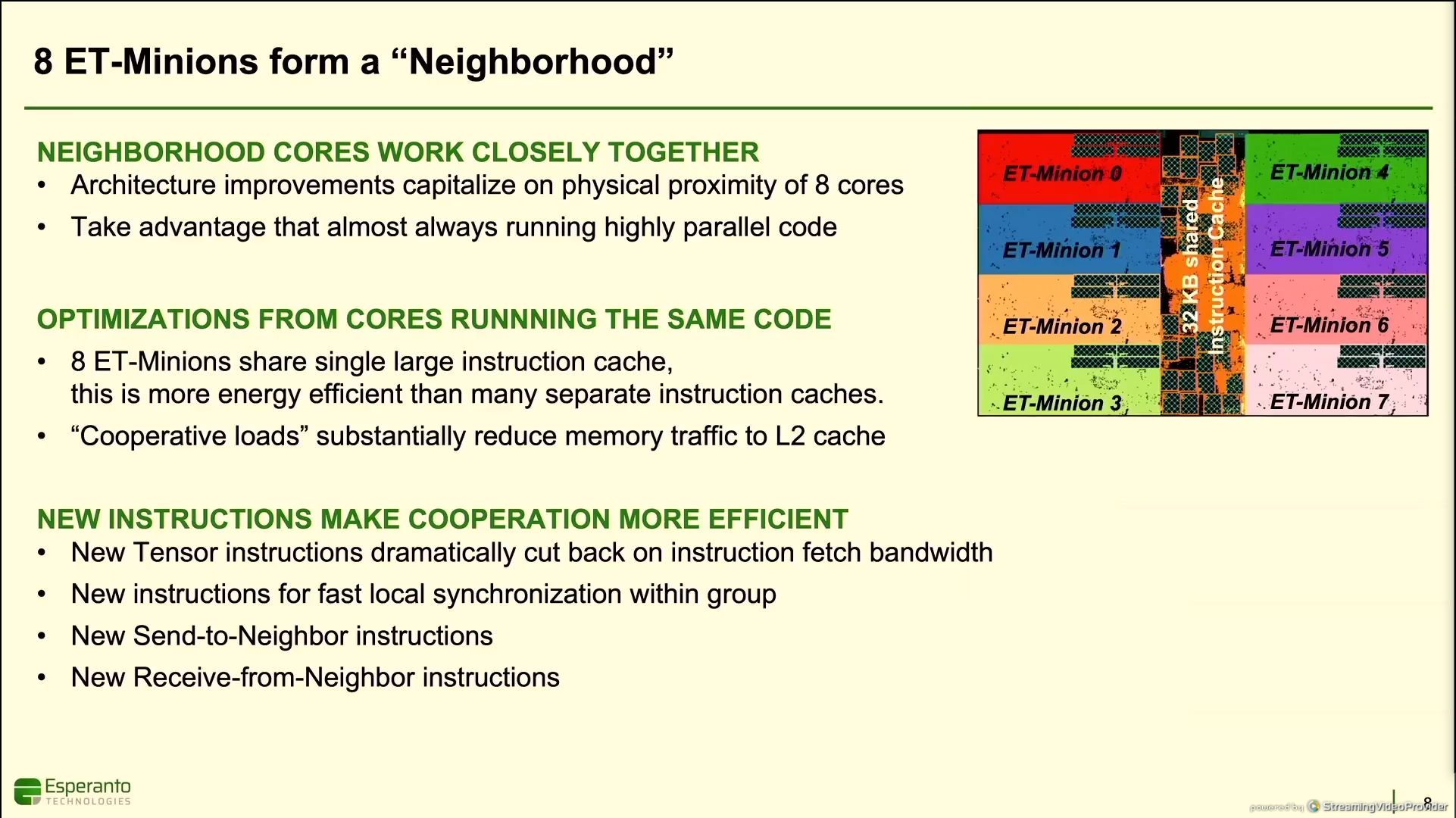
11:46AM EDT - far more efficient than having each core with its own I-cache
11:47AM EDT - cooperative loads
11:47AM EDT - custom instructions
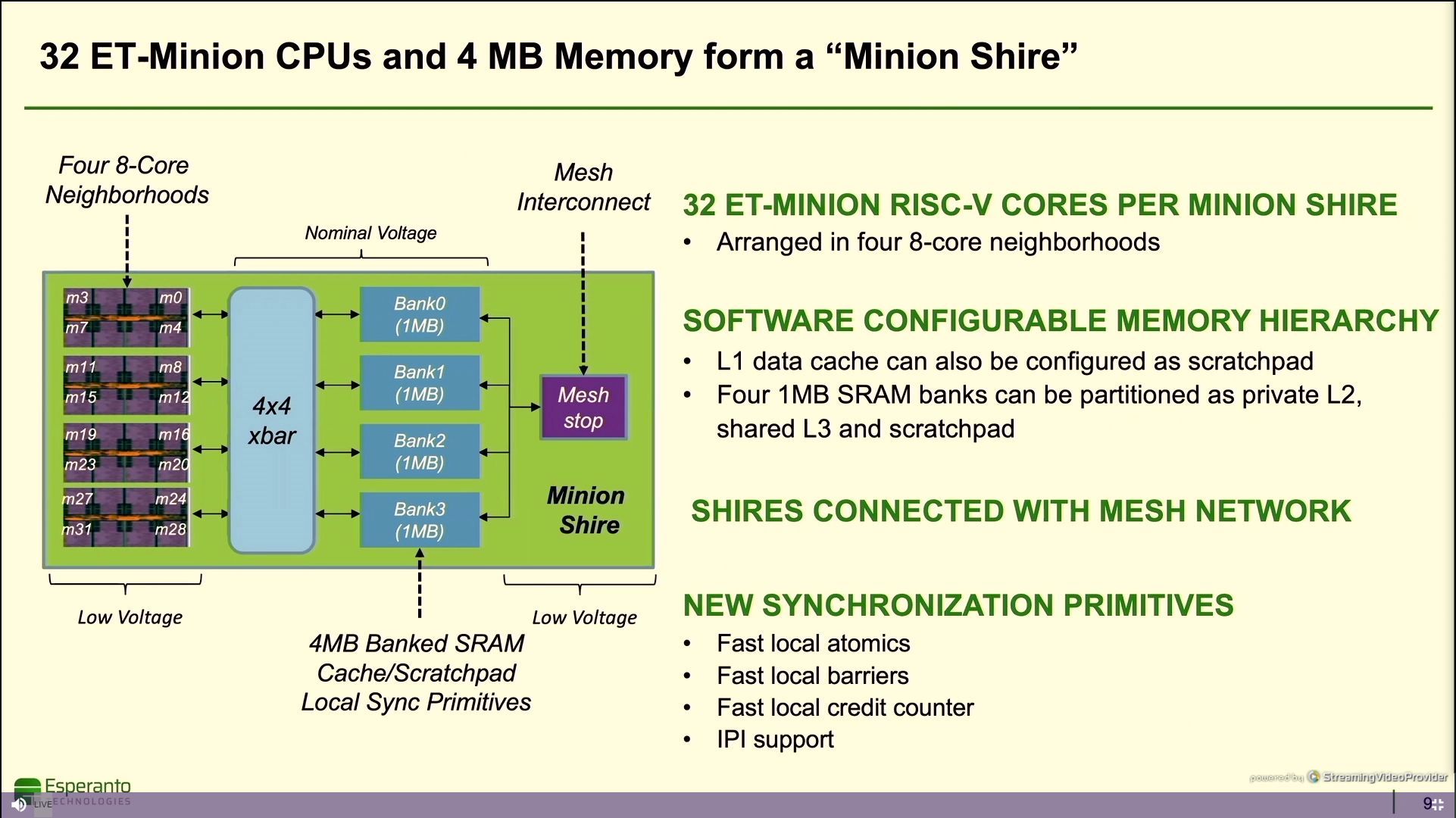
11:47AM EDT - 4 neighborhoods makes a shire
11:47AM EDT - with 4 MB of shared SRAM
11:48AM EDT - mesh interconnect on each shire
11:48AM EDT - SRAM banks could be partitioned as private L2 or shared L3
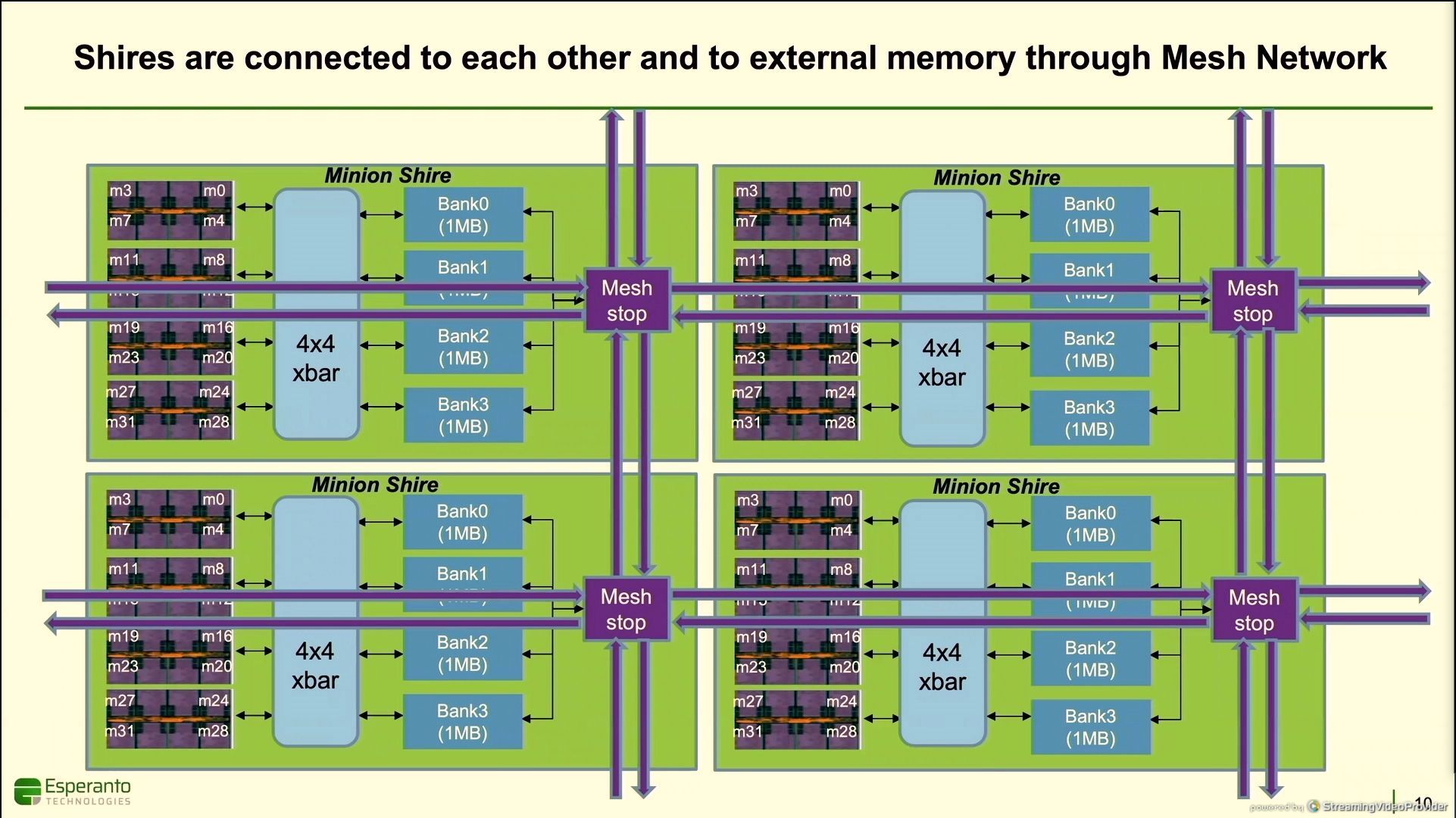
11:48AM EDT - Meshes run over the cores
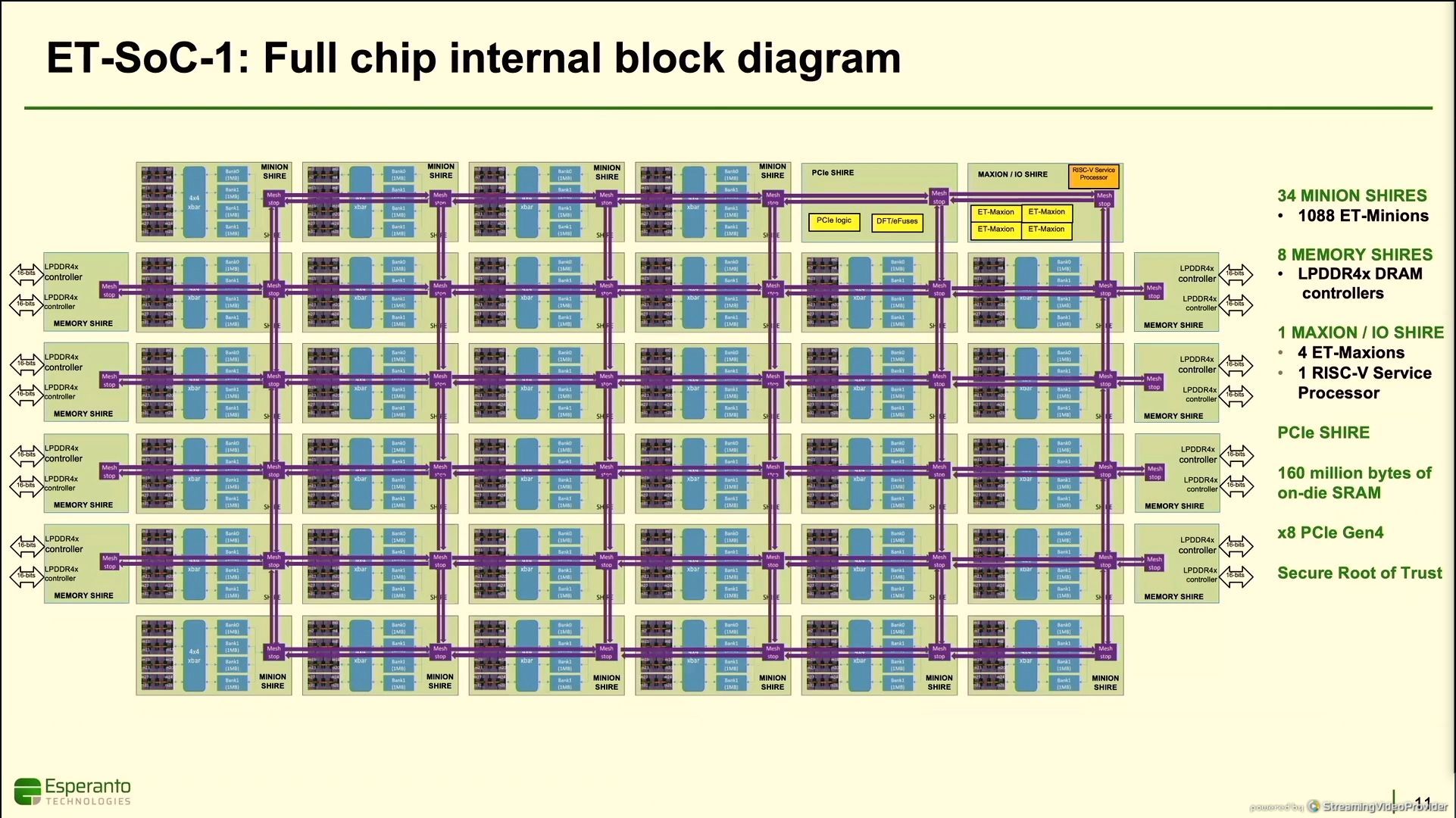
11:48AM EDT - 16 LPDDR4X controllers
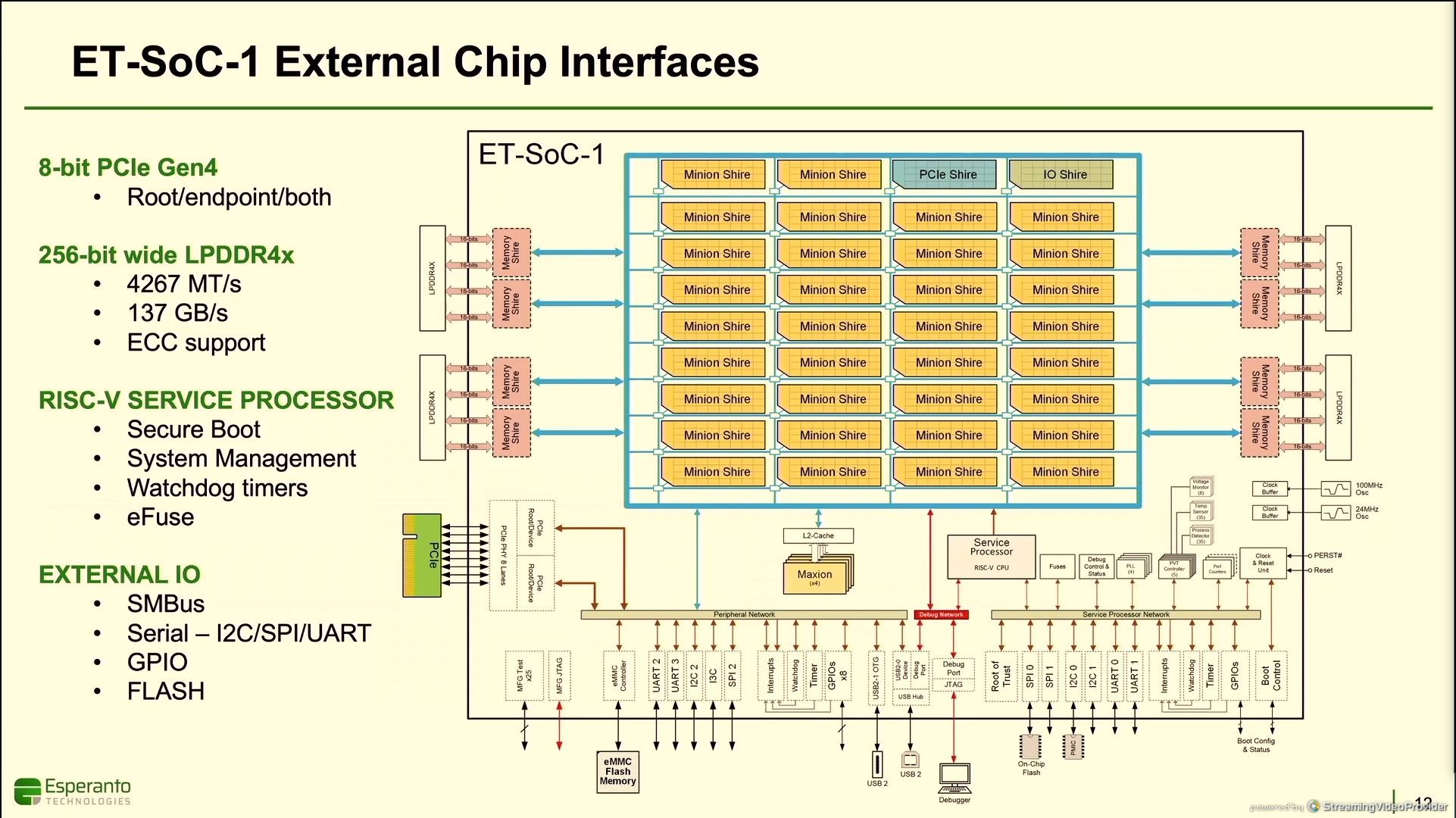
11:49AM EDT - 256-bit wide LPDDR4X
11:49AM EDT - Six chips and 24 LPDDR4 chips on a PCIe card with a PCIe switch
11:49AM EDT - 192 GB of accelerator memory
11:49AM EDT - 822 GB/s total memory bandwidth per PCIe card
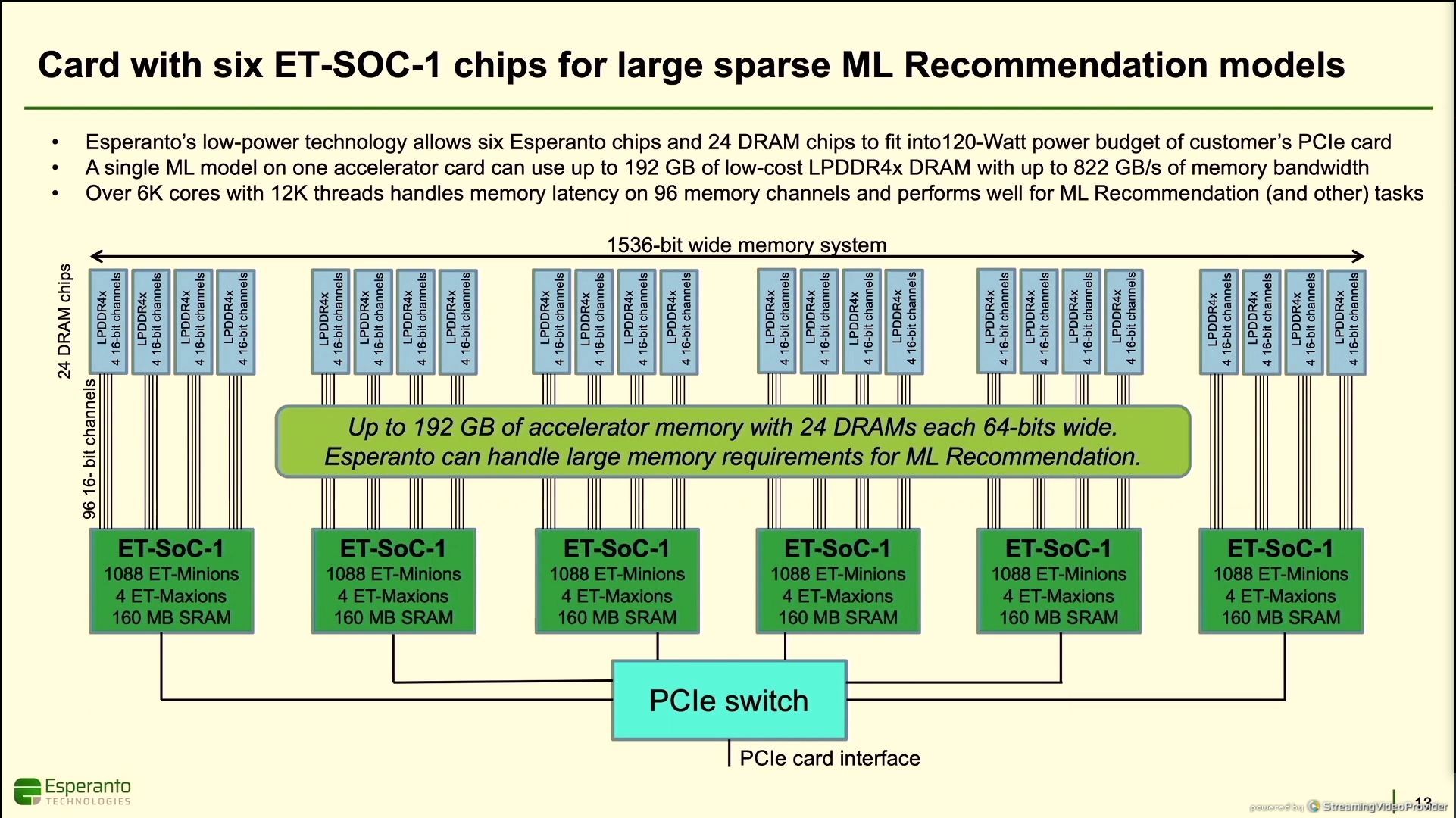

11:50AM EDT - OCP versions
11:50AM EDT - How to deploy at scale

11:50AM EDT - 6 chips have a single heatspreader
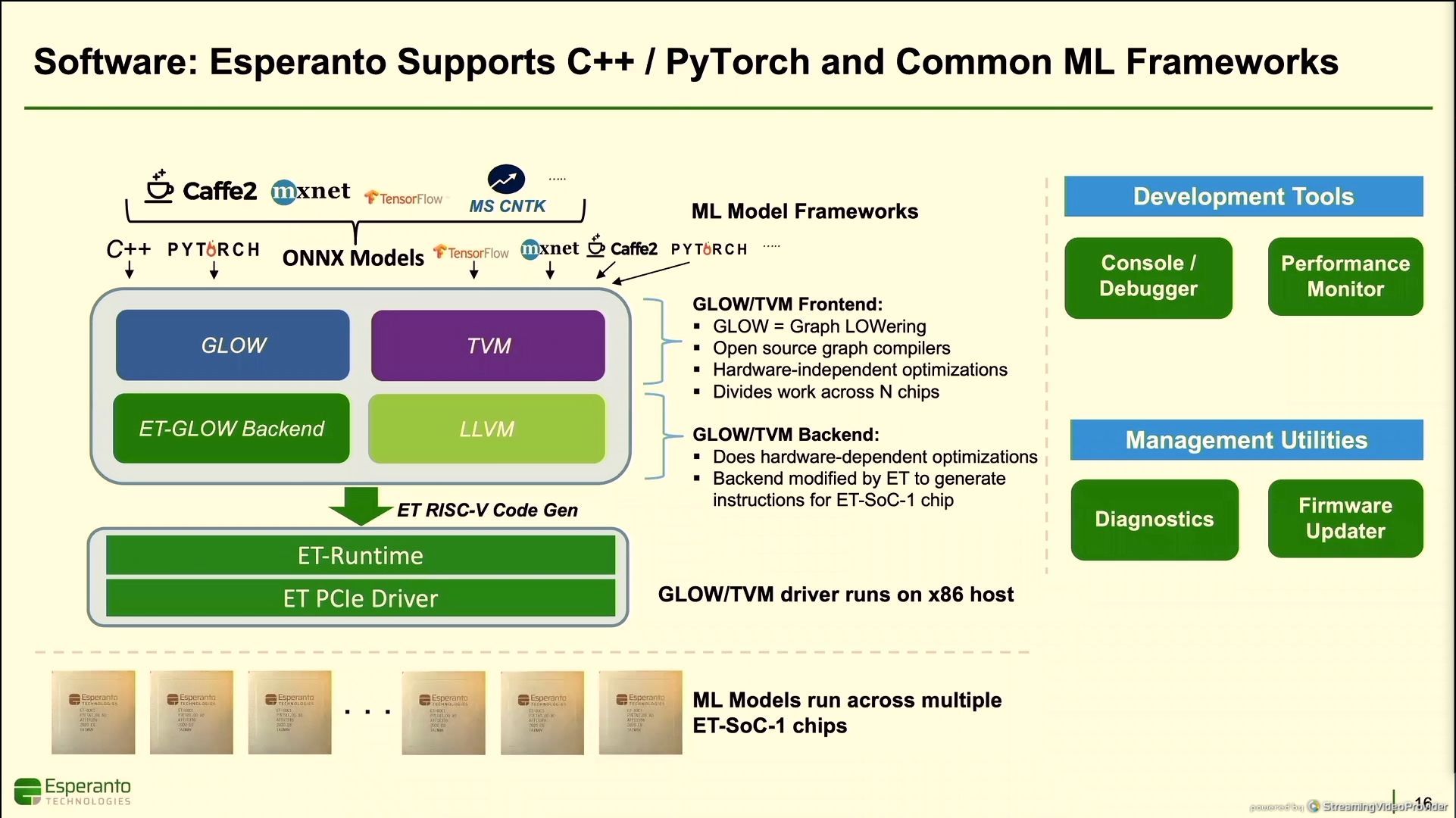
11:51AM EDT - Software through many interfaces
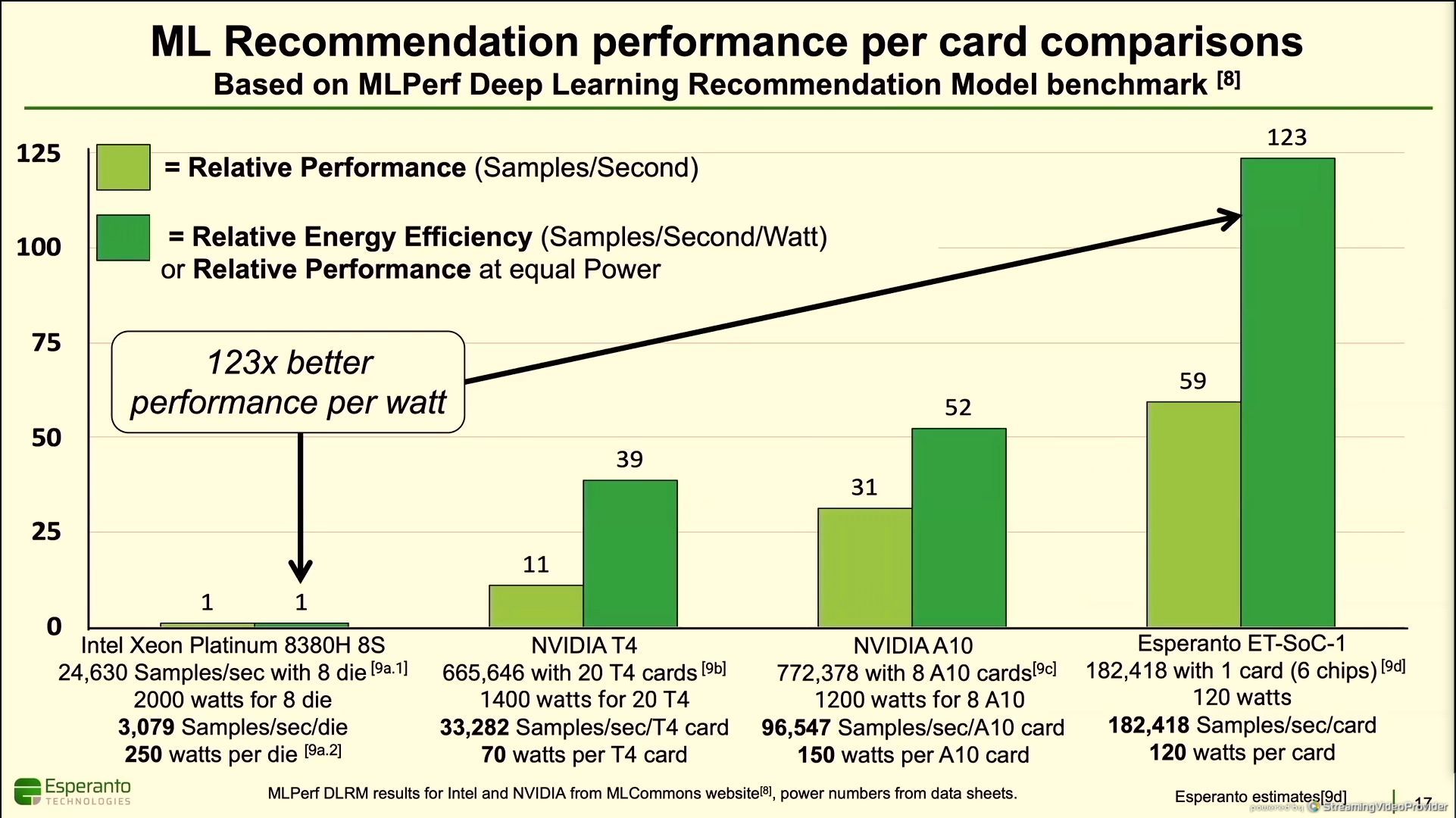
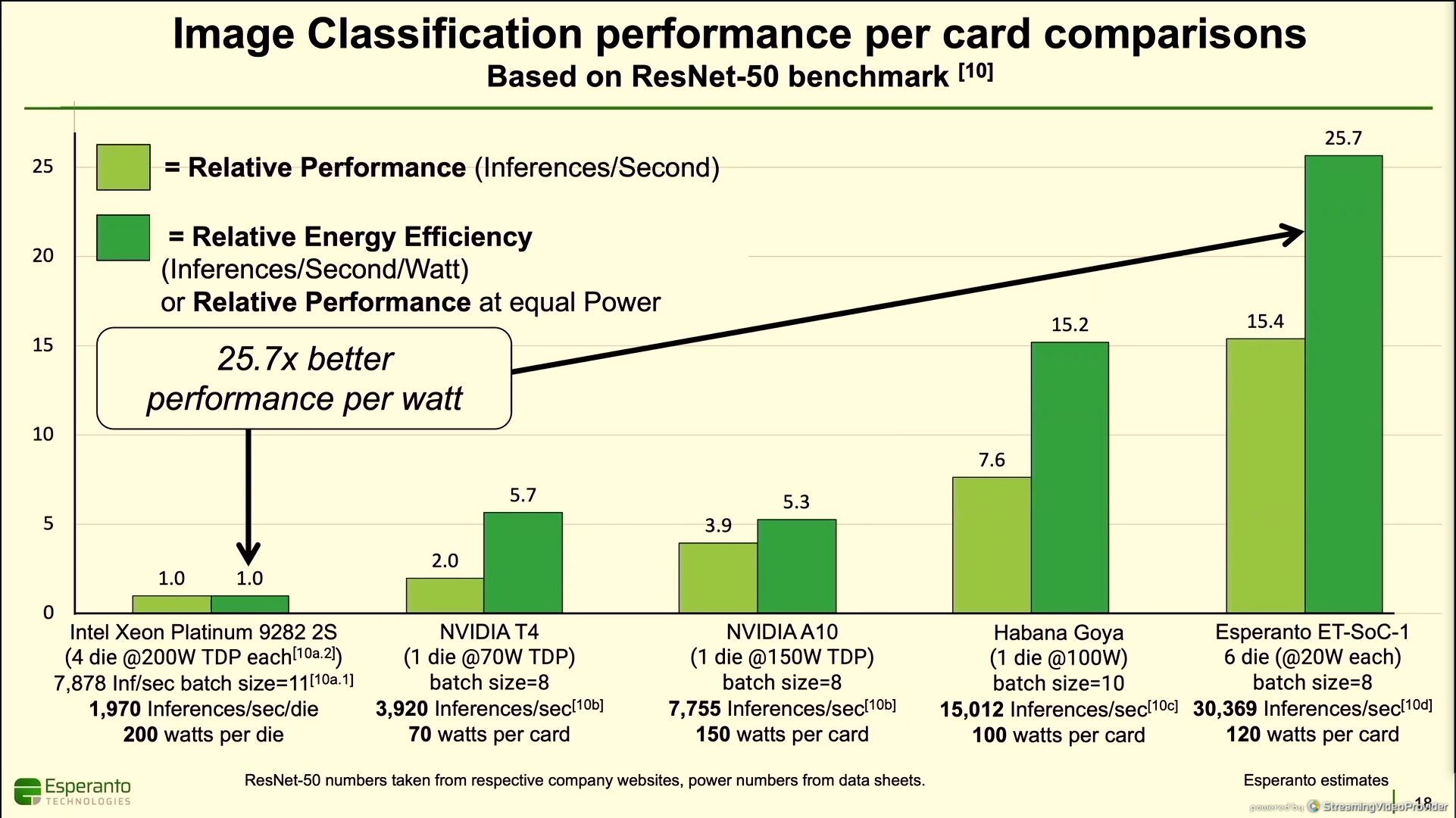
11:52AM EDT - Esperanto projected performance

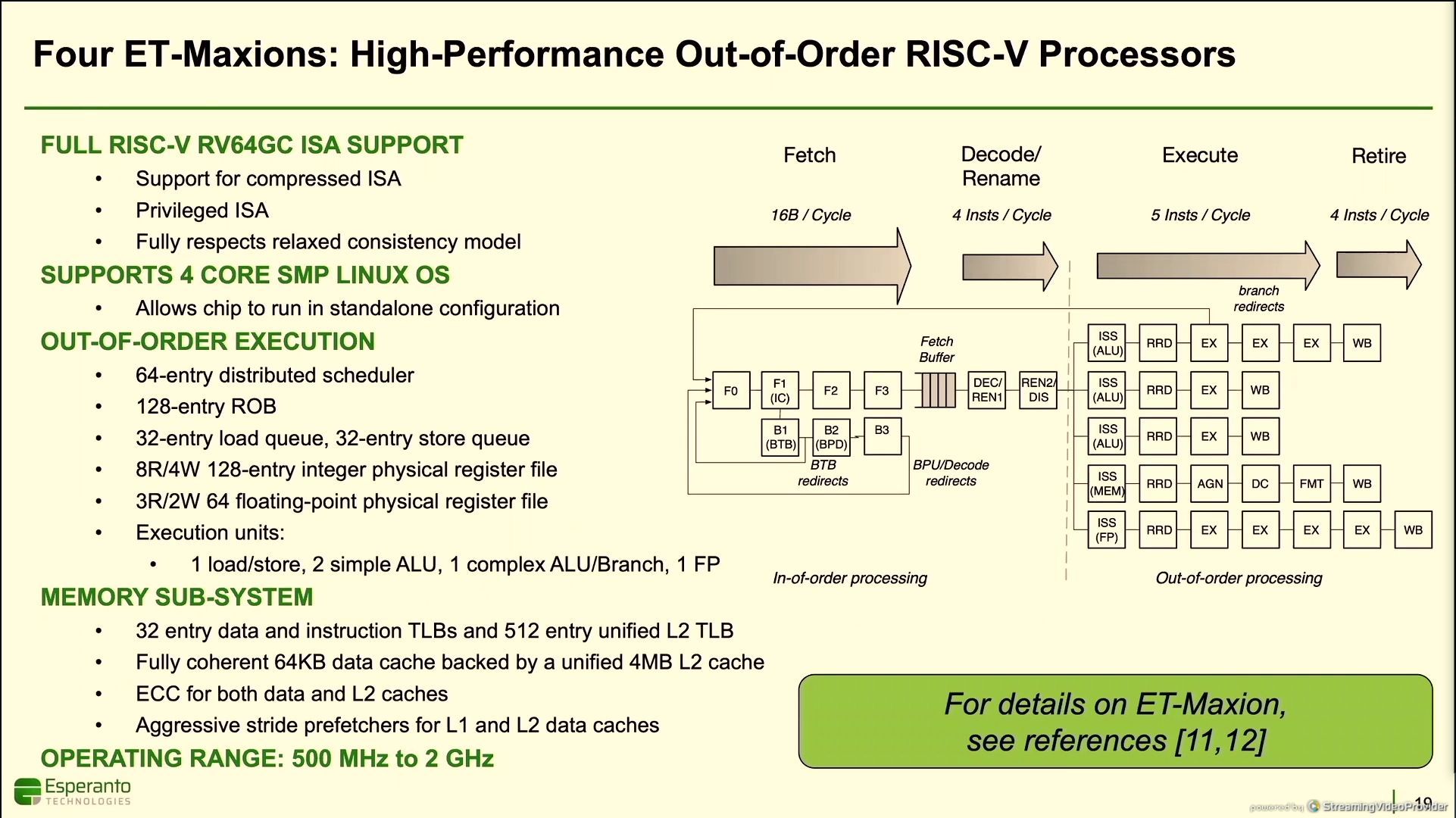
11:54AM EDT - Four high-performance ET-Maxions
11:54AM EDT - Full RV64GC ISA

11:54AM EDT - 24 billion transistors, 570mm2, 89 mask layers
11:54AM EDT - First silicon in bring up
11:55AM EDT - A0 silicon in test

11:55AM EDT - Highest performance commercial RISC-V chip to date
11:55AM EDT - Early Access for qualified customers later in 2021
11:56AM EDT - Q*A time
11:58AM EDT - Q: External memory and IO power add above 20W - A: IOs are included. 20W includes DRAM and other components
12:00PM EDT - Q: Why not BF16? A: Natively it does, but BF16 would be expanded FP32 for compute and put to BF16 back in storage. Because we do inference - customer wants inference, doesn't need BF16
12:01PM EDT - Q: Data cache size for general purpose A: With area of 1000 cores, shift L1/L2 to multi-level is important. Special circuits - keep very robust voltage, need to use large SRAM for low voltage. 4 KB L1 gave a good hit rate with the L2 for performance
12:02PM EDT - Next talk is Enflame

12:02PM EDT - First Gen
12:02PM EDT - Designed 2018, launched 2019
12:03PM EDT - DTU 1.0

12:03PM EDT - 80 TF of BF16, 12nm FinFet, 14.1 billion transistors, 200 GB/s interconnect
12:04PM EDT - 16 lanes PCIe 4.0
12:04PM EDT - 300W

12:05PM EDT - 2 HBM2 at 512 GB/s
12:05PM EDT - 32 AI compute cores
12:05PM EDT - ip networkj
12:05PM EDT - 4 clusters of 8 tensor units
12:06PM EDT - 40 data transfer engines
12:06PM EDT - on chip network*

12:06PM EDT - VLIW programmable
12:06PM EDT - 1024-bit bus with
12:06PM EDT - 256 KB of L1-Data
12:06PM EDT - DMA engine with 1 KB interface
12:07PM EDT - GPU-Care 1.0

12:07PM EDT - 256 Tensor compute Kernels
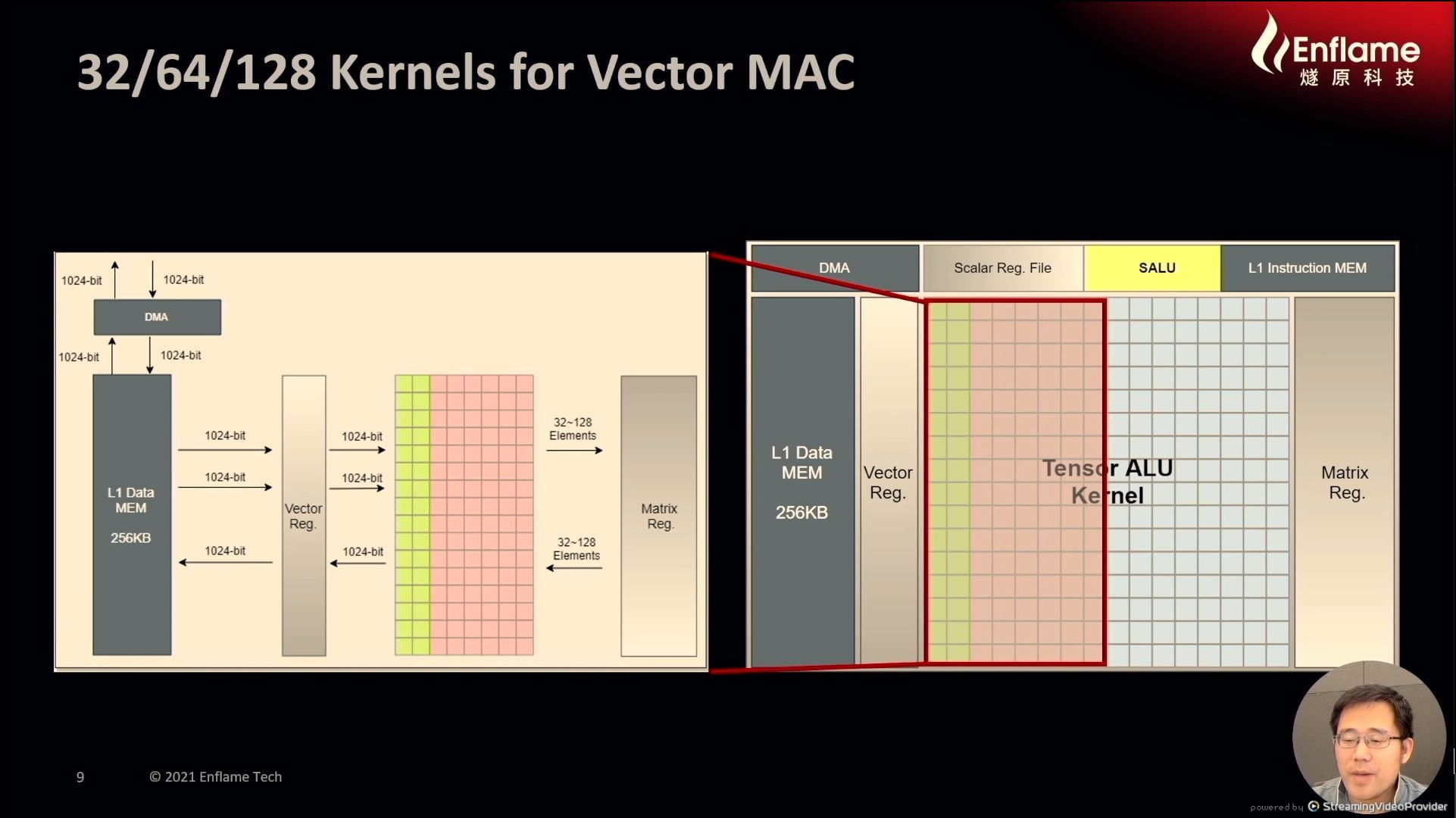
12:07PM EDT - Each kernel supports 1x-32bit MAC or 4x16-bit/8-bit MAC. All kernels do all precisions

12:08PM EDT - Introduce sparsity for power
12:08PM EDT - can fully skip instructions if zero power instruction detected
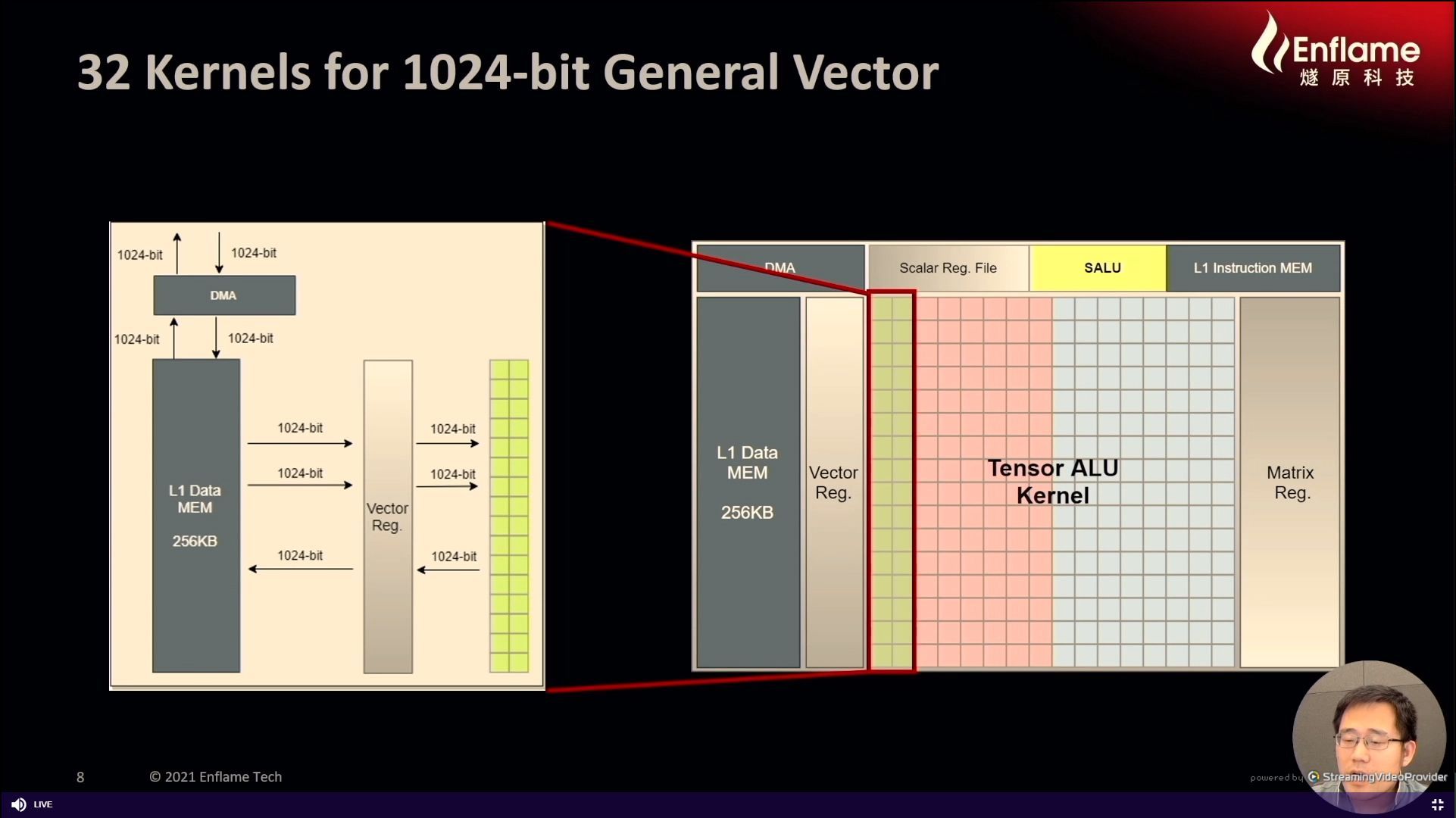
12:09PM EDT - 2 kbit per cycle for store, 1 kbit per cycle for load
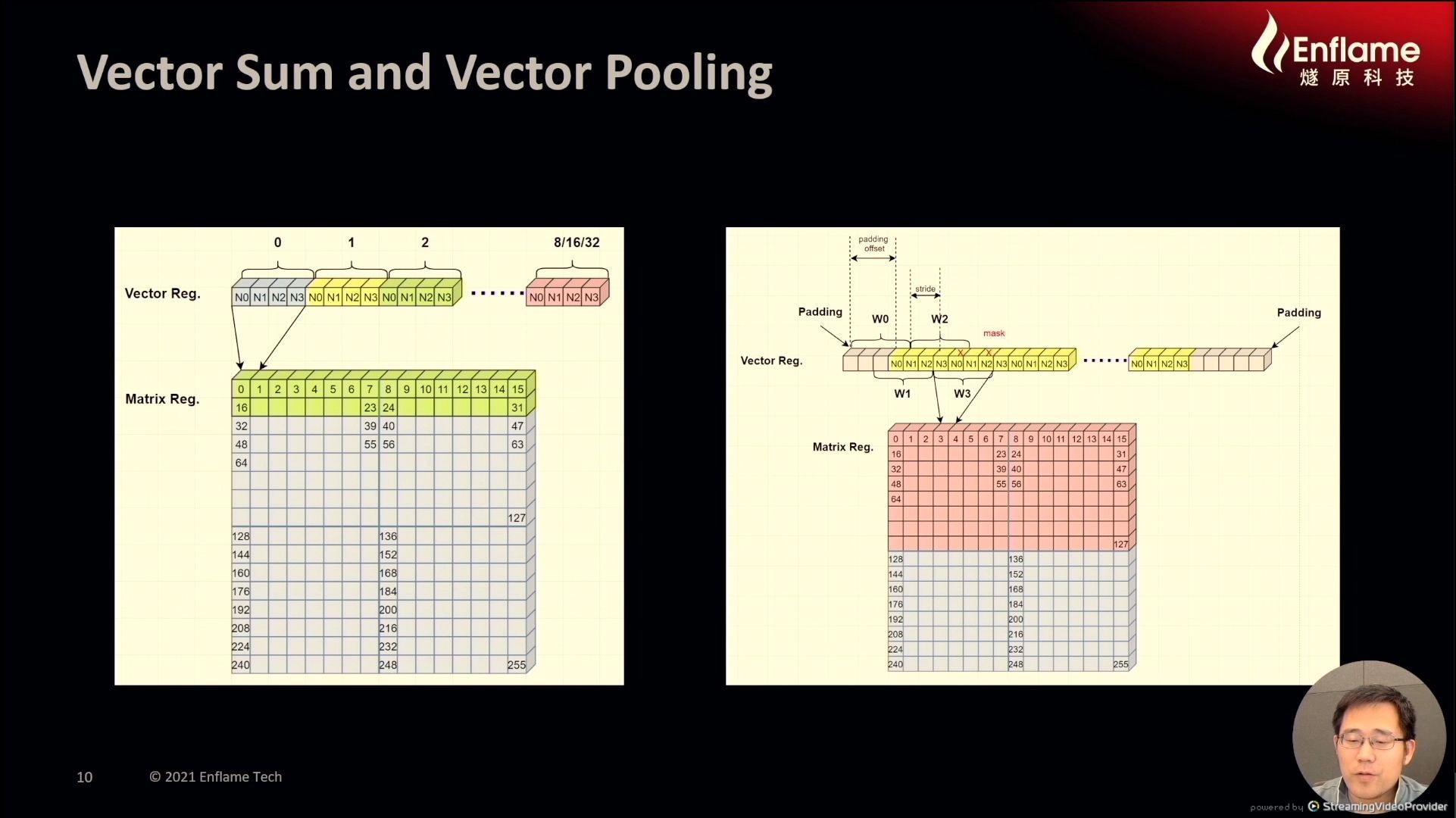
12:09PM EDT - Cector and Scalar support sum and pooling
12:10PM EDT - hardware can add padding elements to get best efficiency compined with zero power instruction detection
12:11PM EDT - 256 kernels support convolution operations


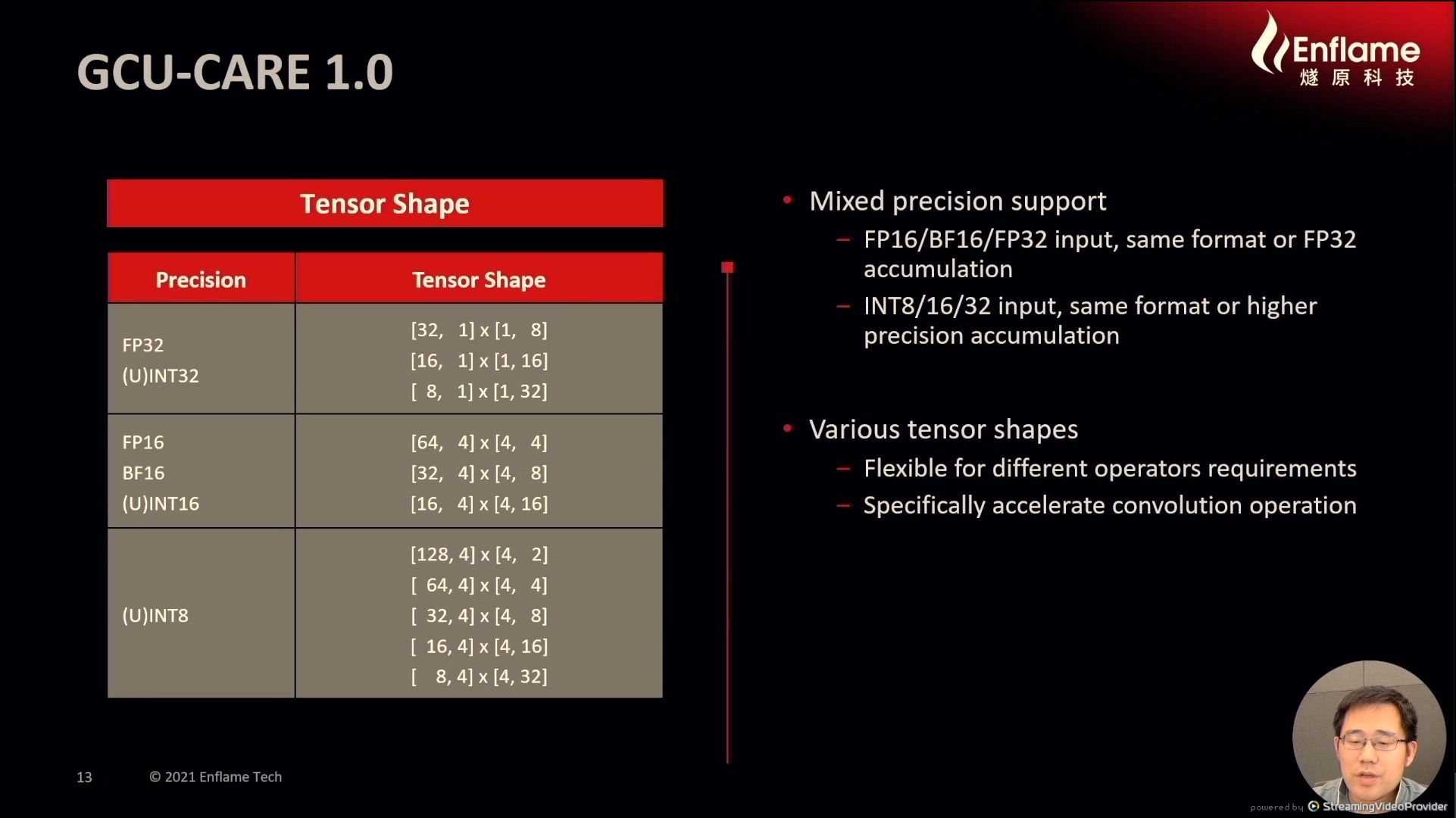
12:12PM EDT - Support various tensor shapes
12:12PM EDT - have to have it on a power of two boundary



12:13PM EDT - L0 cache with 10 TB/s bandwidth
12:13PM EDT - Async data flow and compute pipeline
12:14PM EDT - 4D tensors
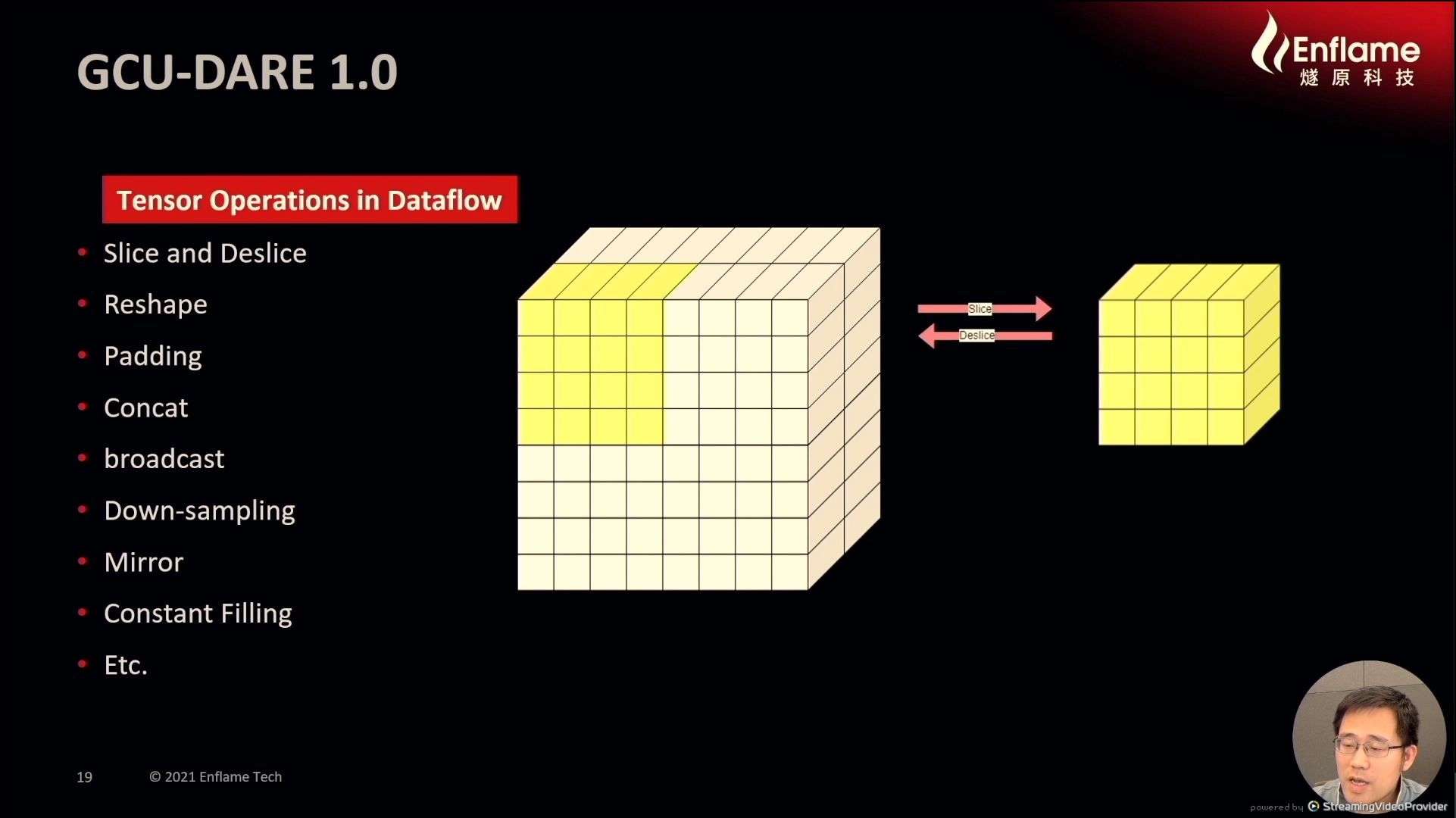
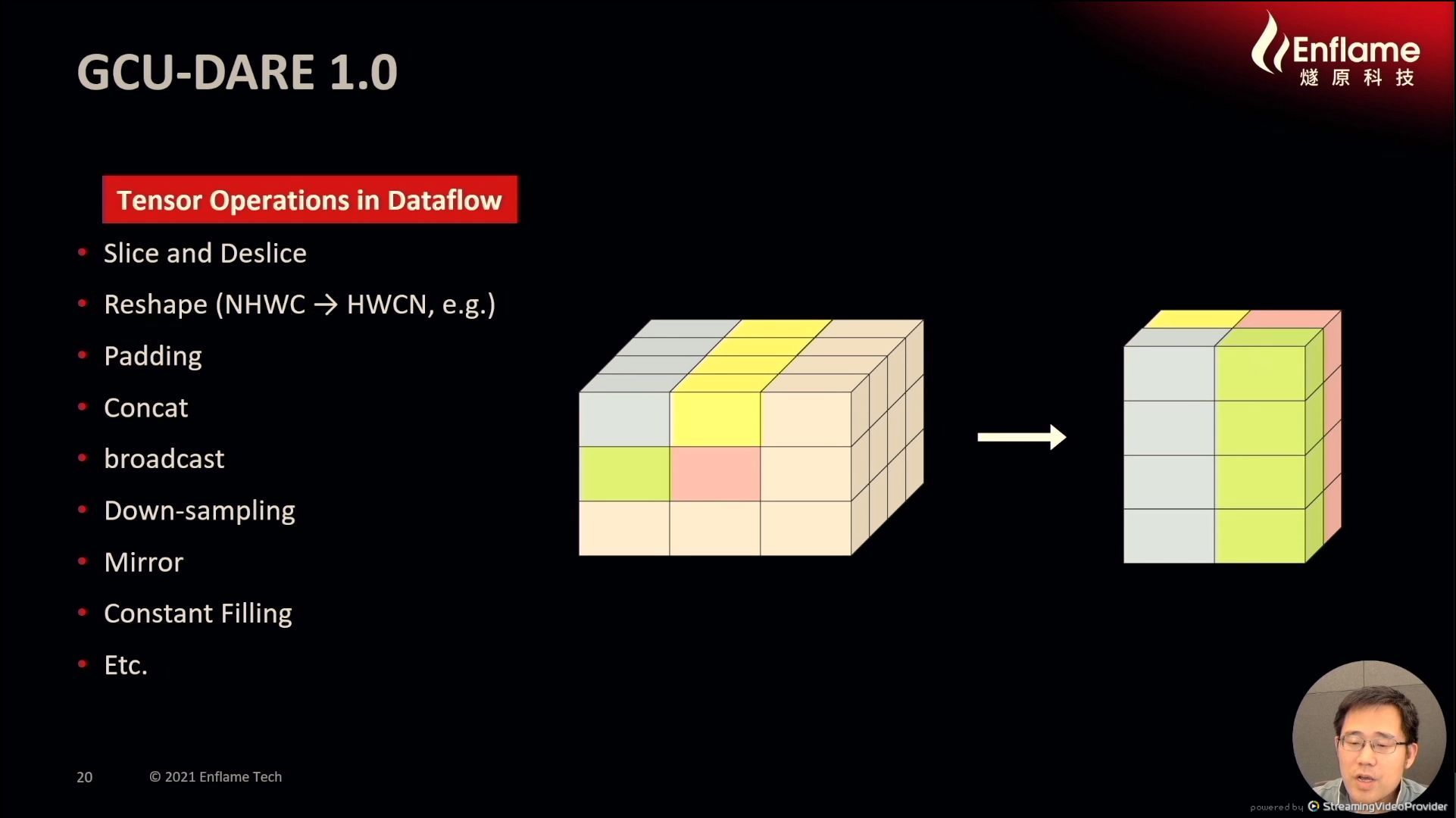
12:14PM EDT - Supports dimension reshape

12:15PM EDT - 200 GB/s bi-directional IO per card
12:15PM EDT - custom protocol with sub-microsecond latency
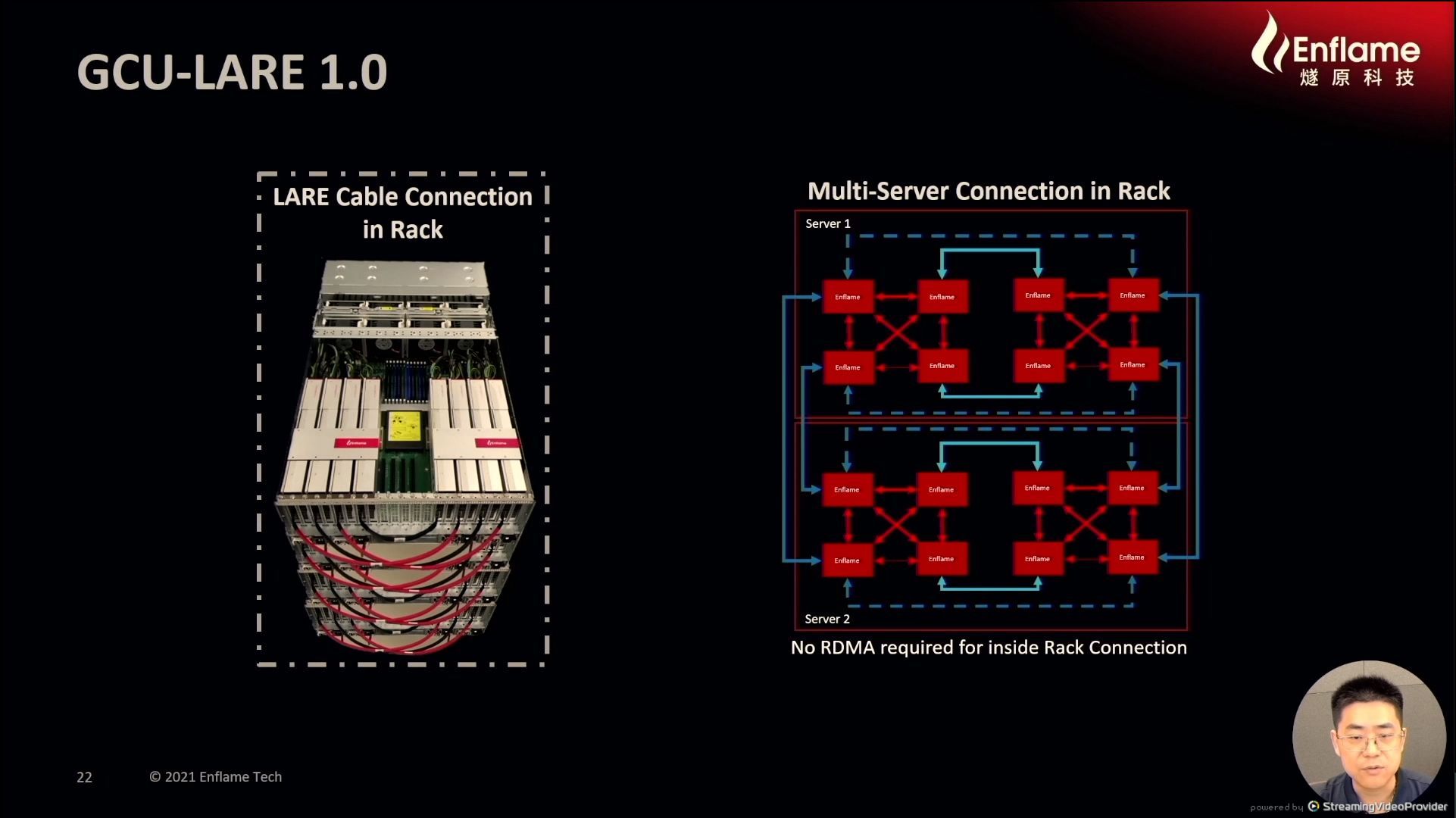
12:15PM EDT - Layer cables to racks without DMA

12:16PM EDT - AIC and OAM
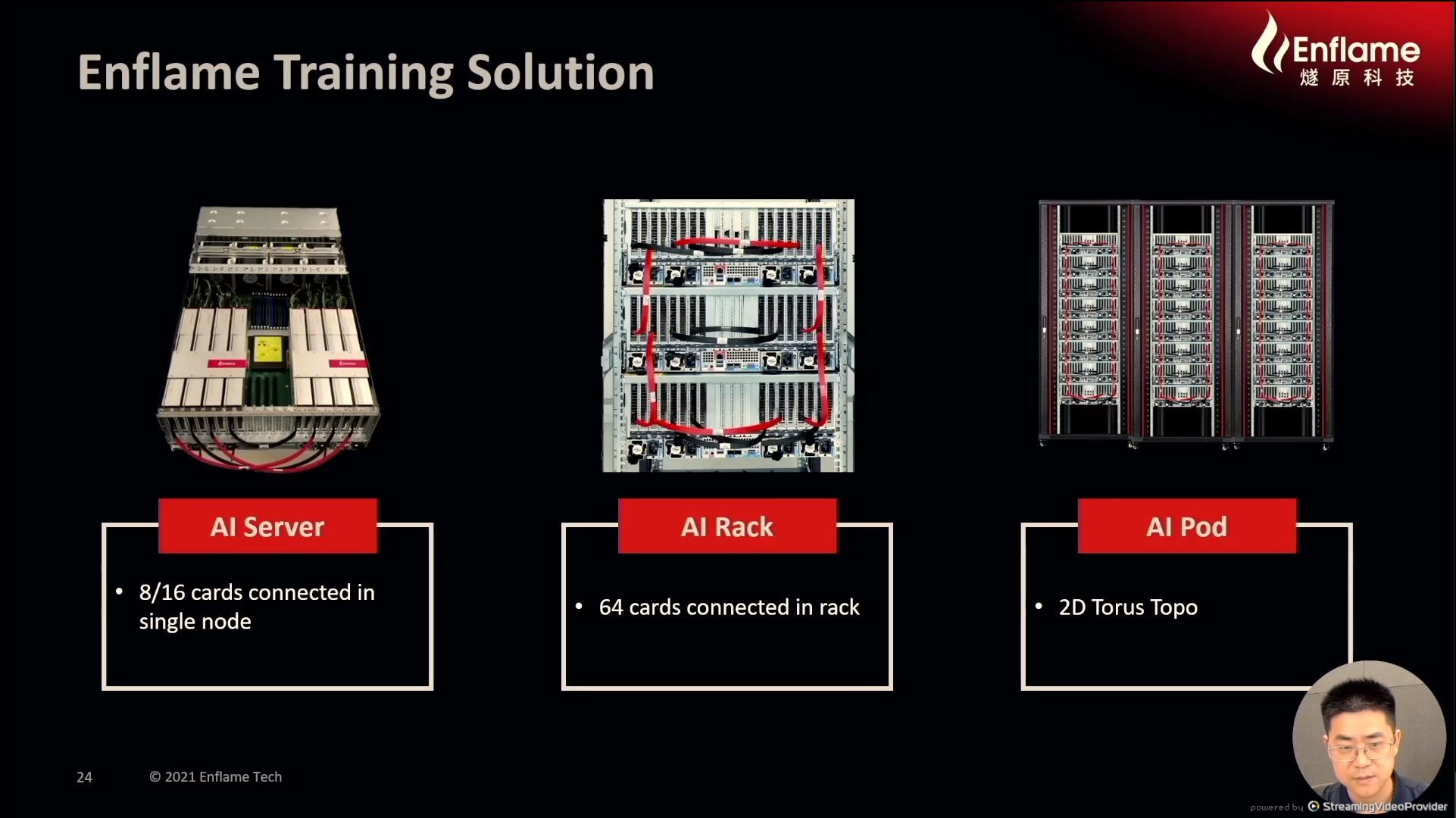
12:17PM EDT - Scale up to 2D torus pod
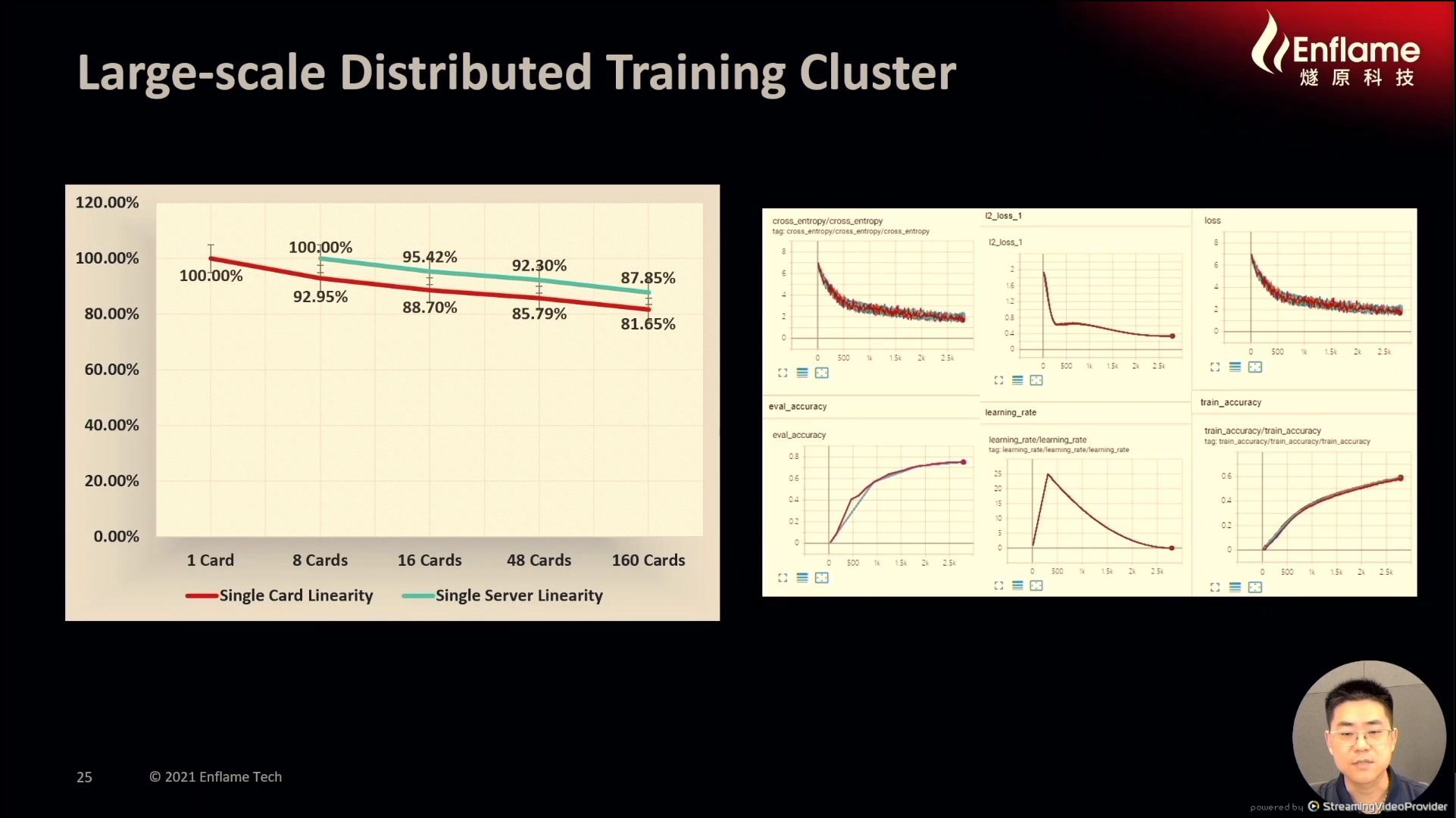
12:18PM EDT - Performance taken up to 160 card cluster
12:20PM EDT - Next product ready soon
12:20PM EDT - Q&A
12:21PM EDT - Q: Is there a training workload targeted? A: Training, supported vision, and machine language processing. First customer used MLP
12:21PM EDT - Q: Why design your own chip-to-chip protocol? Is it cache coherent A:It's not cache coherent, data sync mailbox. we wanted a lighter protocol with better latency
12:22PM EDT - Q: Sell to the west? A: Curretnly customers are Asia, but if you have interest, come to Enflame
12:22PM EDT - Next talk is Qualcomm Cloud AI 100

12:23PM EDT - 12 TOPS/watt
12:23PM EDT - high performance and efficient accelerator
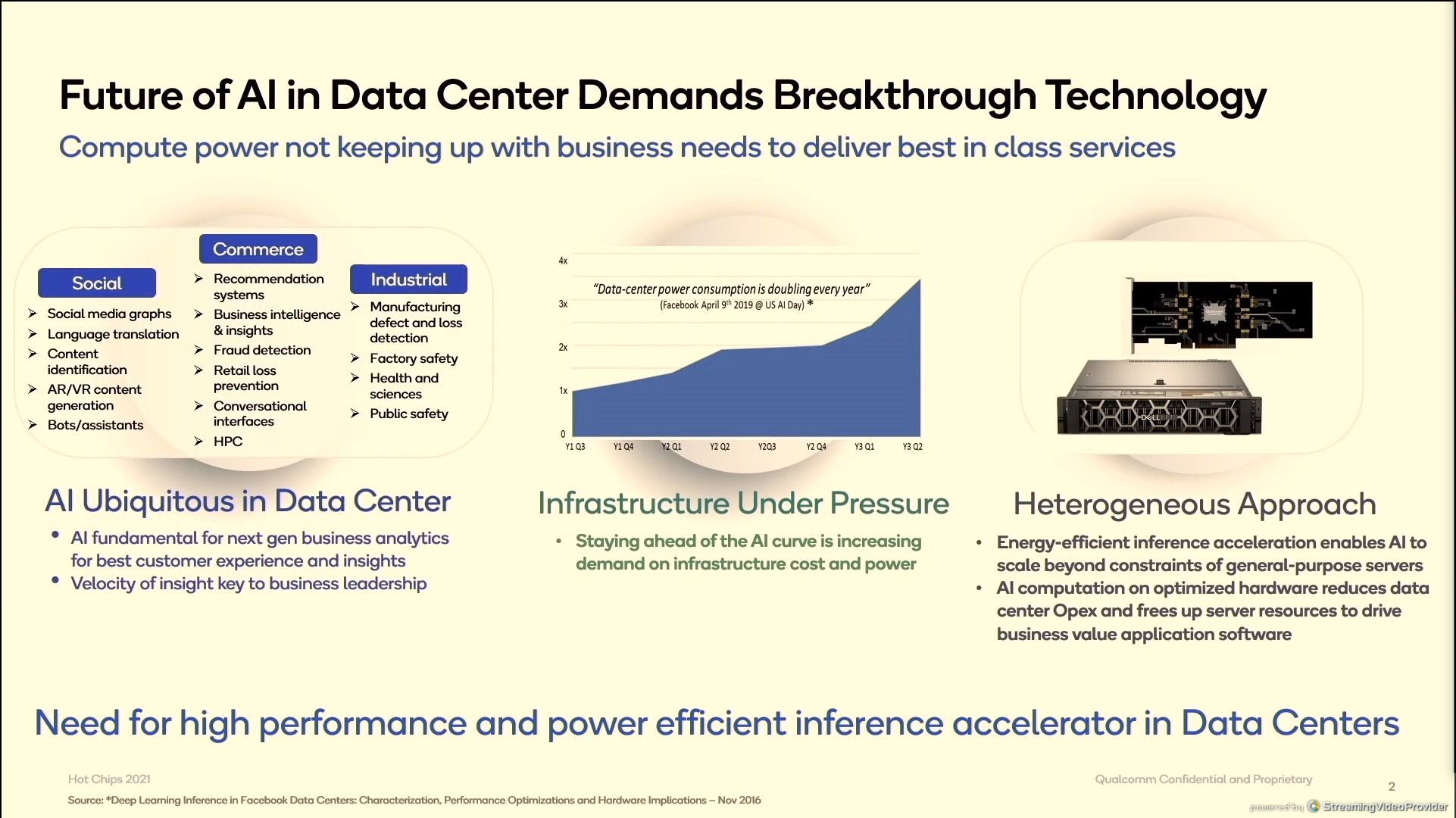
12:23PM EDT - Another intro into what's driving AI
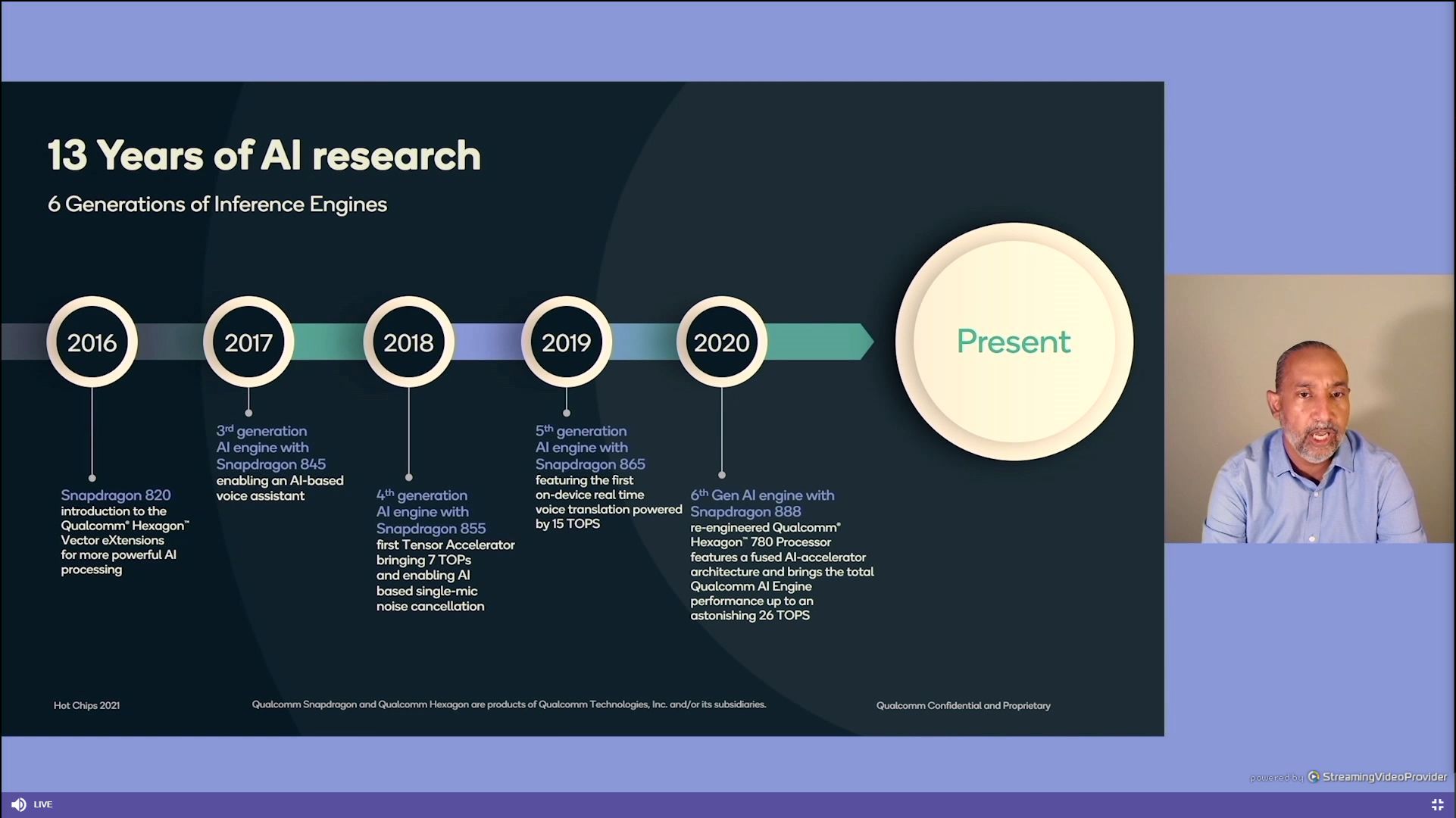
12:24PM EDT - Qualcomm at the forefront of AI research, currently on 6th gen

12:25PM EDT - two form factor - high performance in PCIe HHHL, and a more powereffcient dual M.2
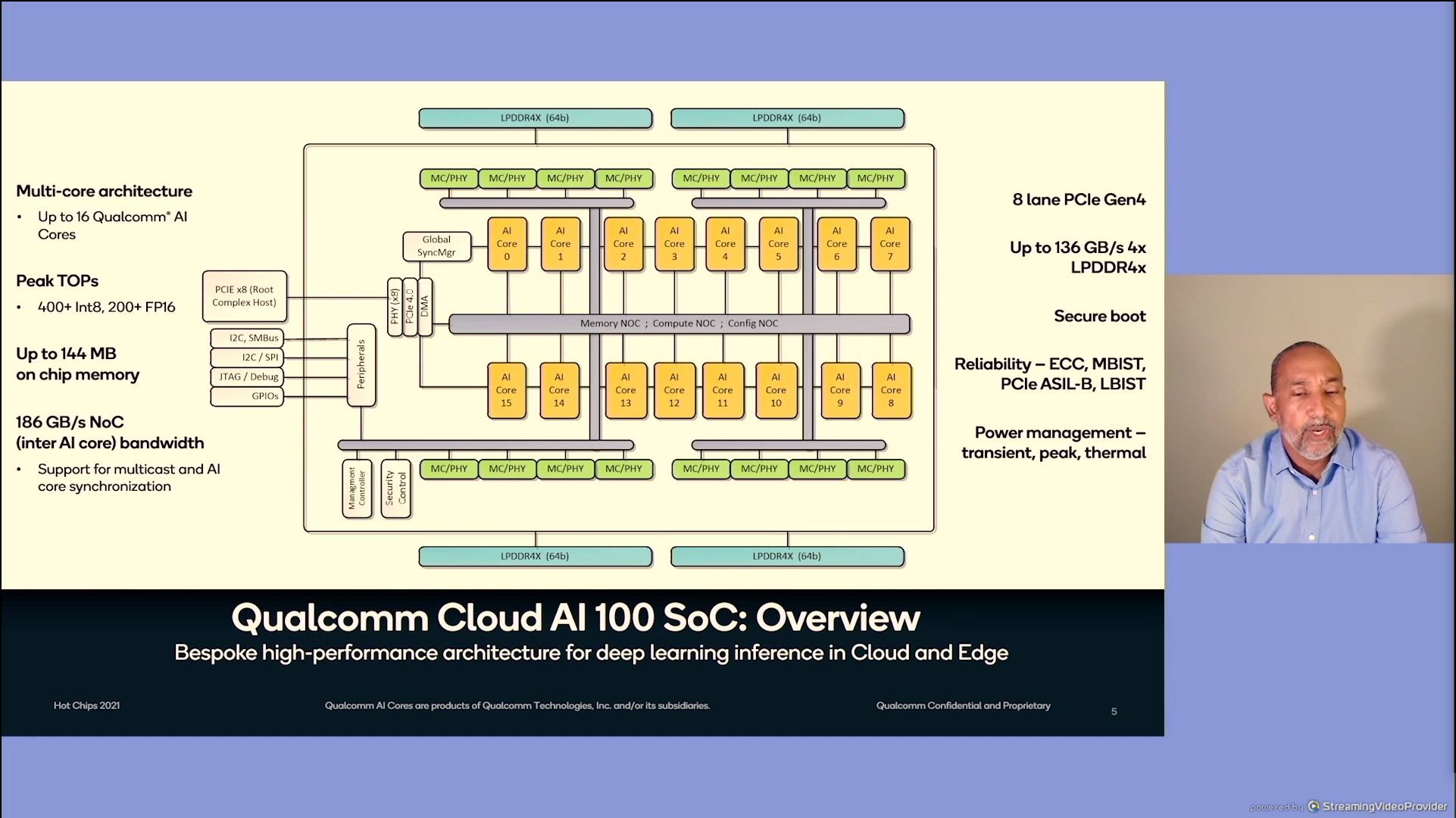
12:25PM EDT - top level SoC slide
12:26PM EDT - bespoke high performance architecture
12:26PM EDT - 400+ Int8 TOPs
12:26PM EDT - 8 lanes of PCIe 4.0
12:26PM EDT - 16 GB/sof LPDDR4
12:26PM EDT - store all the weights on the SoC with 144 MB of on-chip memory
12:27PM EDT - Dual M.2 is for power
12:27PM EDT - power management controller

12:27PM EDT - 4-way VLIW
12:27PM EDT - 1800+ instructions
12:27PM EDT - SMT scalar core
12:27PM EDT - FP32/FP16 and INT16/INT8
12:28PM EDT - 1 MB of L2 cache
12:28PM EDT - Vector unit, Tensor unit
12:28PM EDT - Vector Tightly Coupled Memory 8 MB between all units
12:28PM EDT - almost all

12:29PM EDT - Can run at various power levels
12:29PM EDT - 12W for edge, 20W for ADAS, 70W High Perf mode
12:29PM EDT - 7nm
12:30PM EDT - Tensor unit is 5x more efficient than the Vecotr unit
12:30PM EDT - 16 AI cores
12:30PM EDT - 5 TOPs/W at high performance
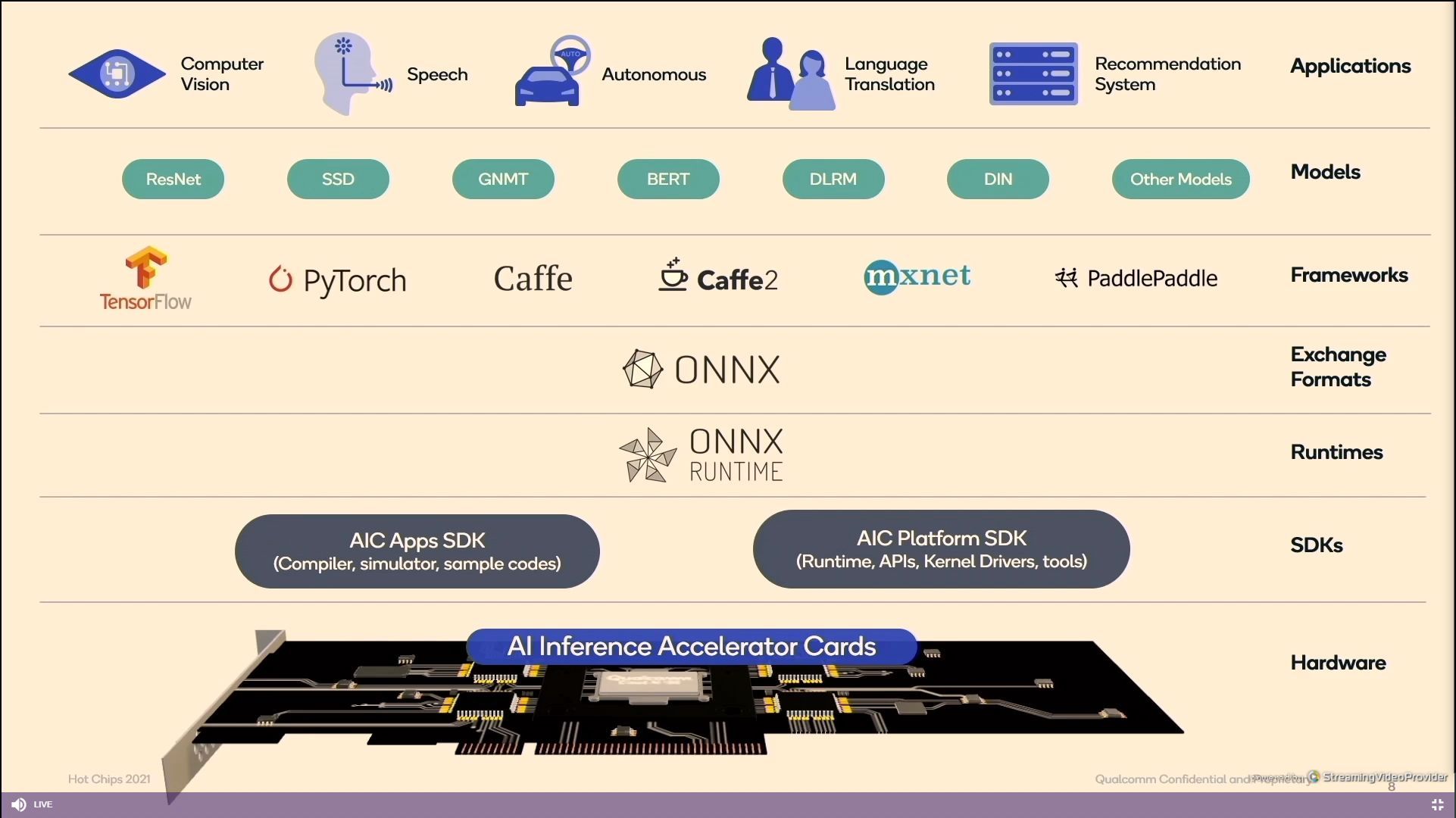
12:31PM EDT - Full stack for inference

12:33PM EDT - Compiler supports mixed precision
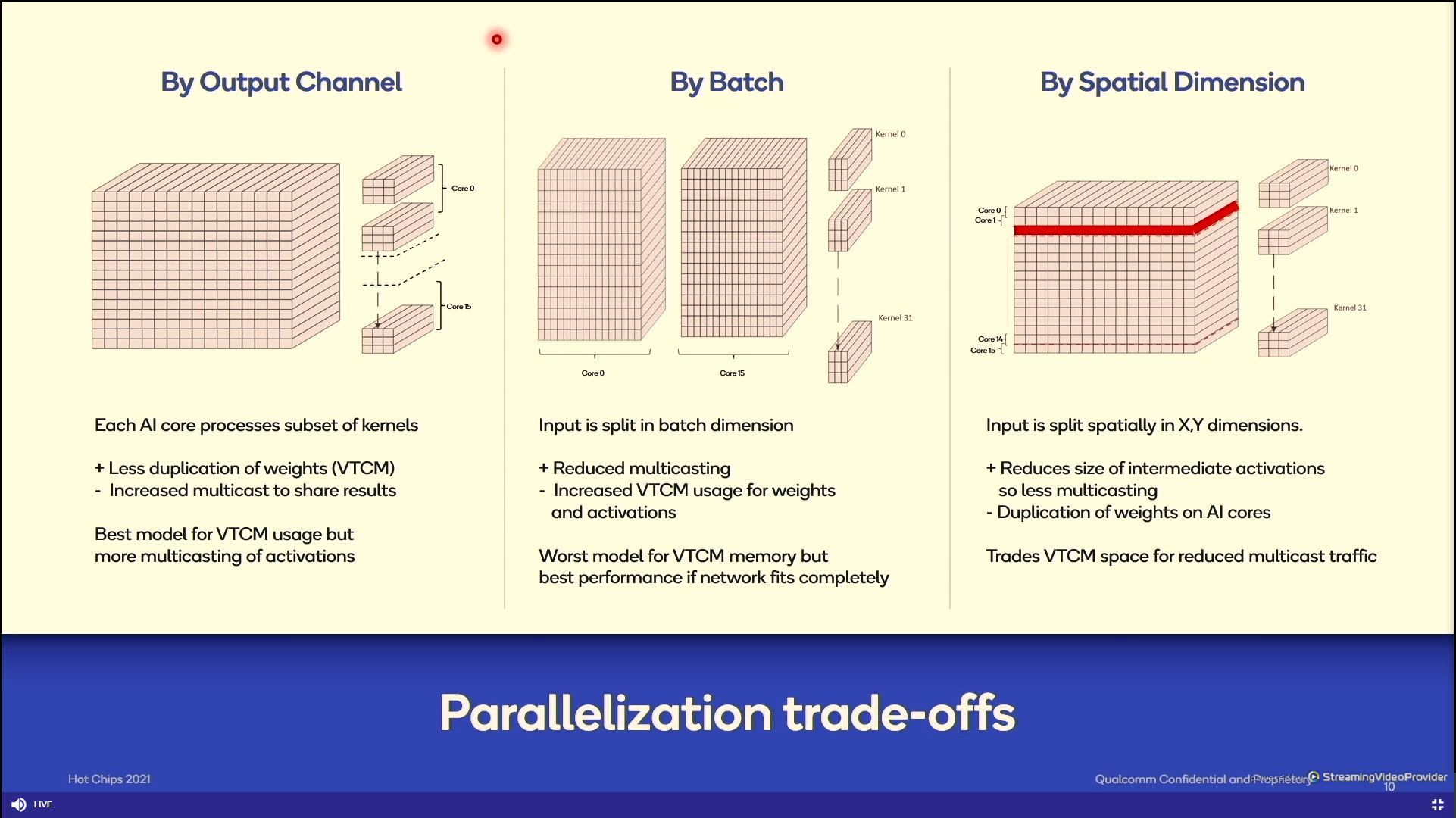

12:36PM EDT - Optimizations for low power
12:36PM EDT - minimize DDR accesses and improve performance
12:36PM EDT - Reuse data as much as you can to begin before going to get more
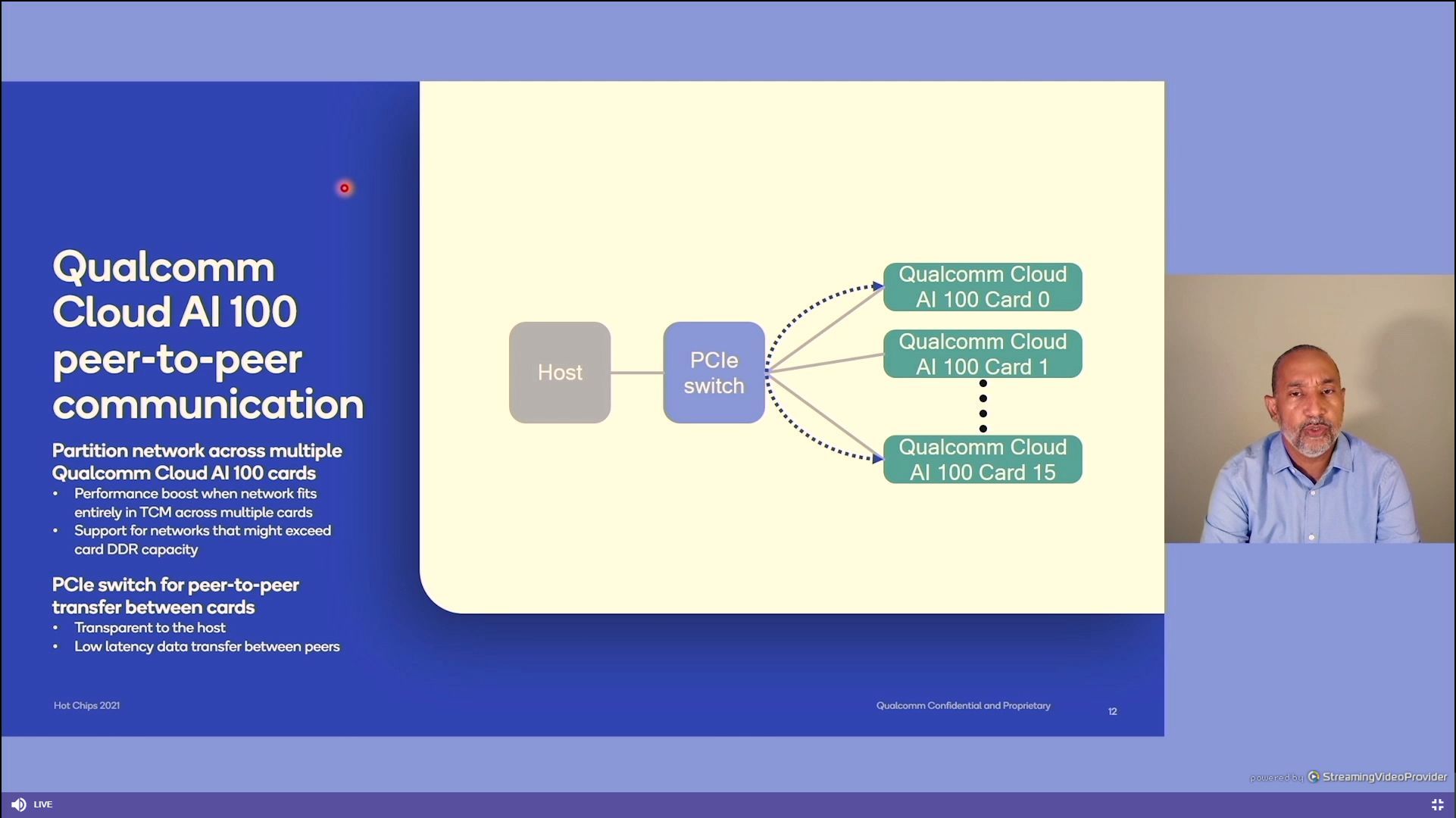
12:39PM EDT - Split a netowrk across multiple AI100 cards
12:39PM EDT - up to 16 cards per system
12:39PM EDT - PCIe switch for peer-to-peer
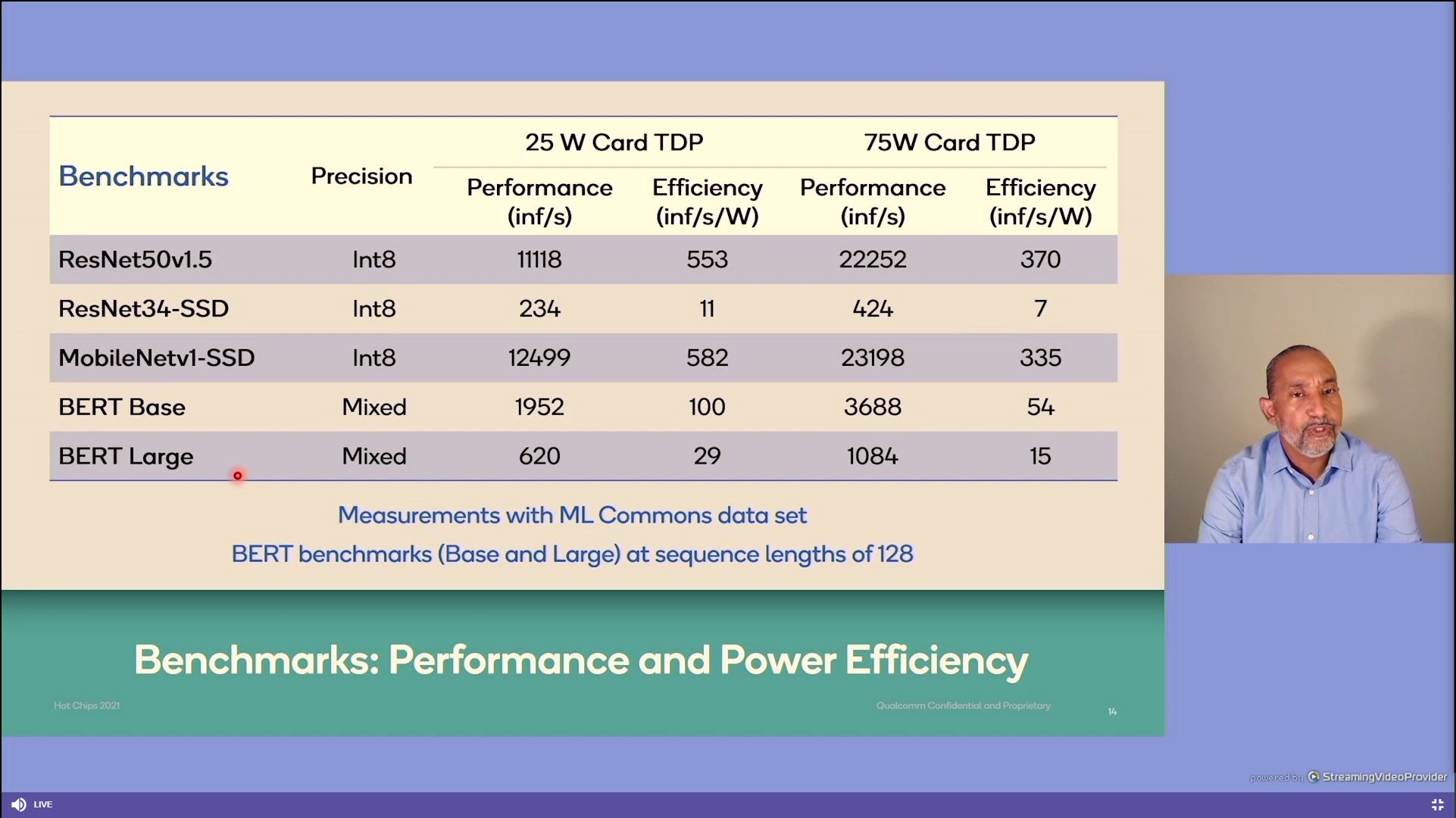
12:41PM EDT - Performance at INT8 and Mixed, all inference
12:42PM EDT - 'industry leading performance numbers'
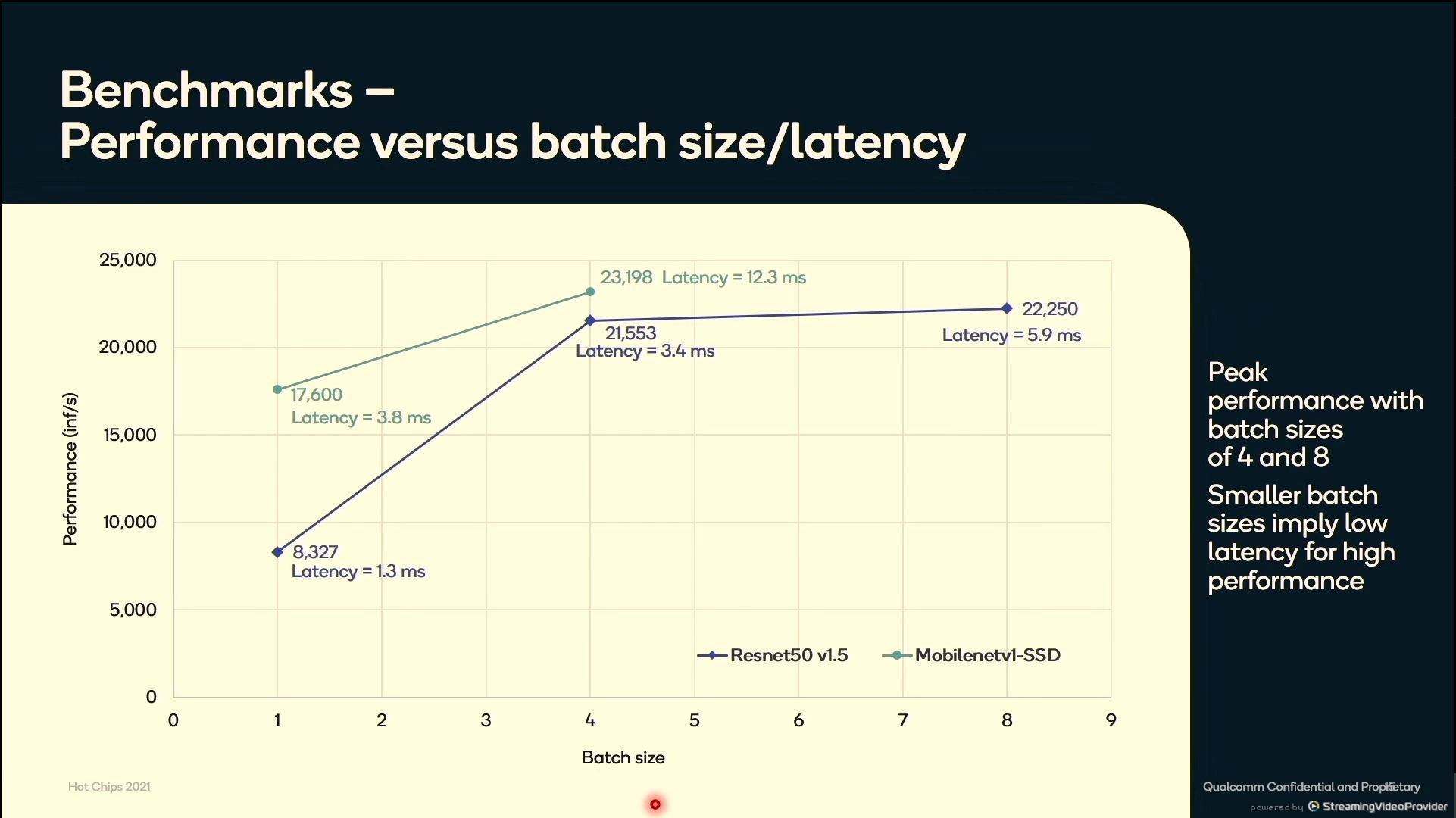
12:42PM EDT - Performance vs batch size
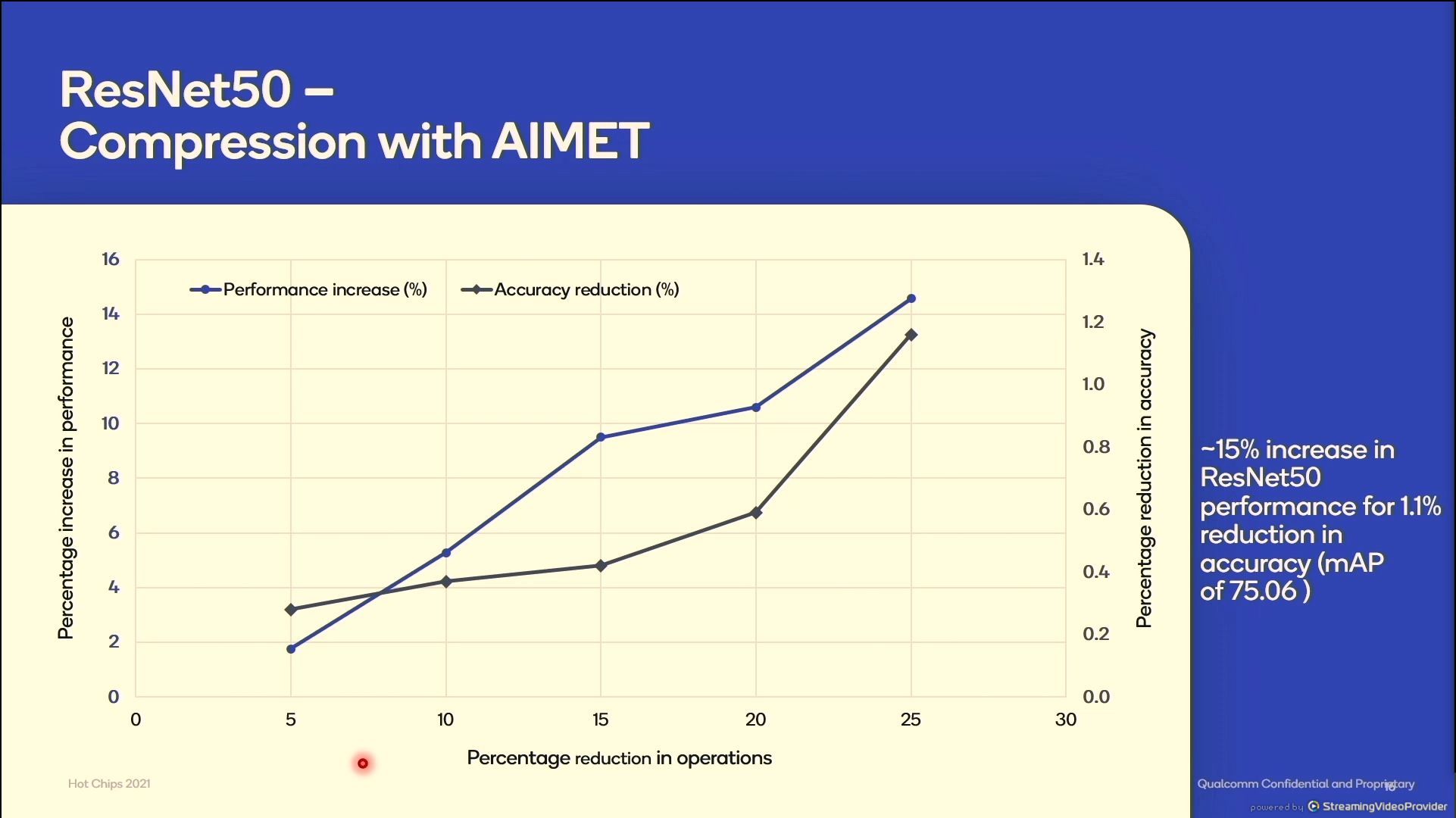
12:44PM EDT - AIMET can do inlfight compression for inference
12:44PM EDT - 15% increase in ResNET50 perf for only 1.1% reduction in accuracy

12:45PM EDT - Edge deployment vs server deployment
12:45PM EDT - DM.2e = dual M.2
12:45PM EDT - 15W TDP in that dual M.2

12:46PM EDT - Scalable solution for 5G, ADAS, infrastructure
12:46PM EDT - Q&A time
12:47PM EDT - Q: Are the power points static or automatic adjustment A: Chip has DVFS - based on power can change DVFS. For TDP, based on solution you can set TDP in firmware
12:47PM EDT - Q: 12 TOPS/W based board-level or chip-level? A: Chip
12:49PM EDT - Q: What are main drivers to achieve Tops/W A: Good building blocks - 6th gen. Been in business a long time. Been doing it in cell phones a long time, especially inference. Basic block is efficient. VLIW - compiler is doing a fair bit of lifting, keeping hardware simpler. Same process for SoC level. Not cache coherent, enabled through compiler
12:51PM EDT - Q: Tradeoffs between VLIW vs RISC A: ML fits very well on VLIW, have insights. We know how to do very efficient VLIW cores. But workload is well suited for VLIW. Did evaluation, but found this was the best way.
12:51PM EDT - Q: NOC details? Mesh, crossbar? A: Hybrid, more linear with routers
12:53PM EDT - Q: Systolic array? A: No
12:53PM EDT - Q: Scalar core is RISCV A: Proprietary VLIW
12:55PM EDT - That's a wrap








0 Comments
View All Comments